Hypernetwork の使い方
目次
- tips
Hypernetwork
Hypernetwork はモデルのウェイトを変更せずにファインチューンできる新しい(Novel [言いたいことは分かるな?])コンセプトだ。
使い方
models フォルダに hypernetwork フォルダを作成しそこに pt ファイルを配置する。setting から hypernetwork を選ぶ。
Hypernetwork の学習
Train タブで学習できる。
学習方法は Textual Inversion と同じ。
Hypernetwork の学習率は 0.000005 や 0.0000005 などの非常に小さい値にする必要がある。
学習率は 0.000005(5e-6)、ステップ数 1,500 からはじめて失敗したら、学習率 5e-7: ステップ数 10,000 を試してみる。学習率 5e-6 は学習に 30 分かからないので、失敗してもたいした損失にならない。
Modules

出典:https://i.imgur.com/aoys105.png
768 は入力を処理するモジュールだ。
320 640 1280 は中間結果を処理するモジュールだ。数字が大きいほどネットワークの中心に近い位置に配置されている。
数値は cross attention 層への入力の3次元目。
cross attention 層への入力コンテクストの形状がマッチする場合、hypernet で変換された embeddings は cross attention 層へ注入される。(プロンプトは [x, x, 768] の形状で、他の3つのサイズは畳み込み層の self-attention に関係がある)
1024 は新しい OpenCLIP を使う場合にチェックを入れる。
Move VAE and CLIP to RAM when training hypernetwork. Saves VRAM
Move VAE and CLIP to RAM when training hypernetwork. Saves VRAM は、プレビュー画像の生成が遅くなるがメモリ使用量を節約できる。場所は Setting タブ。
Hypernetwork layer structure
Hypernetwork の全結合層の構造を指定する。デフォルトは 1, 2, 1。大量のデータセットで学習させる場合、より深い層(たとえば、1,2,2,1 や 1,2,4,2,1)にするとより複雑な表現ができるようになる。ただし学習に時間がかかり、学習時に使用するメモリも増え、pt ファイルも巨大になる。
Select activation function of hypernetwork
全結合層を非線形化するための活性化関数を指定する。
- Linear:活性化関数なし
- relu:よく使われている活性化関数。学習時に大きく負側に重みが更新された場合、ReLU関数で活性化する事がなくなる dying ReLU 問題がある
- leakylelu:マイナス方向の情報も伝達する relu。wikipedia によると「2013年にmax(0.01x, x) がLReL (leaky rectified linear) と命名された。ただし、命名者はこの活性化関数を使う意味はなかったと報告している[5]。」
[活性化関数]Leaky ReLU(Leaky Rectified Linear Unit)/LReLUとは?では「2013年の論文「Rectifier Nonlinearities Improve Neural Network Acoustic Models」によると、音声認識タスクにおいてReLUよりも良い精度になったことが示されている。」 - elu:シンプルな全結合層では効果が実感できないかもいしれない。「arXiv:1511.07289 [cs.LG]」によると、画像認識タスクにおいてReLU/Leaky ReLU/PReLUよりも良い精度になったことが示されている。
- swish:relu より高性能だが relu より計算が遅い
- mish:swish より高性能だが swish より計算が遅い
AUTOMATIC1111 上での速度
AUTOMATIC1111 の実装ではReLU と Mish の速度は変わらない(Mish の方がわずかに遅い)。
検証条件
- ハードウェア:RTX 3050
- Layer structure:1, 2, 1
- Layer weights initialization:normal
- Add layer normalization:オフ
- Use dropout:オフ
- 学習速度:1.2 it/s
The Dying ReLU Problem, Clearly Explained
ReLU はマイナスの情報を通さないので、マイナスの情報が多い場合、学習が全く進まなくなる。これを Dying ReLU と呼ぶ。Dying ReLU は以下の状況で起こりやすい。
- 学習率が高い
以下の式を見ればわかるように、高い学習率は新しいウェイトがマイナスになりやすい。新しいウェイトがマイナスになるとそのウェイトは0になり、ニューロンが死んでしまう。

単純化された学習の数式
- マイナスのバイアスがある
対策
- 学習率を下げる
- マイナスの情報も伝える活性化関数(leakyrelu, elu, swish, mish)を使う
- He の初期値などの適切な初期化処理をする
- Batch Normalization を使う
活性化関数に関するリンク
活性化関数のまとめ(ReLU, leaky ReLU, PReLU, ELU, sigmoid, TanH, softmax, GELU, SELU)
【活性化関数】MishってSwishより精度良いの?
MishはReLUに比べて約3倍遅い。CUDA-baseのimplementationしたMish-CUDAはReLUとほぼ同じ速度になっている。
ReLU6 とは何者なのか?
ReLU6 は ReLU の上限を6にしたもの。ReLU に上限があると、8bit 量子化するときに効率的に情報を利用できる。
Add layer normalization
これを有効にすると、全結合層の各レイヤーの後に layer normalization が挿入される。layer normalization は過学習や発散が起こりづらくなる。
Batch Normalization の理解
Batch Normalization の効果
- 学習を速く進行させることができる(学習係数を大きくすることができる)
- 初期値にそれほど依存しない(初期値に対してそこまで神経質にならなくてよい)
- 過学習を抑制する(Dropout などの必要性を減らす)
Use dropout
Dropoutはニューロンをランダムに消去しながら学習する手法。過学習を抑制する。
Overwrite Old Hypernetwork
同名の古い Hypernetwork を削除して新規に作成する。
使わない方がいい活性化関数
Activation and loss functions (part 1)
- SeLU:特殊な初期化関数が必要で、その初期化関数が未実装
- CeLU:カスタム可能な ELU。肝心のハイパーパラメータにアクセスできないので ELU と同じ
- softmax:多クラス分類の出力層に使うように設計されている
- softmax2d:2次元画像に適用できる softmax
- softmin:多クラス分類の出力層に使うように設計されている。softmax関数の逆で、小さい値の確率が大きくなる
普通は使わない活性化関数
- tanhshrink:潜在変数の値を計算するためのスパース符号化で使う
- softshrink:スパース符号化で使う
- hardshrink:スパース符号化で使う
- logsigmoid:損失関数として使う
- logsoftmax:損失関数として使う
活性化関数ガイド
Layer weights initialization
Normal
0を平均とした正規分布のノイズで初期化する。学習する内容が少ない場合に適している。画風を大きく変化させるような場合には、学習に時間がかかる。
Kaiming
ReLU 系で使われる初期化処理。
Xavier
0を中心としたノイズで初期化する。Sigmoid と Tanh で使われる初期化処理。
活性化関数
活性化関数には以下の欠点を持つものがある。
- 勾配消失(V):活性化関数の1次導関数の値が小さいと学習内容が消失してしまう。たとえばシグモイド関数の1次導関数の最大値は 0.25 だ。そうすると層が深くなると学習内容がどんどん小さくなってしまう
- 発散(E):ニューロンのウェイトが無限大になりノイズを生成するようになる
- ニューロン死(D):無意味な値をとりそこから抜け出せなくなる。局所的最適解とは違う事に注意
活性化関数の後ろに V, E, D を付けて、どの欠点があるかを示す。特殊用途の活性化関数は紹介しない。
- ReLU (ED)
有名でよく使われている活性化関数。ReLU + Kaiming + Layer Normalization がセット。ReLU と Normal とを同時に使うべきではない。そうすると、初期化時点で半数のニューロンが死んでしまう。 - ELU(E, V[負領域])
Dying ReLU を避けられる。任意の関数で初期化できる。 - LeakyReLU, RReLU (E)
Dying ReLU を避けられ、ELU と違い計算が早い。RReLU は負の領域がランダム化されている。ノイズが含まれているので写真に向いている。任意の関数で初期化できる。 - ReLU6 (D)
上限が6に制限されている ReLU。初期化方法は ReLU と同じ。 - SeLU
使うべきではない。特殊な初期化関数が必要で、その初期化関数が未実装。 - CeLU
使わなくていい。カスタム可能な ELU。肝心のカスタム変数にアクセスできないので ELU と同じ。 - GeLU, Swith, Mish (EV)
Dying Relu を避けられる。swish は実際は hardswish。hardswish は swish のスマホ最適化が適用されたバージョン。swish を使いたいときは SILU を使う。 - Tanh, Sigmoid, Softsign (V)
1次導関数のとりうる値の範囲が決まっており、発散が発生しない。ただし勾配消失が起こる。normal か xavier で初期化する。xavier の方が学習が早い。 - hard-系
勾配消失の代わりにニューロン死が起こるようになっている。
[Diffusion Model] Hypernetworksのレイヤー構造を変えた際の変化を比較する
Hypernetwork training #2284
学習に使う画像は 20 枚前後で、早ければ 3,000 ステップ、遅くても 10,000 ステップ未満で学習が終わる。
画風を学習させる場合は左右反転や回転を使うと学習画像を水増しできる。
Hypernetwork Style Training, a tiny guide #2670
準備
- 量より質。画像は 20 枚前後でよい
- 画像サイズは 512x512 がよい
- ラベルの作成に BLIP や danbooru を使う
- すべてのラベルをチェックする
学習
- Learning Rate: 5e-5:100, 5e-6:1500, 5e-7:10000, 5e-8:20000
| Learning Rate | Steps |
|---|---|
| 0.00005 | 100 |
| 0.000005 | 1,500 |
| 0.0000005 | 10,000 |
| 0.00000005 | 20,000 |
- プロンプトテンプレートに [filewords] だけが入ったものを使う
- ステップ数は 20,000 以下で十分。10,000 以下のステップで大方の学習は終了するが、ディティールが重要ならば 10,000~20,000 ステップまで回す価値がある
Hypernetwork training for dummies
よいデータを集める
ファインチューニングは学習データの質がすべてだ。
キャラを学習させたい場合は、背景を除去した方がいい。テキストや台詞、エフェクトもない方がいい。キャラを学習させる場合でも画風を一致させた方がいい。
よいデータを作るためには加工が必要だ。
- 背景を白にしたり、テキストやエフェクトなど余計な情報を除去する
- アスペクト比が1:1になるよう画像をクロップする
- 解像度が低い場合はアップスケールする
レイヤー
- layer structure はデフォルト(1, 2, 1)でいい
- Activation Function も Linear でいい
- 過学習や発散を防ぐのに dropout は有効
- normalization layer はオフ(normalization layer をオンにして学習を成功させるのが難しい)
Danbooru タグを使う場合の注意点
丸括弧() や角括弧[] で語が強調されないようにエスケープ(\(\) \[\])する必要がある。
アンダーバーは半角スペースに置き換える。
Hypernetwork を外す
現在適用されている Hypernetwork は学習に影響を与える。
style_filewords.txt
style_filewords.txt は [filewords] だけ書かれたもので十分だ。
style_filewords.txt
learning rate
あまりに早くノイズ画像を出力する場合は、learning rate に 0 を追加(つまり小さく)して学習をやり直す。
clipskip
結果が芳しくない場合は Stop At last layers of CLIP model を1(つまり無効)にして検証してみる。
例1
2022/11/27 のアップデートで Hypernetwork の性能が上がり、学習画像を再現できるレベルになった。
環境
- ハードウェア:RTX 3050 8GB
- 学習に使ったモデル:trinart_derrida_characters_v2_stable_diffusion
- 学習画像:背景を白にしたドールズフロントラインの AA12 の画像6枚:顔アップ3枚、ウェスト+顔3枚
- 学習画像サイズ:512x512
- タグ:Deepdanbooru の出力を手動修正+aa12 を追加
- 学習率: 0.0005 (5e-4)
- Layer Structure:1, 2, 1
- Activation Function:mish
- Layer weights initialization:XavierUniform
- Add layer normalization オン
- latent sampling method:deterministic
- CLIP Skip:2
- ステップ数:5,000
- 学習速度:1.15 it/s
- 学習にかかった時間:1時間 15 分程度
出力例
- モデル:trinart_derrida_characters_v2_stable_diffusion
- ネガティブプロンプト:lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry

prompt
(masterpiece:1.3), best quality, 1girl, solo, black headwear, hat, bangs, blue eyes, purple star hair ornament, ahoge, choker, aa12

prompt
1girl, solo, black headwear, hat, bangs, blue eyes, purple star hair ornament, ahoge, choker, aa12 wears bikini (in the beach:1.3), cowboy shot

1girl, solo, black headwear, bangs, blue eyes, purple star hair ornament, ahoge, choker, aa12 wears nun (in the church:1.3), cowboy shot
hypernetwork.py
レイヤー構造
modules/hypernetwork.py のHypernetworkModule の __init__ でレイヤー構造を作成している。2022 年 11 月現在の実装を示す。最終層は活性化関数と Dropout がない。
構造例
- Layer structure:1, 2, 1
- Layer Normalization オン
- Dropout オン
作成されるネットワーク
- 全結合層(入力 768, 出力 1,536)
- 活性化関数
- Layer Normalization
- Dropout
- 全結合層(入力 1,536, 出力 1,536)
- 活性化関数
- Layer Normalization
- Dropout
- 全結合層(入力 1,536, 出力 768)
- Layer Normalization
普通は Layer Normalization の後に活性化関数を入れるが、この順番はあまり重要ではない。
オプティマイザ
AdamW を使用している。
optimizer = torch.optim.AdamW(weights, lr=scheduler.learn_rate)
hypernetwork の注入先
hypernetwork は1モジュールあたり2つ作成される。4つのモジュール(768, 320, 640, 1280)にチェックを入れると合計8つの hypernetwork が作成される。
for size in enable_sizes or []:
self.layers[size] = (
HypernetworkModule(size, None, self.layer_structure, self.activation_func, self.weight_init, self.add_layer_norm, self.use_dropout, self.activate_output, last_layer_dropout=self.last_layer_dropout),
HypernetworkModule(size, None, self.layer_structure, self.activation_func, self.weight_init, self.add_layer_norm, self.use_dropout, self.activate_output, last_layer_dropout=self.last_layer_dropout),
)
hypernetwork の出力は Cross Attention を使って U-Net に注入される。U-Net 内の Cross Attension の K と V とに注入されるのでモジュール1つあたり2つの hypernetwork が作成される。実装は attention_CrossAttention_forward を参照。
Hypernetwork-MonkeyPatch-Extension
Cosine Annealing や可変解像度の学習画像が使える Extention。
インストール
git clone https://github.com/aria1th/Hypernetwork-MonkeyPatch-Extension extensions/Hypernetwork-MonkeyPatch-Extension
可変解像度学習
MonkeyPath は画像サイズを統一する必要がない。UI 上の解像度は最大解像度で、この解像度を超える画像はアスペクト比を維持したまま縮小される。マルチアスペクトの学習はbatch sizeは1にする必要がある。
Cosine Annealing
局所的最適解から抜け出すには定期的に学習率を上げたり下げたりするとよい。Cosine Annealing はこれを自動的に実行してくれる。
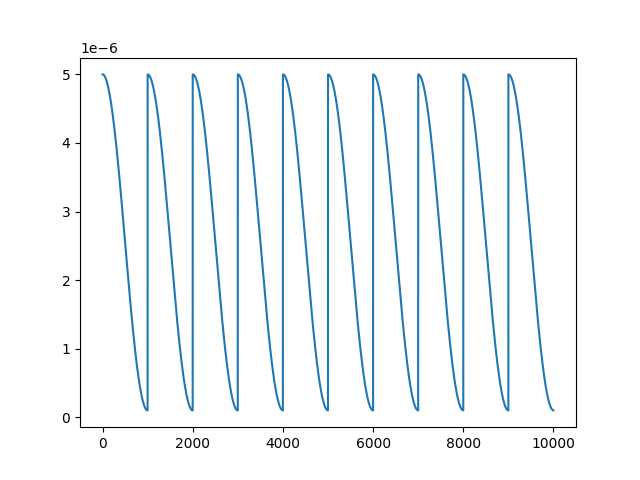
デフォルト設定での Cosine Annealing の学習率の変化
Cosine Annealing は平均学習率で考えた方がいい。最大学習率と最低学習率の平均がいつもの学習率になるように調整する。
パラメータ
- Epoch for cycle:学習率のリセット周期
- Epoch multiplier per cycles:学習率のリセットごとにリセット周期にこの値を掛けて、リセット周期を伸ばす。1以上の整数しか設定できない
- Warmup step per cycle:Warmup に使うステップ数
- Minimum learning rate for beta scheduler:学習率の最低値
- Separate learning rate decay for ExponentialLR:ステップごとの減衰率
Warmup
外部リンク
Implement correct training method, Gradient Accumulation, and more #4680
Gradient accumulation, autocast fix, new latent sampling method, etc #4886
Hypernetwork の複数適用
models/hypernetwork に .hns ファイルを配置することで使える。.hns ファイルの中身は hypernetwork の結果のブレンド方法が書かれたテキストファイルだ。
Hypernetwork の適用方法には2種類ある。直列と並列だ。直列は embedding を hypernetwork1 で変換し、その結果を hypernetwork2 で変換する。並列は embedding を hypernetwork1 と hypernetwork2 とで変換した結果をブレンドする。
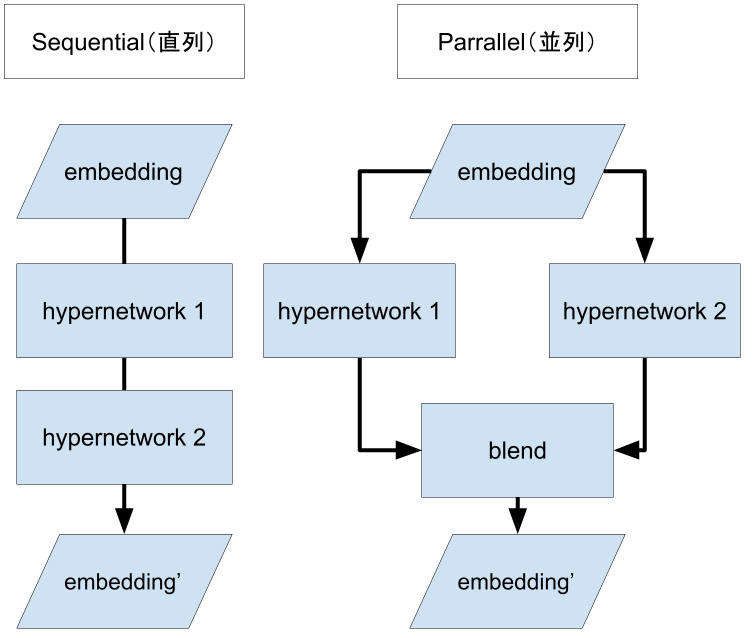
直列と並列の概念図
.hns は python の表記法を使う。おそらく自分でパーサーをゼロから書くのが面倒だったのだろう。以下の例では h1, h2, h3 は hypernetwork 名とする。
hypernet の強さの調整
- ("h1", 0.1):h1 の強さを 0.1 にする
直列適用
- ["h1", "h2"]:h1 を適用した後 h2 を適用する
- ["h1", "h2", "h3"]:h1, h2, h3 をそれぞれ順番に適用する
並列適用
- {"h1", "h2", "h3"}:embedding を h1, h2, h3 で変換し、結果を平均する。{"h1":0.3333, "h2":0.3333, "h3":0.3333} と同じ
- {"h1":0.1, "h2":0.2, "h3":0.7}:embedding をそれぞれ指定した強さで変換し結果を足し合わせる
例
[{('a-1', 0.45):0.5, ('ta', 0.45):0.5}, 'p']
上記の例では、強さ 0.45 の a-1 と強さ 0.45 の ta とを並列適用した後で p を適用している。
Multiple Hypernetworks
Hypernetwork を複数適用する。