LoRA の学習方法
- 画像加工
- トリミング
- 背景除去
- 白背景
- 物体検出
- Aspect Ratio Bucketing
- キャプション・設定ファイル
- キャプション方式
- タグ編集アプリ
- キャプションファイルの先頭にタグを追記するコマンド
- 設定ファイルの class_tokens
- トリガーワード
- 画風学習のキャプションファイル
- キャラ学習のキャプションファイル
- keep_tokens
- VRAM 削減
- fp8_base
- mixed_precision
- xformers
- gradient_checkpointing gradient_accumulation_steps
- データの水増し
- 過学習防止
- 学習
- fp16 と bf16
- サンプルの出力
- 学習方式の選択
- リピート数とエポック数
- network_dim
- dim_from_weights network_weights
- network_alpha base_weights base_weights_multiplier
- min_snr_gamma
- debiased_estimation
- zero_terminal_snr
- v_parameterization
- noise_offset
- 学習率
- スケジューラ
- オプティマイザ
- 階層別学習率
- 高速化
- 省メモリ設定
- logging_dir
- SDXL
- 検証
- 学習の再開
- メタデータの閲覧
概要
ローカル環境で LoRA を作る時代は終わりつつある。モデルサイズが巨大化し、LoRA の作成に A6000 や RTX PRO 6000 のような業務用の GPU が必要になる。そこで ai-toolkit のようなクラウドでも学習が可能なツールがシェアを増やしている。
逆に生成はローカルで可能だ。モデルの量子化のノウハウが蓄積され、4bit 量子化で劣化を抑えてモデルサイズを削減したり、Block swap で遅いが巨大モデルでも実行はできる状況にある。VRAM も 16GB あれば大抵のモデルで、3K の解像度の画像を生成できる。
教師画像
このページには大量の情報があるが、重要なのは設定ではなく教師画像の数・質・多様性だ。
画風学習
画像の加工は不要。トリガーワードも不要。
キャラ学習
anime-segmentation でキャラのみのマスクを作成し、--masked_loss と --alpha_mask とでキャラのみを学習させる。トリガーワードは必要。
水増し
教師画像の数が足りないなら nano-banana を使うか、動画生成 AI でターンテーブルの動画を作成し、いくつかのフレームを教師画像として使う。
各工程の重要度
LoRA 学習の工程は以下のようになる。
- 教師画像の蒐集
- 教師画像の加工
- 教師画像にキャプションをつける
- ハイパーパラメータの決定
- 学習
この工程中で一番重要なのは教師画像の蒐集と教師画像の加工だ。高品質・高解像度の画像を使い、不要な部分をトリミングするのが一番重要な作業になる。
kohya-ss インストール時の注意点
公式の GitHub では xformers をインストールすることになっているが不要だ(当然 xformers は使えなくなる)。xformers も scaled dot product attention(--sdpa)も、学習時間・性能・VRAM 使用量に差がない。
LoRA の種類
LoRA
Dreambooth に比べて、LORA のファイルサイズは小さい。その理由は U-Net のトランスフォーマーモデルのアテンション層(Q, K, V, O)だけを fine tune するのと、行列を分解してパラメータ数を削減できるからだ。
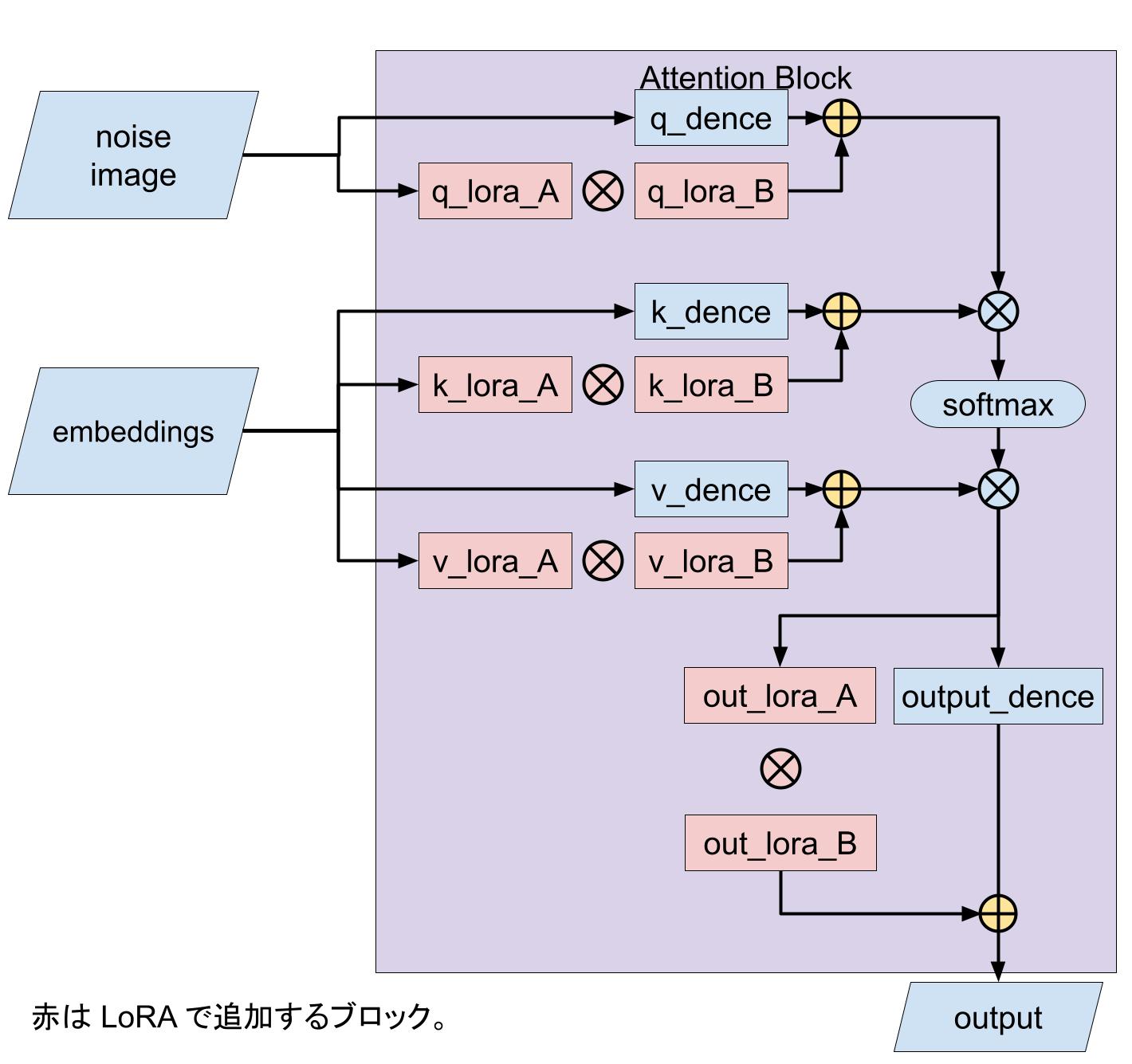
LoRA ブロック図
行列を使う理由
単純にファインチューンするだけなら、全結合層を使う方が学習時のメモリ使用量と計算量とが少ない。しかし行列を使うと元のモデルにマージして使える。なので推論時のメモリ使用量と計算量では LoRA が優れている。
行列分解の意味
行列を分解するとパラメータ数を劇的に減少させられる。
たとえば元の U-Net が 1,000 x 1,000 の行列だとしよう。するとパラメータ数は 100 万だ。しかしこれを B = 1,000 x 4, A = 4 x 1,000 の行列に分解すると、パラメータ数はわずか 8,000 になる。これをみれば、LoRA には学習速度とメモリ消費量との両方で絶大な利点があることがわかる。
dimension と rank
dimeision は行数や列数。n x m の行列なら n や m が dimension。
rank は行列を階段行列に変形したときに0でない行の数。階段行列に変形したときに0のみの行が現れる場合、内容が重複しているものが存在する。つまり rank の大きい行列はより多くの内容が含まれている。
n x m の行列の最大ランクは min(n, m) で rank(AB) ≦ min(rank(A), rank(B)) 。つまり行列のランクは次元の小さい行列やランクの小さい行列に制限される。なので network_dim で指定した値が LoRA の最大ランクになる。
Stable Diffusion(XL含む)の Attention ブロックの行列の最大次元は 1,280 x 1,280。学習させる内容が多いなら、network_dim のそれに応じて大きくする必要がある。
LoRA+
LoRA+: Efficient Low Rank Adaptation of Large Models
LoRA は隠れ層の次元(LoRA のランクではない)が大きくなると学習効率が低下する。また A と B とで学習率を変えることで、性能と効率が上がる。
学習率を2つ設定するのが面倒なので、行列1つで LoRA を作成するようにしたのが、SingLoRA。
表記
- \(c_n = \mathcal{O}(d_n)\):\(c_n < \kappa d_n\)
- \(c_n = \Omega(d_n)\):\(c_n > \kappa d_n\)
- \(c_n = \Theta(d_n)\):\(c_n = \mathcal{O}(d_n) \quad \text{かつ} \quad c_n = \Omega(d_n)\)
以下の分析では \(x = \Theta(1)\) を前提としている。これは、入力ベクトル \(x \in \mathbb{R}^n \) の次元数 n が増えても、各成分 \(x_i\) のスケールが一定に保たれているという意味。現在の Transformer は Attention や FFN の前に Normalize を入れるので、この仮定は合理的。
この仮定があると、\(x_i = \Theta(1)\) かつ \(a_i \sim \mathcal{N}(0,1)\) なら、\(a^\top x \sim \mathcal{N}(0, \sum x_i^2) = \mathcal{N}(0, ||x||^2)\) になる。
分析
以下のような LoRA モデルを考える。\( W^*\) は元のモデルで更新されない。
\[ f(x) = (W^* + ba^\top)x \]Loss を以下のように定義する。
\[ \mathcal{L}(\theta) = \frac{1}{2}(f(x)-y)^2 \]f の偏微分と Loss との偏微分はそれぞれ以下のようになる。
\[ \begin{split} \dfrac{\partial f}{\partial a} &= bx \\ \dfrac{\partial f}{\partial b} &= a^\top x \\ \dfrac{\partial \mathcal{L}}{\partial b} &= a^\top x(f(x)-y)\\ \dfrac{\partial \mathcal{L}}{\partial a} &= b(f(x)-y)x \end{split} \]パラメータの更新式は以下のようになる。\(\eta\) は学習率で、\(U_{t-1} = f_{t-1}(x) - y\)。
\[ \begin{split} b_t &= b_{t-1} - \eta \dfrac{\partial \mathcal{L}}{\partial b} = b_{t-1} - \eta(a_{t-1}^\top x)U_{t-1} \\ a_t &= a_{t-1} - \eta \dfrac{\partial \mathcal{L}}{\partial a} = a_{t-1} - \eta b_{t-1} U_{t-1} x \end{split} \]出力を展開すると以下のようになる。\(b_{t-1}(a_{t-1}^\top x) \) が前回の出力なので、残りの3つの項が \(\Delta f_t\) となる。
\[ \begin{split} f_t(x) &= b_t(a_t^\top x)\\ &= (b_{t-1} - \eta(a_{t-1}^\top x)U_{t-1})(a_{t-1}^\top - \eta b_{t-1}U_{t-1}x^\top x)\\ &= b_{t-1}(a_{t-1}^\top x) - \eta b_{t-1}^2 U_{t-1}||x||^2 - \eta (a_{t-1}^\top x)^2 U_{t-1} + \eta^2 b_{t-1}(a_{t-1}^\top x)U^2_{t-1} ||x||^2\\ \text{ただし}\\ x^\top x &= ||x||^2\\ f_{t-1}(x) &= b_{t-1}(a_{t-1}^\top x)\\ \end{split} \]\[ \begin{split} \Delta f &= - \eta b_{t-1}^2 U_{t-1}||x||^2 - \eta (a_{t-1}^\top x)^2 U_{t-1} + \eta^2 b_{t-1}(a_{t-1}^\top x)U^2_{t-1} ||x||^2\\ &= -\delta^1_t - \delta^2_t + \delta^3_t\\ \delta^1_t &= \eta b_{t-1}^2 U_{t-1}||x||^2\\ \delta^2_t &= \eta (a_{t-1}^\top x)^2 U_{t-1}\\ \delta^3_t &= \eta^2 b_{t-1}(a_{t-1}^\top x)U^2_{t-1} ||x||^2 \end{split} \]\(\delta^1_t\) は B の重みの更新で、\(\delta^2_t\) は A の重みの更新。
Neural Tangent Kernel: Convergence and Generalization in Neural Networks によると何の工夫もしないと x は \(\Theta(n^{-1/2})\) に従うので、隠れ層の次元の増加と勾配の増加とが比例しない。
そこで \((\delta^i_t)_{i}\in {1, 2, 3}\) のうちの少なくとも1つは \(\Theta(1)\) である必要がある。A と B とが意味のある重みを得るためには \(\delta^1_t, \delta^2_t\) が \(\Theta(1)\) でなければならない。その制約が成立するなら以下の方程式が成立する。
\[ \begin{split} &c+2\gamma [b_{t-1}]+1 &=0 \quad (\delta^1_t = \Theta(1)) \\ &c+2\gamma[a^\top_{t-1}x] &= 0 \quad (\delta^2_t = \Theta(1)) \\ &\gamma [b_{t-1}] + \gamma[a^\top_{t-1} x] &= 0 \quad (f_{t-1}(x) = \Theta (1)) \end{split} \]ただし以下の条件がある。
\[ \begin{split} \sigma_b^2 &= 0\\ \sigma_a^2 &= \Theta(n^{-1})\\ \eta &= \Theta(n^c)\\ v &= \Theta(n^{\gamma[v]})\\ U_{t-1} = f_{t-1}(x) - y &= \Theta(1) \; (\text{この時点で} \; f_{t-1}(x) = 0, y = \Theta(1) \; \text{と仮定}) \end{split} \]\(x = \Theta(1)\) と仮定されているので、\(||x||^2\) の期待値は、
\[ \mathbb{E}[||x||^2] = \sum^{n}_{i=1} \mathbb{E}[x_i^2] = n\cdot \dfrac{1}{n} = 1 \]\(a_0^\top x = \Theta(1) \) になる理由。a, b はそれぞれ \(a_i \sim \mathcal{N}(0, \sigma^2_a = \Theta(1)), \; b_i \sim \mathcal{N}(0, \sigma^2_b = \Theta(1/n)) \) で初期化されるので、
\[ \begin{split} a_0^\top x &= \sum^n_{i=1} a_{0i}x_i\\ Var(a_0^\top) &= \sum^n_{i=1} Var(a_{0i}) \cdot x_i^2 = \sigma^2_a \cdot ||x||^2 = \Theta(1)\\ \text{中心極限定理より}\\ a_0^\top x \sim \mathcal{N}(0, \Theta(1)) &\Rightarrow \Theta(1) \end{split} \]\(\delta^1_t\) は以下のように導出される。
\[ \large \begin{split} \delta^1_t &= \Theta(n^c\cdot (n^{\gamma [b_{t-1}]})^2 \cdot n^1) \\ &= \Theta(n^{c+2\gamma[b_{t-1}]+1}) \end{split} \]この \(\Theta\) が1になるには n の次数が0にならなければならない。
\(\delta^2_t \; \text{や} \; \delta^3_t\) も同様に計算できる。最終的には以下のようになる。
\[ \begin{split} c &= - \dfrac{1}{2}\\ \gamma[b_{t-1}] = \gamma[a^\top_{t-1}x] &= \dfrac{1}{4} \end{split} \]SingLoRA
SingLoRA: Low Rank Adaptation Using a Single Matrix
LoRA = AB, SingLoRA = AtA。パラメータ数が半分になり、LoRA 学習の不安定さが減少する。LoRA+ のように A と B とに別々に学習率を設定する必要もない。
\[ W_0 + \dfrac{\alpha}{r} u(t) AA^\top \]行列は Kaiming 分布で初期化する。u(t) は学習安定化のためのスケールで、初期は0、u(t) = min(t/T, 1)。
行列が正方行列でない場合、\(W_0 \in \mathbb{R}^{d_{in} \times d_{out}}\) で \(d_{in} < d_{out}\) とする。\(A \in \mathbb{R}^{d_{out}\times r}\) で、余剰を切り捨てて \(A^* \in \mathbb{R}^{d_{in} \times r}\) を作成することで次元を調整する。
分析
分析の基本は LoRA+を参照。
\[ \begin{split} f(x) &= (W_0 + u(t)aa^\top)x \\ \mathcal{L} &= \frac{1}{2}||f(x) - y||^2 \\ U_{t-1} &= f_{t-1}(x) - y \\ a_t &= a_{t-1} - \eta \dfrac{\partial \mathcal{L}}{\partial a} = a_{t-1} - \eta a_{t-1} U_{t-1} x\\ \nabla_a \mathcal{L} &= u(t)[ (a^\top_{t-1}x)(f_{t-1}(x)-y) + a^\top_{t-1}(f_{t-1}(x) - y)x ] \end{split} \]学習を隠れ層の次元に依存せず安定させるには \(f_t(x) = \Theta(1)\) である必要がある。\(W_0\) は固定なので、\(u(t)a_t(a_t^\top x) = \Theta (1)\)。もし \(a_t\) が隠れ層の次元に依存してスケールが変更されるなら、\(a_t(a_t^\top x)\) は \(\Theta (n^{2p+1})\) になる。\(\Theta = 1\) になるには 2p + 1 = 0 でなければならず、p= -1/2。
勾配の分析
\[ \begin{split} \eta &= \Theta(n^c) \\ \nabla_a\mathcal{L} &= \Theta_n (1) \; \text{なぜなら}\; (f(x) - y) = \Theta_n(1) \\ a^\top_{t-1}x &= \Theta(1),\; a^\top_{t-1}(f(x)-y)=\Theta(1)\;\text{(中心極限定理)} \\ \end{split} \]よって \(\eta = \Theta(n^{-1/2})\) で隠れ層の次元に依存せずに学習可能。LoRA+ と違い、2つの学習率を設定する必要がない。
LoRA-FA
原論文によると、LoRA の部分のメモリ使用量を最大で 30% 程度削減できる。なぜなら LoRA-FA は A と B とに分けた行列の B のみ学習させるので、A の部分のオプティマイザパラメータを節約できるからだ。
LoRA は行列を A と B とに分解して、A と B とを学習させる。LoRA-Frozen A では A をランダムな正規分布で初期化して固定する(学習させない)。そして B のみ学習させる。これによりメモリ使用量と計算量とを節約する。
LoRA も LoRA-FA もランク(network_dim)と学習率とに逆相関がある。ランク(network_dim)を上げる場合、学習率を下げないとパフォーマンスが維持できない。
メモリ使用量の計算
LoRA 部分の最大メモリ使用量は以下の式で計算できる。
パラメータ数 * (精度(fp16 or fp32)+ オプティマイザの種類)
fp16 はパラメータあたり2バイト、AdamW8bit も2バイトなので、パラメータ数に4を掛けるとメモリ使用量が推定できる。
SDXL の LoRA 部分のパラメータ数は2億程度(SD 1.5 は 9,300万)なので、fp16, AdamW8bit の場合は、800MB 程度。
これはランク(network_dim)が最大の場合なので、低ランクの場合、これよりはるかに小さいメモリ使用量になる。なので Stable Diffusion では LoRA-FA の効果は実感できない。
kohya 版
--network_module networks.lora ではなく --network_module networks.lora_fa を指定すると LoRA-FA が使える。
外部リンク
LoRA-FA: Memory-efficient Low-rank Adaptation for Large Language Models Fine-tuning
VeRA
LoRA はパラメータを AB という二つの行列に分解したが、VeRA は vBuA という4つの行列に分解する。パラメータ数が減ることで、メモリ効率が良くなる。
外部リンク
VeRA: Vector-based Random Matrix Adaptation
Tied-Lora: Enhancing parameter efficiency of LoRA with weight tying
スライダーLoRA
スライダーLoRAは体の一部(足の長さや、目の大きさなど)を変化させられる LoRA だ。LECO がよく使われるが、他の方法でも作成できる。
モデルにバイアスをかけて追加学習する 実践 スライダーLoRA編
Guide to training LoRA sliders/ adjusters/ scales (LECO)
交替直接差分学習法ADDifT(Alternating Direct Difference Training)の解説
LoHa
fine tune した内容をアダマール積を使って再定義する。連合学習(データを別々の環境で学習させて最終的にマージする方法)で使うよう設計されている。しかし LoHa は、LoRA よりパラメータ効率がいいという性質がある。LoRA は rank <= dim だが、 LoHa は rank < dim2 でいい。
A, B を行列とすると
LoRA:BA
LoHa:(A1B1T)∘(A2B2T) # ∘ はアダマール積。
一見すると LoHa は LoRA の2倍のパラメータ数だが、LoRA よりもさらに小さいランクでいいので、LoRA よりパラメータ数は少なくなる。
LoKR
LoHA のアダマール積の代わりにクロネッカー積を使う。
LoCon(LoRA-C3Lier)
LoRA はトランスフォーマ層しか fine tune しなかったが、LoCon は畳み込み層も fine tune する。ファイルサイズは LoRA より増加する。
kohya
「--network_args "conv_dim=4" "conv_alpha=1"」のように引数を指定すると LoCon が有効になる。
LyCORIS
--network_module=networks.lora を --network_module=locon.locon_kohya に変更する。
(IA)3
画風の学習に向いている。ファイルサイズが小さい(200KB~300KB)。
DyLoRA
DyLoRA は一度に複数のランクが学習可能な LoRA だ。個別に学習するよりは早いが、学習には時間がかかる。公式のトレーニング方法。
LoRA にはふたつの欠点がある。
- 学習後にランクが変更できない
- 最適なランクを見つけるのに手間がかかる
DyLoRA はトレーニング中に異なるランクを複数同時に学習させることでこの欠点を解決する。
方法はシンプルで、まず指定する最大サイズのランクで学習する。次にそのサイズより一つ小さいサイズのランクの行列の部分のみをマスクして学習させる。これを繰り返す。
LECO
LECO は特定の概念を消去する。実用的な使い方は、年齢や身長、バストサイズなどを調整するスライダー LoRA の作成だ。
通常の学習では教師画像に付与したノイズと U-Net が出力した除去すべきノイズとの差分を学習する。LECO ではキャプションで生成した画像と消去したい概念のキャプションで生成した画像との差分から学習する。なので教師画像は不要だ。
float16 は学習が不安定なので非推奨。float32 か bfloat16 を使う。bfloat16 は RTX30 世代以降で使える。
Erasing Concepts from Diffusion Models GitHub
Stable Diffusion から特定の概念を忘れさせる学習を行ってみる
ReLoRA
ReLoRA は LoRA を使ってファインチューンや事前学習を行う。これによって、 VRAM の少ない GPU でも巨大なネットワークのモデルを学習させられる。その理由は学習用の高 bit 数のメモリを使うのは LoRA 部分だけだからだ。学習を LoRA 部分に限定することで、推論用の巨大モデルは最適化された低 bit 数のメモリが使える。
手順は以下のようになる。
- LoRA で学習させる
- 元のモデルと LoRA をマージ
- 学習率を下げて0から LoRA を学習させる
- 納得がいくまで繰り返す
Stack More Layers Differently: High-Rank Training Through Low-Rank Updates GitHub
DoRA
DoRA は元の行列を大きさベクトルと方向ベクトル行列とに分解し、方向ベクトル行列のみを LoRA でファインチューンする技法。論文によると、DoRA は LoRA の半分のランクでも性能で LoRA を上回る。
分析
ウェイトの合計値の統計を取ってみると、ファインチューン(追加学習)は学習が進むにつれてウェイトの合計値が増減しているのに対し、LoRA では単調増加・単調減少することがわかった。
つまり LoRA は微調整が不得意な可能性がある。
そこで、元の行列の大きさベクトルを抽出し、方向ベクトル行列を正規化しておくことで、極端な大きさの方向ベクトルの影響力を抑えられる。これにより、DoRA はファインチューン(追加学習)に近い学習特性を実現している。
外部リンク
DoRA: Weight-Decomposed Low-Rank Adaptation
Improving LoRA: Implementing Weight-Decomposed Low-Rank Adaptation (DoRA) from Scratch
SaRA
SaRA: High-Efficient Diffusion Model Fine-tuning with Progressive Sparse Low-Rank Adaptation
10e-3 以下の値のウェイトを0に設定しても画質は変化しないどころか、元よりも良くなるケースもある。これらのウェイトは統計的な性質によるもので、学習を続ければ復活する。
アダプター行列を作成するのではなく、元のモデルのウェイトの絶対値が小さい部分のウェイトをマスクして、その部分のウェイトのみを学習で更新する。
LoRA 系列の学習
上記の系列の中で実際に使われるのは LoRA と LoHA と LoCon と LECO だ。畳み込み層も学習する LoCon が最も高品質だ。LoRA と LoHA は品質は同じで、 LoHA は LoRA よりファイルサイズが小さい。LECO は年齢や身長、バストサイズなどを調整するスライダー LoRA の作成によく使われる。
| 種類 | 性能 | ファイルサイズ |
|---|---|---|
| LoHA | 普通 | 小さい |
| LoRA | 普通 | 普通 |
| LoCon | 高い | 大きい |
LoRA・LoCon・DyLoRA は kohya-ss 版がスタンダードになっている。 Kohya_LoRA_GUI(Windowsアプリ)
LyCORIS 上記の3つに加えて DoRA に対応している。
LECO は LECO を使う
PC スペック
VRAM8GB 以上、RAM 16 GB 以上が必要。ただし RAM 16 GB ではほかのアプリをすべて終了させないと RAM が不足する場合がある。
kohya 版 LoRA を使う
公式が最も詳しく使い方を解説している。
DiffusersベースのDreamBoothの精度をさらに上げる・augmentation編
GUI
Python バージョン
3.10.6 を使う。3.10.12 のようなマイクロバージョン違いはアンインストールして、3.10.6 を入れた方がいい。
pip install に失敗する
Fatal error in launcher: Unable to create process using が出るときは python -m pip install ~とする。
Numpy のダウングレード
accelerate が Numpy 2 以降に対応していない。以下のコマンドで Numpy をダウングレードできる。
pip uninstall numpy pip install "numpy<2"
そのほかの学習ツール
ai-toolkit
GUI ツール。クラウド(RunPod)での学習もでき、現在シェアを増やしつつある。
musubi-tuner
kohya-ss が管理している学習スクリプト。以下のモデルに対応している。
- FLUX.1 Kontext
- FramePack
- Hunyan Video
- Qwen-Image
- Wan2.1/2.2
学習時に間違いやすいポイント
- 学習前に venv を有効にする
- 学習画像のディレクトリ構造
- 仮想メモリの容量不足
学習画像のディレクトリ構造
--train_data_dir には ./任意のディレクトリ/training、--reg_data_dir には ./任意のディレクトリ/reg を指定する。10_AAA や 10_BBB を指定するのではない。
任意のディレクトリ─┬─train─┬─10_AAA │ └─10_BBB │ └─reg ─┬─10_AAA └─10_BBB
ページングファイル不足のエラーが出る
Windowsの設定->システム->詳細情報->システムの詳細設定->パフォーマンス[設定]->仮想メモリ[変更] で仮想メモリの最大値を 80GB(80,000MB)程度に設定する。
学習
以下の設定の場合、VRAM 使用量は 5.1GB だった。RAM が 16GB の場合ページングファイル不足エラーが出る。学習中は 10 GB 程度 RAM を消費するため、ほかのアプリを起動させていると 16GB では RAM が不足することがある。
gradient_checkpointing を使用しない場合は VRAM 使用量は 6.2 GB だった。
設定ファイル例
名前は settings.toml で、配置場所は学習フォルダ(上の例では train)。
[general] enable_bucket = false # Aspect Ratio Bucketingを使うか否か flip_aug = false # 画像反転水増しを利用しない shuffle_caption = true # キャプションシャッフル有効 keep_tokens = 1 # キャプション先頭のトリガーワード保護 [[datasets]] batch_size = 1 resolution = [384, 512] [[datasets.subsets]] image_dir = '学習画像のフォルダ' # 学習用画像を入れたフォルダを指定 caption_extension = '.txt' # キャプションファイルの拡張子 num_repeats = 40 # 学習用画像の繰り返し回数
コマンド例
accelerate launch --num_cpu_threads_per_process 12 train_network.py --pretrained_model_name_or_path=モデルファイルの場所 --output_dir="E:\sd-scripts\output" --prior_loss_weight=1.0 --network_dim=4 --network_alpha=0 --learning_rate=1e-4 --max_train_steps=800 --optimizer_type="AdamW8bit" --sdpa --mixed_precision=bf16 --persistent_data_loader_workers --save_every_n_epochs=10 --save_model_as=safetensors --clip_skip=2 --seed=42 --network_module=networks.lora --dataset_config="E:\sd-scripts\train\settings.toml"
個人的推奨コマンド
| コマンド | 説明 |
|---|---|
| --sdpa | 高速化・省メモリ |
| --fp8_base | 高速化・省メモリ |
| --mixed_precision=bf16 | 省メモリ |
| --gradient_checkpointing | 省メモリ |
| --debiased_estimation | 色ずれの防止 |
| --optimizer_type="came_pytorch.CAME" | インストールするには venv を有効にして python -m pip install came-pytorch |
| --learning_rate 2e-4 | CAME の推奨値 |
| --optimizer_args "weight_decay=1e-2" "betas=(0.9, 0.999, 0.9999)" "eps=(1e-30, 1e-16)" | [CAME を使う場合の公式サイトの推奨値](https://pypi.org/project/came-pytorch/) |
| --lr_scheduler=cosine_with_restarts | |
| --lr_scheduler_num_cycles=4 | |
| --prior_loss_weight=1.0 | |
| --network_dim=8 | キャラ1人なら8で十分。ただし写真のような画風なら 32 以上必要かもしれない |
| --network_alpha=0 |
画像加工
画風学習の場合は、画像加工は不要。
キャラを学習させるときにまずやらなければならないのは、不要な背景のトリミングだ。キャラより背景の面積が広い場合、キャラではなく背景を学習する。
白背景(背景の塗りつぶし)はやらない方がいい。キャラと白背景との結びつきが発生する。
トリミング
画像加工で最も重要なことは不要な部分をトリミングすることだ。トリミングすると画像解像度がそろわないので Aspect Ratio Bucketing を使う。
ただしトリミング画像だけでは応用が利かないので、全身画像も必要になる。全身画像もポーズが重要でないなら腕の部分でカットしてもよい。
WAIFU SQUARELIZERは顔を認識して切り出してくれる。
WebUI の Train タブ Preprocess Image で Auto focal point crop をチェックすると、情報量の多い部分を自動で切り出してくれる。
XnConvert は画像を 512x512 にするときに便利。
背景除去
キャラ学習の場合は背景を除去する。SkyTNT/anime-segmentation で背景をアルファ化して --masked_loss と --alpha_mask とを指定するのが早い。
学習が速くなるので不要な部分をクロップするのも重要だ。
背景除去ツール
- GIMP のファジー選択
- iPhone/MAC/iPad ファイルを選択して「背景を削除」
- SkyTNT/anime-segmentation デモ版 ローカル導入法 WebUI Extension版
- PBRemTools(フリーのツールのなかでは高性能)
- remove.bg
- Adobe (要ログイン)
- Photoroom
不要物除去
sd_lama_cleaner(WebUI Extension 版)
ComfyUI なら lama remover。
物体検出
YOLOモデルを作る で ADetailer 等で使う物体検出モデルの訓練方法が解説されている。
Aspect Ratio Bucketing
Aspect Ratio Bucketing は学習画像に複数のアスペクト比が含まれる場合に有効にする。
enable_bucket = true のとき aspect ratio bucketing が有効になる。その場合 resolution オプションは無視されるが、resolution に何らかの値を指定する必要がある。
aspect ratio bucketing は可能なら利用すべきだ。正方形のアスペクト比は以下の欠点がある。
- 頭や脚がクロップされる
- 全身を入れると解像度が不足する
- 全身を入れると背景の面積が大きくなり、背景を多く学習してしまう
キャラクターに沿って画像をクロップすれば上記の欠点は避けられる。
オプション
| オプション | 説明 |
|---|---|
| enable_bucket | Aspect Ratio Bucket を有効にするかどうか |
| bucket_no_upscale | 学習画像が小さい場合にアップスケールするかどうか。true のときアップスケールしない |
| bucket_reso_steps | バケツサイズの増加幅。デフォルトの 64 で問題ない |
| max_bucket_reso | バケツの幅もしくは高さの最大サイズ。VRAM に余裕があるならこの数値を上げると解像度を上げられる |
| min_bucket_reso | バケツの幅もしくは高さの最小サイズ。デフォルトの 128 で問題ない |
キャプション・設定ファイル
Web から蒐集した画像のキャプションは画像生成のためのキャプションに適していないので、大企業はキャプション付けのための AI を自作している。DALLE-3 Improving Image Generation with Better Captions では ChatGPT 4 を使ったキャプション付けのためのプロンプトが紹介されている。
外部リンク
DALLE-3 Improving Image Generation with Better Captions
ImageInWords: Unlocking Hyper-Detailed Image Descriptions
キャプション方式
マルゼン式
マルゼン式はキャラに固有のタグを削除し、キャプションにトリガーワードを追加する。例えば white long hair や star hair ornament などのタグを削除する。つまりトリガーワードに削除したタグの内容を覚えさせる方式。
マルゼン式のキャプションは以下の特徴がある。
メリット
- 生成時のプロンプトを節約できる
- 削除したタグの内容を保護できる
デメリット
- プロンプトによる指示が難しくなる(特に服のタグを削除した場合は脱がしにくくなる)
- 手作業なので時間がかかる
キャラ固有のタグを削除しない方法
画風学習のときに使われる、キャラ固有のタグを削除しない方法は以下の特徴がある。
メリット
- タグの検査が楽
- プロンプトによる指示が効きやすい(脱がしやすい)
デメリット
- キャラの再現に長いプロンプトが必要になる
- タグの内容が上書きされる
- プロンプトが 75 トークンを超えると制御するのが難しくなる
タグ編集アプリ
自動タグ付け
ML-Danbooru
WebUI の Train タブの Preprocess images タブ
BLIP か deepbooru を使った自動タグ付けができる。
WD14Tagger
WebUI の Extension の Tagger。
手動管理
Dataset Tag Editor(WebUI の Extension)
wd14-taggerの新高性能モデルmoat-tagger-v2を使ってみよう!
キャプションファイルの先頭にタグを追記するコマンド
キャプションファイルのあるフォルダに移動して以下のコマンドでファイルの先頭に任意の文字を追記できる。
# Powershell 先頭追記
ls *.txt|%{echo "ここに追記したいタグを入れる, $(Get-Content -Path $_ -Raw -Encoding Default)" | Out-File -FilePath $_ -NoNewLine -Encoding Default}# Bash 先頭追記for i in *.txt; do echo -n "ここに追記したいタグを入れる, $(cat $i)" > "$i"; done
設定ファイルの class_tokens
設定ファイルの class_tokens はキャプションが存在しない場合のみ使われる。
トリガーワード
DreamBooth、class+identifier方式では identifier に指定した語がトリガーワードになる。ほかの方式ではキャプションの先頭にトリガーワードにしたい語を挿入する。
画風学習のキャプションファイル
画風学習のキャプションファイルは自動タグ付けしたキャプションをそのまま使う。教師画像の枚数が少ないなら、キャプション先頭にトリガーワードを追加して呼び出せるようにする。
キャラ学習のキャプションファイル
LoRA のキャプションファイルに書くのは「トリガーワード」と「覚えてほしくないタグ(1girl, solo white background, looking at viewer など)」だけだ。
「覚えさせたいタグ」がある場合キャプションからそのタグを削除する。「覚えさせたいタグ」とは学習対象の特徴を表現するタグだ。例えば赤目銀髪ロングのキャラクターなら、silver hair, long hair, red eyes が「覚えさせたいタグ」だ。服を覚えさせたいなら服の情報(long skirt, necktie, hood など)も削除する。
「覚えさせたくないタグ」は画像のメタ情報だ。white background や highly detailed, full body, 1girl など。これらのタグをキャプションファイルに書く。
服を覚えさせたい場合はキャプションから服の情報を削除する。着せ替えをさせたい場合は服の情報をキャプションに書く。
キャプションに含めたタグはその概念が変更されるので、必要なら正則化画像を使ってトリガーワード以外の語の概念を修正する。
キャラ立ち絵のキャプション例
aa12 はトリガーワード。教師画像がキャンディをもっているが、生成画像にキャンディを持たせたくなかったので candy, lollipop がキャプションに入っている。
aa12, candy, holding candy, holding lollipop, gradient background, 1girl, hood down, swirl lollipop, solo, grey background, looking at viewer, closed mouth, upper body
aa12, 1girl, solo, simple background, white background, breasts, looking at viewer, upper body
顔アップのキャプション例
aa12 はトリガーワード。
aa12, face, close-up, 1girl, solo, simple background, looking at viewer, white background, closed mouth
aa12, 1girl, solo, looking at viewer, blush, white background, upper body, hand up
keep_tokens
keep_tokens は設定ファイルで shuffle_caption = true にしたときに機能する。この機能はキャプションをシャッフルしたときに、キャプション先頭のトリガーワードを保護するために使う。例えばキャプション先頭のトリガーワードが sks とする。この語は1トークンなので keep_tokens を1に設定すれば、sks の位置は変化しない。トークンの区切りは ',' 。プロンプトを Clip に通した時のトークンではない。
キャプションのシャッフルが必要な理由
プロンプトは先頭の語の影響力が最も強く、後ろに行くにしたがって影響力が小さくなる。キャプションをシャッフルしない場合、キャプション後方の語の概念をトリガーワードが学習してしまうリスクがある。画像を学習するごとにトリガーワード以外のキャプションをシャッフルすることで、この学習の偏りを減らせる。
よくある例は white background だ。このタグはプロンプト後方に配置される事が多い。キャプションシャッフルがない場合は、トリガーワードが white background を学習し、白背景になりがちになる。
キャプションのシャッフルは TOML に以下のように記述する。
[general] shuffle_caption = true
キャプションのシャッフルは画像を1回学習するごとに行われる。
VRAM 削減
fp8_base
モデルを fp8 でロードする。 --fp8_base。
精度が重要な関数(活性化関数・loss 関数や sin, cos, log など)を自動的に昇格して計算してくれる AMP(mixed_precision)が必須。
実装は RAM にロードしたモデルを torch.float8_e4m3fn にキャストしているだけだ。
unet_weight_dtype = torch.float8_e4m3fn
unet.to(dtype=unet_weight_dtype)
mixed_precision
省メモリ化のため mixed precision (混合精度)で学習する。--mixed_precision "fp16" のように指定する。
xformers
xformers は facebook が開発したライブラリで、VRAM を削減し、計算速度が上がる。--sdpa と大差ないので入れなくていい。
gradient_checkpointing gradient_accumulation_steps
gradient checkpointing は計算速度が 10~20% 遅くなるが、VRAM 使用量が減る。
gradient_checkpointing と gradient_accumulation はまったく別の技術だ。
| 技術 | 目的 |
|---|---|
| gradient_checkpointing | VRAM 節約 |
| gradient_accumulation | 学習安定化 |
ネットワークの学習をするために、途中の計算結果を保存しておく必要があるが、これは VRAM を圧迫する。そこで途中の計算結果を間引いて、必要になったら再計算をすることで VRAM を節約するのが gradient_checkpointing。再計算が発生するのでふつうは学習が遅くなるが、モデルが巨大で VRAM ボトルネックの場合、逆に速くなることもある。
gradient_accumulation はステップ終了時に学習せずに、gradient_accumulation_steps の数だけ勾配を溜めておいて、溜まったらその平均を学習させる方法。小 VRAM で学習を安定させるために使う。
What is Gradient Accumulation in Deep Learning?
Training Deep Nets with Sublinear Memory Cost
データの水増し
DiffusersベースのDreamBoothの精度をさらに上げる・augmentation編
現在では Qwen Image Edit や Nano Banana を使った教師画像の水増しができる。
動画を使う
以下の手順で素材を水増しできる。
- Wan 2.2 で動画を複数作成
- 質の高いフレームを抜き出し
- 画風変換(スキップ可能)
- アップスケール
回転動画を使う
nijijourney で回転させた動画を作成して切り出して使う。
1.LoRAにしたい絵柄を考えて適当に絵を描く
— 852話(hakoniwa) (@8co28) June 26, 2025
2.nijijourneyで回転させた動画を作る
3.回転動画をフレーム減らして連番で出してLoRA学習
4.学習させたLoRAを使って出したい内容に合わせてPromptを調整 pic.twitter.com/TVKHwNAsnA
color_aug
学習時に色調・彩度・明度・ガンマをランダムに変化させる事で教師データごとの色合いの違いを吸収する。画風学習の時には false にする。
flip_aug
学習時にランダムに左右反転することで学習データを水増しできる。左右対称なキャラや、画風学習の場合は有用な機能。
回転
解像度の高い画像の場合は、回転させてトリミングすることで教師画像を水増しできる。
過学習防止
正則化画像は必要か
正則化画像を使わずに LoRA を作成するのが一般化しており、その意味では正則化画像は不要。
正則化画像を使ってモデルを保護する方法は Dreambooth の手法だ。
学習はキャプションに使われた全てのタグの概念を変更する。なのでトリガーワード以外のタグを修正する必要がある。一番影響が大きいのは画風だ。正則化画像がない場合、教師画像の画風も学習してしまう。画風も学習させたい場合は問題ないが、キャラのみを学習させたい場合は正則化画像で画風の影響を修正する必要がある。
sks guitar というキャプションで sks にギターの柄を学習させたいとする。このとき正則化画像がないと、sks にどのような内容が学習されるかわからない。sks と guitar と両方の語の概念が変更されるからだ。ここで guitar という Class プロンプトで正則化画像も使って学習させると、guitar という語の概念を修正できるので、sks に guitar 以外の概念を学習させられる。
ただしキャラや画風を再現したい場合は正則化画像は不要。正則化画像は、ポーズや特定アイテム、年齢変化等の LoRA を作る際に重要になる。
正則化画像の生成
正則化画像は訓練を行うモデルで作成する必要がある。そうしないと正則化画像の画風も学習してしまう。
prior_loss_weight
network_dropout
過学習を抑制するために訓練時に毎ステップでニューロンをdropする(0またはNoneはdropoutなし、1は全ニューロンをdropout)。
module_dropout
rank_dropout
Text Encoder または U-Net のランダムなランクを drop する。
scale_weight_norms
異常値のパラメータをピンポイントで修正する。
Max-Norm Regularization のハイパーパラメータ。 重みの値をスケーリングして勾配爆発を防ぐ(1が初期値としては適当)。
Max-Norm Regularization は scale_weight_nomrs の値を超えたパラメータのみを、正規化したあとに scale_weight_norms でスケールする。
Dropout and Max Norm Regularization for LoRA training #545
apply_max_norm_regularization で処理されている。
caption dropout
キャプションドロップアウトは過学習を防止するが、ドロップアウトしたタグをトリガーワードが学習してしまうデメリットもある。
caption_dropout_rate・caption_dropout_every_n_epochs だけ設定しても意味がない。これはキャプションドロップアウトの発生率を制御する。キャプションドロップアウト実行時のタグのドロップ率は caption_tag_dropout_rate で設定する。
caption_dropout_every_n_epochs と caption_dropout_rate はキャプションドロップアウトを実行するかどうかを決める。両方設定しても有効。
caption_tag_dropout_rate は実際のタグのドロップ率を決める。
学習
fp16 と bf16
bf16 は RTX3000 番台以降で使える。fp16 との違いは、指数と仮数のビット割り当ての違いだ。bf16 は fp16 より指数の割り当てが多い。ディープラーニングは指数の影響力が大きいので bf16 の方が学習に適している。
サンプルの出力
| オプション | 説明 |
|---|---|
| sample_every_n_steps | サンプル出力するステップ数。sample_every_n_epochs が優先される |
| sample_every_n_epochs | サンプル出力するエポック数 |
| sample_prompts | サンプル出力に使うプロンプトが書かれたファイルを指定する |
| sample_sampler | サンプル出力に使うサンプラーを指定する。'ddim', 'pndm', 'heun', 'dpmsolver', 'dpmsolver++', 'dpmsingle', 'k_lms', 'k_euler', 'k_euler_a', 'k_dpm_2', 'k_dpm_2_a' が使える |
sample_prompts
txt, toml, json で指定できる。以下は一度に2枚生成する txt ファイルの例。
# プロンプト。# で始まる行は無視される masterpiece, best quality, 1girl, in white shirts, upper body, looking at viewer, simple background --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 768 --h 768 --d 1 --l 7.5 --s 28 # prompt 2 masterpiece, best quality, 1boy, in business suit, standing at street, looking back --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 576 --h 832 --d 2 --l 5.5 --s 40
ソースコード
学習方式の選択
学習方式は以下の3つがあるが、実際は1つしかない。DreamBooth、class+identifier方式はキャプション固定のため普通は使わない。現在は正則化画像を使わない学習が一般化しており、その場合、DreamBooth、キャプション方式と fine tuning方式とに差はない。
- DreamBooth、class+identifier方式
- DreamBooth、キャプション方式
- fine tuning方式
リピート数とエポック数
繰り返し回数は、正則化画像の枚数と学習用画像の枚数を調整するために使う。正則化画像を使わない場合は、好きな方を使って学習回数を設定できる。
「エポック数:40回 リピート数:1回」と「エポック数:1回 リピート数:40回」とでは「エポック数:1回 リピート数:40回」の方が学習が速い。エポック開始・終了時の余計な処理がないので。
network_dim
LoRAのRANK。4~128 がよく使われる。デフォルトは4。数字が大きいほど以下の要素に負荷がかかる。
- 学習時の VRAM 使用量
- LoRA ファイルサイズ
- 学習にかかる時間
大きいほど記憶力は上がるが、性能が上がるわけでない。性能は以下の要素の影響が大きい。
- 教師画像の解像度
- 教師画像の質
- 教師画像の量
- 教師画像の前処理の品質(トリミングと背景塗りつぶし)
- キャプションの正確さ
dim_from_weights network_weights
dim_from_weights = true のとき network_dim を network_weights で指定した重みから計算する。
create_network_from_weights で計算している。
network_alpha base_weights base_weights_multiplier
これらのオプションはモデルの出力倍率を調整する。面倒なので network_alpha / network_dim の値を固定するといい。
network_alpha に0を指定すると network_dim と同じ値に設定される。
scale は network_alpha/network_dim で計算され、出力に掛け算される。デフォルト設定(dim=4, alpha=1)では scale は 0.25 だ。しかし network_dim が 128 の場合、scale は 0.0078 となり、出力が小さくなりすぎる。なので network_dim を大きくする場合は、learning_rate を大きくするか、network_alpha を大きくする必要がある。
これは network_dim が大きい場合にアンダーフローを起こす現象の対策として導入された(LoRA weight underflows)。
ソースコード
forward の最終出力は org_forwarded + lx * self.multiplier * scale 。
scale
scale = network_alpha/network_dim。
multiplier
デフォルトは1。差分学習機能追加 #542で追加されたオプション。ソースコード。
min_snr_gamma
付与するノイズが多い場合、推論エラーが増え、その結果 Loss が大きくなる。Loss が大きいということは、そのエラーの多い学習結果をより多く学習してしまう。そこで、SNR を計算して SNR が多いときは Loss を小さくすることで、その対策をする。論文では5が推奨されている。
debiased_estimation も同じ目的で使われる。個人的には、全タイムステップで自動調整される debiased_estimation の方がおすすめ。
計算式は loss = loss * min(min_snr_gamma, snr) / snr。
Efficient Diffusion Training via Min-SNR Weighting Strategy #308
debiased_estimation
付与するノイズが多い場合、推論エラーが増え、その結果 Loss が大きくなる。Loss が大きいということは、そのエラーの多い学習結果をより多く学習してしまう。そこで、SNR を計算して SNR が多いときは Loss を小さくすることで、その対策をする。
min_snr_gamma も同じ目的で使われる。
Unmasking Bias in Diffusion Model Training
zero_terminal_snr
SD 1.5 や SDXL はノイズスケジューラーにバグがあり、完全なノイズになるまでノイズを付与しない。これはモデルに、"ノイズの中に常に何らかのシグナルが残っている" という誤った情報を学習させてしまう。
zero_terminal_snr を指定すると、完全なノイズになるまで学習する。v_parameterization を使用しているモデルで使用することが多い。
学習ステップ数の少ない LoRA 作成では、ノイズの多いステップを引くことが少ないので効果が実感できない可能性が高い。
v_parameterization
従来の ε-Prediction はネットワークにノイズを予測させるが、v-Prediction はノイズとデノイズ後の画像との差分(つまり速度)を予測させる。v-Prediction は数値の安定性の改善、高解像度でのカラーシフトの除去、サンプルの収束速度の改善という利点もある。
これは v-Pred で訓練されたモデルでファインチューンするときに指定する。
noise_offset
SD 1.5 や SDXL はノイズスケジューラーにバグがあり、完全なノイズになるまでノイズを付与しない。zero_terminal_snr は完全なノイズになるまで学習するのに対し、noise_offset は追いノイズによって修正する。引数は追いノイズの量。
学習率
モデルの出力が network_alpha と network_dim の値で変化するので、network_alpha と network_dim の比率は固定した方がいい。
network_alpha / network_dim を scale と呼ぶ。scale は 1.0 や 0.5 がよく使われる。network_alpha に0を指定すると network_dim と同じ値に設定される。
scale が異なる場合、scale ごとに learning_rate を決める必要があり面倒。
scale = 1.0 の場合、learning_rate は 1e-4程度がよい。
learning_rate
learning_rate を指定した場合、テキストエンコーダーと U-Net とで同じ学習率を使う。unet_lr や text_encoder_lr を指定すると learning_rate は無視される。
unet_lr と text_encoder_lr
プロンプトで再現できそうな内容ならば text_encoder_lr > unet_lr にすると、モデルの変形を小さくできる。
元のモデルで再現できない物・髪型・アクセサリー・服などならば unet_lr > text_encoder_lr にする。この場合 text_encoder_lr は unet_lr の半分や 0.1 にすることが多い。
トリガーワードを強調しないと学習内容が出てこない
text_encoder_lr を上げる。
関係のないオブジェクトが大量に出現する
text_encoder_lr を下げる。
学習画像から無関係なオブジェクトを取り除く。
教師画像の画風の影響が強い
unet_lr を下げる。
スケジューラ
スケジューラは学習率を制御する。学習率の変化の様子はHugging FaceのLearning Rateを調整するためのSchedulerについて深堀するを参照。
教師画像の枚数が少ない場合は cosine_with_restarts、多い場合は constant を使うことが多い。
指定方法
--lr_scheduler=cosine_with_restarts --lr_scheduler_num_cycles=4
学習率が固定または単調減少するスケジューラー
これらのスケジューラーは局所的最適解から抜け出せないので非推奨。
- constant (固定)
- constant_with_warmup (ウォームアップ付き固定)
- cosine
- linear (単調減少)
- polynomial(多項式)
constant は学習画像が大量にある場合に使う。
warmup は学習率を自動調整するオプティマイザと合わせて使われることが多い。
cosine_with_restarts
学習率が固定または単調減少するスケジューラーだと局所的最適解から抜け出せない。そこで学習率を上下させて局所的最適解から抜け出せるようにしたものが焼きなまし法(Annealing)。
cosine_with_restarts は基本的に cosine と同じだが、lr_scheduler_num_cycles で学習率を元に戻す回数を指定できる。つまり --lr_scheduler=cosine_with_restarts は --lr_scheduler_num_cycles= も指定する必要がある。lr_scheduler_num_cycles は全エポック内で何回学習率をリセットするかを指定する。
constant_with_warmup
lr_warmup_steps は何ステップかけて本来の学習率に戻すかを決める。
オプティマイザ
オプティマイザは学習率とパラメータのウェイトの変化量を調整する。手動オプティマイザは learning_rate を手動調整する必要があるが、自動オプティマイザは learning_rate を 1.0 に指定すると自動調整してくれる。
手動調整のオプティマイザは AdamW8bit と CAME が人気だ。手動調整のオプティマイザは Prodigy がよい。2024年12月に追加された RAdamScheduleFree はパラメータ設定もスケジューラーも不要で AdamW を超える性能で注目されている。
手動
- AdamW (8bit 版は省メモリ)
- CAME (省メモリで学習が速い)
- SGDNesterov
- Lion (省メモリ)
自動
AdaFactor の欠点を修正したのが CAME(ただし学習率は手動調整)。D-Adaptation のバグを修正したものが Prodigy。
- AdaFactor
- D-Adaptation
- Prodigy
- RAdamScheduleFree
クオリティアップ
自動オプティマイザはある程度学習が終わった後に、クオリティアップの学習をさせられない。細部の再現性を上げる為に低い learning_rate で学習させるには、手動オプティマイザに切り替えて行う必要がある。
l2 loss と smooth_l1
--loss_type "l2"
--loss_type "l2" デフォルト設定で、学習は速いが外れ値に弱い。キャプションが間違っていたり、学習させたいものから外れた教師画像があるとそれを多く学習してしまう。
--loss_type "smooth_l1"
--loss_type "smooth_l1" は学習は遅くなるが外れ値に強い。
外れ値の対処法
外れ値はバッチサイズや gradient accumulation steps を上げることでも軽減できる。これらの設定は勾配を平均化して、学習データひとつあたりの影響力を小さくしてくれる。
データセットが大きく外れ値がそこそこある場合は以下の選択肢がある。
- 外れ値を取り除くか修正する
- --loss_type "smooth_l1" を使う
- バッチサイズを上げる
- gradient accumulation steps を上げる
AdamW(8bit)
よく使われるオプティマイザで計算が速い。8bit の方は VRAM 消費量も小さい。8bit 版はオプティマイザが使用するデータを量子化して保存する。再使用する際に逆量子化して使用する。
AdamW はパラメータ1つあたり8バイトのメモリが必要になる。8bit 版はパラメータ1つあたり2バイト。
Decoupled Weight Decay Regularization
解説
Adam の m はパラメータの運動量(momentum)から来ている。パラメータごとに運動量が保存されており、特定方向に動くとしばらくはそちらに動き続ける性質がある。momentum がない場合、局所的な学習の影響を受けすぎて収束が遅くなる。
Adam の Ada は Adaptive の略で、パラメータごとに学習率を設定する。アルゴリズムとしては、パラメータごとに変化量の累積を保存しておき、変化量の累積に対応して学習率を小さくする。
Adam は Adaptive の係数が学習内容と掛け算されている問題があった。つまり本来は運動量だけが適応的に減衰すべきなのだが、学習内容まで余計に減衰されていた。AdamW ではその部分のバグが修正されている。
CAME
省メモリ・学習が速い・学習が安定している、という特性があり人気がある。バッチサイズを上げても性能が劣化しにくいので、大規模な学習にも使える。
省メモリのオプティマイザはメモリに保存している運動量(momentum)の方向と学習情報の方向との差が大きいと間違った方向へ向かってしまう。そこで CAME では、運動量ベクトルと学習情報ベクトルとの差分を計算し、運動量ベクトルをその差分で割る。こうすることで運動量と学習情報との差が大きいときに運動量が小さくなり、間違った方向へ行きづらくしている。
パラメータ
CAME は AdaFactor のように運動量行列を2つの低ランク行列(r, c)に分割することで、メモリ使用量を削減している。運動量ベクトルと学習情報ベクトルとの差分行列 U もまた分割して(R, C)保存されている。
| パラメータ | 説明 |
|---|---|
| ε1 | 勾配の正則化 |
| ε2 | 運動量ベクトルと学習情報ベクトルとの差分の正則化 |
| β1 | 運動量の更新量。小さいほど更新量が多い |
| β2 | 低ランク行列の更新量。小さいほど更新量が多い |
| β3 | 運動量ベクトルと学習情報ベクトルとの差分行列の更新量。小さいほど更新量が多い |

疑似コード
出典:CAME: Confidence-guided Adaptive Memory Efficient Optimization. Yang Luo et al. Algorithm 2
AdaFactor
省メモリだが、学習が遅く、学習が不安定になりやすい。
Adam はパラメータごとに運動量と勾配とを保持しているので、SDG の3倍のメモリ使用量になっていた。AdaFactor は Adam と同性能で Adam の半分以下のメモリしか使わない(ただし AdamW8bit よりは VRAM 使用量は多い)。
AdaFactor はパラメータ1つあたり4バイトのメモリが必要になる。
AdaFactor の解説は [Paper] Adafactor: Adaptive Learning Rates with Sublinear Memory Cost が詳しい。AdaFacotr は運動量の2次モーメント行列を2つの非負のランク1行列に分解してパラメータを保持しているため、省メモリだが、学習が不安定になる。
Adafactor: Adaptive Learning Rates with Sublinear Memory Cost
relative step
パラメータ数が増えるにつれて学習率を大きくする機能。
固定学習率
--optimizer_type=adafactor --optimizer_args "relative_step=False" --lr_scheduler="constant_with_warmup" --max_grad_norm=0.0
SGDNesterov(8bit)
SGD に Nesterov Momentum を追加したもの。
Understanding Nesterov’s Momentum in Gradient Descent Optimization
Lion(8bit)
AdamW より計算が速く、収束が速い。AdamW と違い運動量の総和を保存していないので、AdamW よりメモリ使用量が小さい。Lion は以下の疑似コードを見ると、運動量と学習内容とのブレンド後の符号(-1, 0, 1 のどれか)を使ってウェイトを更新する。
Lion の疑似コード。beta1 = 0.9, beta2 = 0.99 がデフォルト値。lambda はウェイト減衰の強さ
def train(weight, gradient, momentum, lr):
update = interp(gradient, momentum, beta1)
update = sign(update)
momentum = interp(gradient, momentum, beta2)
weight_decay = weight * lambda
update = update + weight_decay
update = update * lr
return update, momentum
出典:Symbolic Discovery of Optimization Algorithms. Xiangning Chen et al. Program 1
Symbolic Discovery of Optimization Algorithms
D-Adaptation
DAdapt系は学習率を自動調整するアルゴリズムだ。Adam や Lion、SGD などのオプティマイザと合わせて使える。ただし学習率を無視するわけではなく学習率を 1.0 にすることが推奨されている。
計算が遅いので使用例が少ない。
LAZY DADAPTATION GUIDE
DAdapt系は weight_decay が重要。学習が遅い場合は weight_decay を少しずつ上げてみる。
DAdaptAdam の時は下記のようなオプションが必要。decouple=True は AdamW スタイルのウェイト減衰を有効にする。
--optimizer_args "decouple=True" "weight_decay=0.4" "betas=0.9,0.99"
| オプション | 値 | 解説 |
|---|---|---|
| learning_rate | 1 | |
| text_encoder_lr | 1 | |
| unet_lr | 1 | |
| weight_decay | 0.2~1 | 数値が小さいほど学習に時間がかかるが過学習になるリスクは少ない |
| num_repeats | サブフォルダごとに1 | エポックでステップ数を調整すれば面倒な計算は不要 |
| resolution | 512 | DAdapt系で 512 を超える解像度を扱うには良い GPU が必要 |
| clip_skip | 2 | NAI ベースのモデル用の設定 |
| pretrained_model_name_or_path | NAI | |
| lr_scheduler | cosine | constant は良くない。公式で constant が推奨されている理由がわからない |
| batch_size | 任意 | ハードウェアに合わせて上げる |
| max_train_epochs | 任意 | 教師画像 36、3 キャラ LoRA を作成した際の設定は、230 エポック、weight_decay 0.4、2,400 ステップ、batch_size 6 だった |
| network_dim | 32 | 8で十分という人もいる |
| network_alpha | 16 | alpha/dim が 0.5 になるように調整する |
| lr_warmup_steps | 0.1 | 訳注:lr_warmup_step は整数で、本来の lr に到達するまでのステップ数を指定する |
Prodigy
D-Adaption の改良版。原著論文によると、手動調整の Adam と同じ精度の結果を出しているらしい。D-Adaptation と同様に学習率を自動調整するが、学習率を 1.0 にすることが推奨されている。
収束が速く、教師画像の再限度も高い。
デフォルトでは AdamW と同様にウェイトを減衰させる。decouple=False を指定すると、ウェイト減衰の代わりに L2正則化が有効になる。
Prodigy: An Expeditiously Adaptive Parameter-Free Learner
新オプティマイザ「Prodigy」を使ってLORAを作ってみた。
インストール
.\venv\Scripts\activate pip install prodigyopt
設定例
--optimizer_type="prodigy" --learning_rate=1 --optimizer_args "betas=0.9,0.999" "weight_decay=0"
RAdamScheduleFree
面倒な設定不要で AdamW を超える性能のオプティマイザ。
kohya-ss では SD3 ブランチで使える。アルゴリズムの解説は全ての学習率スケジューリングを過去にするOptimizerが詳しい。
ウォームアップもスケジューラーの指定も不要。以下の設定で使える。
--optimizer_type=RAdamScheduleFree
学習率は高めに設定できる。公式のデフォルト値は 2.5e-3(SDXL の学習に使うには 2.5e-3 は高すぎる気がする)。
階層別学習率
画風や顔のみなど特定の部位のみを学習させたいときに使う。どの層がどこに効いているかは以下のリンクを参照。
sd-webui-lora-block-weight(U-Net の層ごとに適用率変更)
LoRA Block Weight Plot Helper(階層情報解析ツール)
SD 1.* 2.* の層
SD 1.* と 2.* の U-Net は大きく分けて入力・中間・出力に別れる。入力・出力それぞれ 12 ブロックあるが、すべて同じではない。入力と出力は以下のように4層に別れている。
- 入力
- 1層0~3(0,1は Transformer ブロック。3はダウンサンプルブロック)
- 2層4~6(4,5は Transformer ブロック。6はダウンサンプルブロック)
- 3層7~9(7,8は Transformer ブロック。9はダウンサンプルブロック)
- 4層10~11(Transformer ブロックなし)
- 出力
- 1層9~11(すべて Transformer ブロック)
- 2層6~8(6,7は Transformer ブロック。8は Transformer ブロック+アップサンプルブロック)
- 3層3~5(3,4は Transformer ブロック。5は Transformer ブロック+アップサンプルブロック)
- 4層0~2(Transformer ブロックなし。2はアップサンプルブロック)
下層に行くほど解像度が小さくなる(4層は8 x 8)が、特徴を表現する次元が大きくなる。入力潜在空間画像は(4, 64, 64)。4が特徴を表現する次元だ。最下層では(1280, 8, 8)になる。
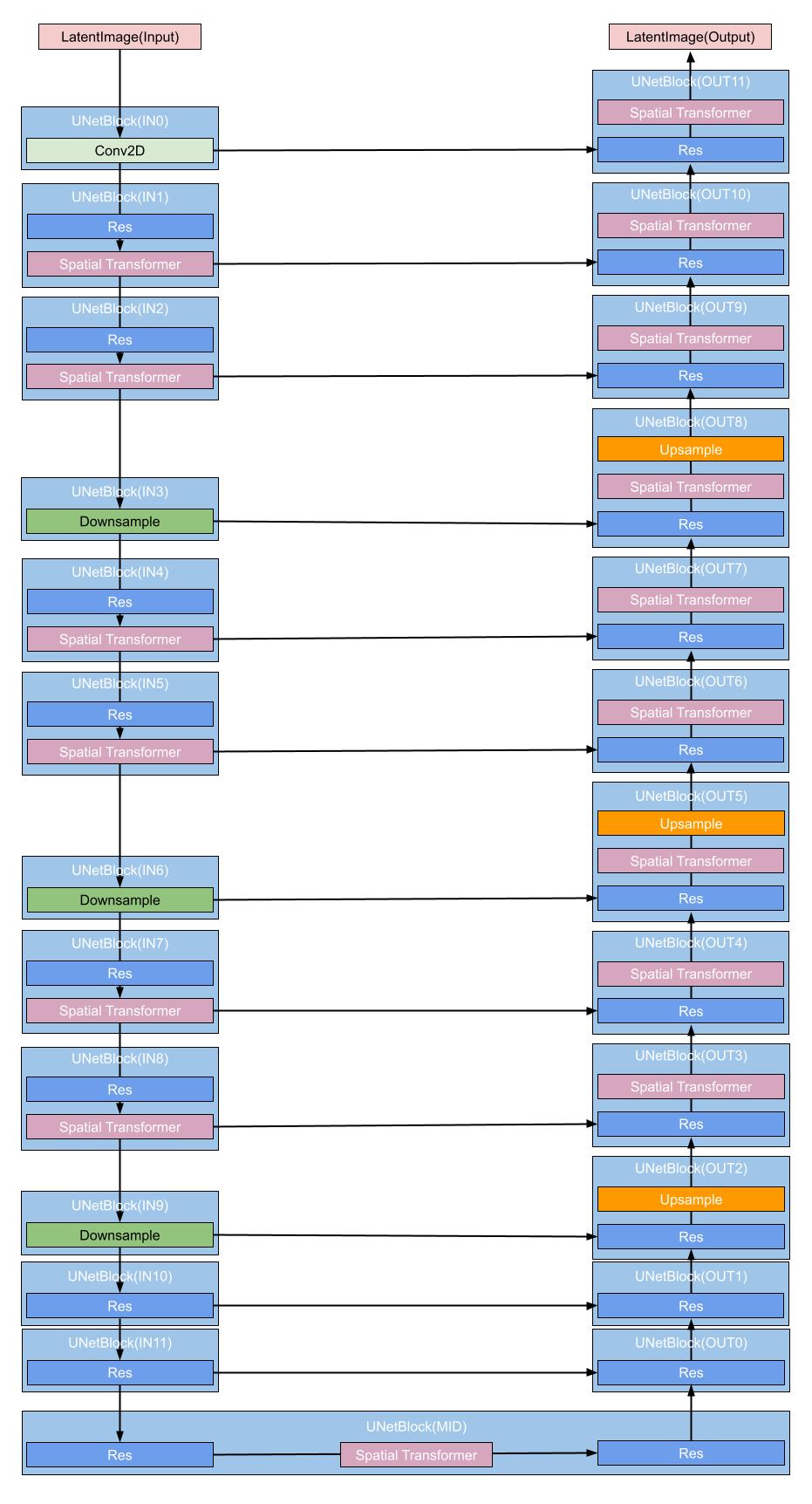
SD 1.*, 2.* の U-Net 構造
SDXL の層
SDXL の U-Net は大きく分けて入力・中間・出力に別れる。入力・出力それぞれ9ブロックあり、入力と出力は以下のように3層に別れている。
- 入力
- 1層0~3(Transformer ブロックなし。3はダウンサンプルブロック)
- 2層4~6(4と5のブロック当たりの Transformer ブロックは2個、6はダウンサンプルブロック)
- 3層7~8(ブロック当たりの Transformer ブロックは 10 個)
- 出力
- 1層7~8(Transformer ブロックなし)
- 2層3~6(3~5のブロック当たりの Transformer ブロックは2個、6はアップサンプルブロック)
- 3層0~2(ブロック当たりの Transformer ブロックは 10 個。2はアップサンプルブロック)
下層に行くほど解像度が小さくなるのは旧 SD と同じだ。旧 SD はブロックあたりの Transformer ブロック数は等しかったが、SDXL は下層ほど Transformer ブロックが多い。
高速化
latents の事前取得
あらかじめ画像の潜在表現を取得しディスクに保存しておく。よく使う教師画像や正則化画像で行うと効果が高い。
省メモリ設定
batch_size = 1 optimizer_type="AdamW8bit" mixed_precision="fp16" gradient_checkpointing sdpa
学習に VAE は不要
U-Net は潜在空間で処理を行うため、学習画像をあらかじめすべて潜在空間表現にしておけば VAE は不要だ。その分 VRAM を節約できる。
テキストエンコーダーをファインチューンしないならテキストエンコーダーも不要
キャプションをあらかじめ embedding に変換しておけば、テキストエンコーダーも不要。その分 VRAM を節約できる。
logging_dir
--logging_dir=logsと指定すると、作業フォルダにlogsフォルダが作成され、その中の日時フォルダにログが保存される。
コマンドプロンプトで以下のコマンドを実行すると tensorboard でログが分析できる。
tensorboard --logdir=logs
WandB 形式のログも出力できる。
SDXL
U-Net 部分の LoRA は transformer ブロックを訓練する。SDXL の transformer ブロックは大きい。旧 SD は transformer ブロックは4つだが、SDXL は transformer ブロックが 12 ある。加えてテキストエンコーダー2つ分の入力を処理するため、transformer ブロック自体も巨大化している。なので network_dim は1~8のような小さい値でも効果がある。
- 教師画像のデフォルト解像度は 1,024 x 1,024
- PyTorch 2 の方が少しだけ VRAM 使用量が少ない。
- --bucket_reso_steps のデフォルト値が 32 になり、SDXL の訓練では 32 未満の値では動作しない。
SDXL はテキストエンコーダーが2つあり、テキストエンコーダー学習時の挙動がよくわかっておらず、テキストエンコーダー込みで学習すると失敗することが多かった。しかし現在ではテキストエンコーダー込みで学習させた方が性能が良い。
以下は Adafactor を使う場合の設定例
optimizer_type = "adafactor" optimizer_args = [ "scale_parameter=False", "relative_step=False", "warmup_init=False" ] lr_scheduler = "constant_with_warmup" lr_warmup_steps = 100 learning_rate = 4e-7 # SDXL original learning rate
ファインチューン
- ReLoRA を使わないファインチューンには 24 GB 必要
- 24GB で訓練できるのは U-Net のみ
- gradient checkpointing が必要
- --cache_text_encoder_outputs でキャプションをキャッシュすると、テキストエンコーダーの分の VRAM を節約できる
- オプティマイザは Adafactor が推奨。RMSprop 8bit と Adagrad 8bit は動作する。AdamW 8bit は動作はするがうまく学習できない
LoRA VRAM8GB
VRAM8GB で U-Net かテキストエンコーダーかどちらか片方は LoRA で学習させられる(ただしVRAM 10GB以上を推奨)。VRAM8GB なら以下の設定を推奨。
- gradient checkpointing
- --cache_text_encoder_outputs
- Adafactor か8bit オプティマイザ
- network_dim は8以下
検証
シードの固定
通常の学習ではシードを固定する必要はない。しかし、オプティマイザや学習率等を検証する場合は絶対にシードを固定しなければならない。
学習速度や Loss の大小はパラメータの調整よりも乱数のシードに大きく影響される。大きいタイムステップを引けば付与するノイズが少ないので Loss が小さくなり、小さいタイムステップを引けば付与するノイズが多いので Loss は大きくなる。
Loss とタイムステップ(付与するノイズ量)の関係
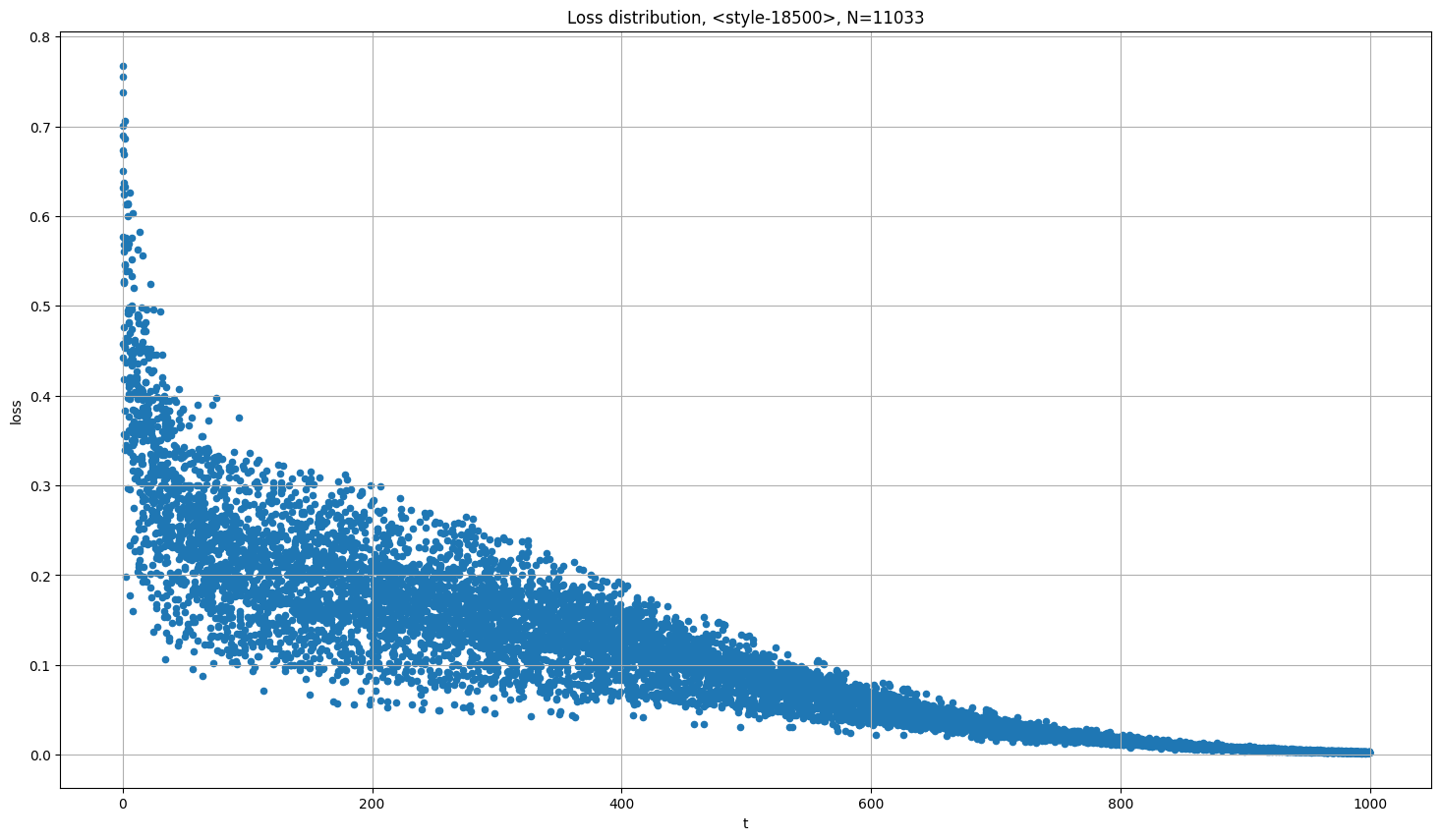
付与するノイズ量が多いほど Loss も大きい
出典:https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/4043
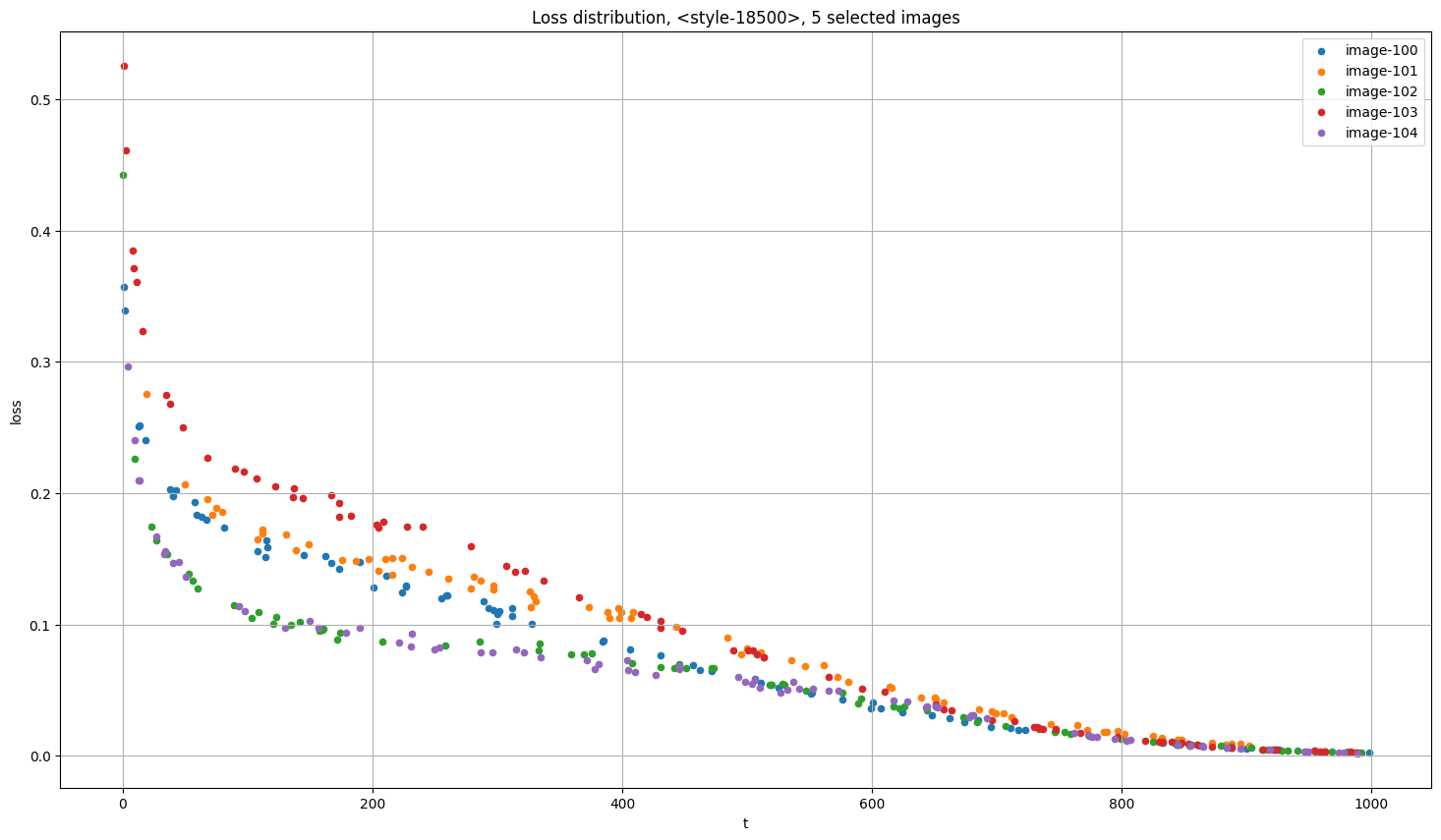
学習画像ごとの Loss のプロット
出典:https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/4043
Loss が大きくなる2大原因は、付与するノイズ量が多いか、間違ったキャプションがついているかだ。Loss の大きい画像の内容が多く学習されるので、Loss の大きい画像には特別な注意を払う価値がある。背景付きの画像は Loss が大きくなる。背景面積の広い画像は背景を学習しているのと変わらない。
学習の再開
以下のコマンドで続きから再開できる。
--network_weights="LoRA ファイルのパス"
画風の学習
画風の学習は前処理の手間が少ないので、LoRA 初心者におすすめだ。
正則化画像
不要。
キャプション
キャプションは自動タグ付けをそのまま使う。教師画像が多いならトリガーワードも不要。
画像加工
背景の白塗りは不要。
color_aug は無効にする。flip_aug と回転とランダムクロップによる水増しは有効。クロップで頭が切られるとそれを学習するので、手動でクロップして水増しを行う。
LoRA の種類
線の品質が重要なので LoCon を使う。
そのほか
オプティマイザやスケジューラーは通常通り。
外部リンク
公式解説
DiffusersベースのDreamBoothの精度をさらに上げる・augmentation編
英語の Training Guide
[Guide][Local training] Creating anime character LoRA (Illu or NoobAI)
lora training logs & notes - crude science (WIP)
検証・作成ログ
【StableDiffusion】VRoidからつくる衣装LoRA制作メモ【データセット付き】
コピー機LoRA
論文など
[輪講資料] LoRA: Low-Rank Adaptation ofLarge Language Models
LoRA: Low-Rank Adaptation of Large Language Models (原著論文) GitHub
QLoRA: Efficient Finetuning of Quantized LLMs
ReLoRA Stack More Layers Differently: High-Rank Training Through Low-Rank Updates GitHub