NovelAI Diffusion V3 の改善点
v-Prediction Parameterization
SDXL では ε Prediction が使われている。これはノイズ画像からノイズ部分を予測させる方法だ。この方法は SNR=0(純粋なノイズ画像)の状況では機能しない。
v-Prediction はノイズとデノイズ後の画像との差分(つまり速度)を予測させる。この方法では SNR に依存せずに正しく予測が機能する。
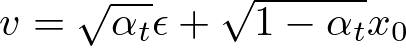
v-Prediction の数式
ε:ノイズ
x0:ノイズのない画像
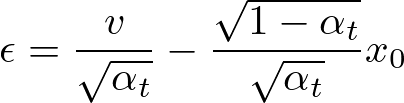
数式を変形するだけで v-Prediction のモデルの出力からノイズが計算できる。
これにより、従来の ε Prediction のツールやサンプラーが利用できる
後述する Zero Terminal SNR を実装するために、v-Prediction が採用されている。Zero Terminal SNR では純粋なノイズ画像になるまで学習させるが、ε Prediction では純粋なノイズ画像ではうまく学習できない。
v-Prediction は数値の安定性の改善、高解像度でのカラーシフトの除去、サンプルの収束速度の改善という利点もある。
v-Prediction は Google の IMAGEN で採用されていることで有名。v-Prediction の原著論文は Progressive Distillation for Fast Sampling of Diffusion Models。
ちなみに Stable Diffusion 3 の論文 では以下の4つの手法を比較した結果、RF loss を採用した。
- ε-Prediction(eps)
- v-Prediction
- EDM (F-Prediction)
- RF loss

v-Prediction と RF loss は 10 ステップで高いスコアーを得ている。
RF loss はすべてのステップで v-Prediction より高いスコアーを得ている。
出典:Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. Patrick Esser et al. Figure 3
時系列
2020 年6月の時点ではノイズを予測させる(ε-Prediction)かデノイズ後の画像を予測させるかの選択しかなかった。Denoising Diffusion Probabilistic Models ではノイズを予測させる(ε-Prediction)方がデノイズ後の画像を予測させるより性能が良かったと報告している。
2022 年2月に v-Prediction の原著論文 Progressive Distillation for Fast Sampling of Diffusion Models が発表される。
2023 年6月に SDXL が発表される。
Zero Terminal SNR
SDXL は欠陥のあるノイズスケジューラーで訓練されており、常に中間的な明るさのサンプルを生成するようになっている。
具体的には SDXL のノイズスケジューラーは最大までノイズを付与しても純粋なノイズにならない。これはモデルに、"ノイズの中に常に何らかのシグナルが残っている" という誤った情報を学習させてしまう。

「completely black」 というプロンプトで生成した画像。純粋なノイズになるまで学習させたもの(ZTSNR)は正しく画像が生成されている。素の SDXL(no ZTSNR)は、中間的な明るさの純粋なノイズをヒントに画像を生成するため、生成画像の明るさも中間的なものになり、プロンプトも無視される
出典:Improvements to SDXL in NovelAI Diffusion V3. Juan Ossa et al. Figure 2

素の SDXL(no ZTSNR)では画像の平均明るさを調整するために、プロンプトを無視して背景や髪、服を明るくしたり暗くしたりする
出典:Improvements to SDXL in NovelAI Diffusion V3. Juan Ossa et al. Figure 3
一般的な拡散モデルのスケジューラーの問題は Common Diffusion Noise Schedules and Sample Steps are Flawed で指摘されている。
SDXL-Turbo#3.5Fix the Schedule では t = T の時に純粋なノイズになるような例外処理を入れることで、この問題に対処している。
解像度に依存しないノイズスケジューラ―を利用することで高解像度での生成品質を改善
SDXL は高解像度で σmax が小さすぎる問題がある。σmax は画像生成時の初期ノイズの量と学習時のノイズ量との最大値を制御する。解像度を増やし、かつ SNR を維持するには、より多くのノイズが必要になる。

解像度を変えて固定比率のノイズを付与したものの比較
高解像度の画像の情報を破壊するにはより多くのノイズが必要になる
出典:On the Importance of Noise Scheduling for Diffusion Models. Ting Chen. Figure 2
分かりやすい例は高解像度での人物の分裂だ。SD 1.x や SDXL では解像度を増やすと顔や体のパーツが増殖していた。これは σmax が小さすぎることが原因の一つだ。

高解像度での σmax の違い
出典:Improvements to SDXL in NovelAI Diffusion V3. Juan Ossa et al. Figure 6
経験則では、ピクセル数を4倍(縦横2倍)にして、SNR を維持するには、σmax を2倍にする(ピクセル数2倍なら σmax は 1.414 倍)。これは上限値なので σmax を2倍以上にしても生成画像の品質は改善しない。
高解像度での追加のノイズ付与の必要性は Simple diffusion: End-to-end diffusion for high resolution images で指摘されている。
Stable Diffusion 3 の論文のセクション 5.3.2 Resolution-dependent shifting of timestep schedulesでは σmax を変更するのではなく、タイムステップを変更することでノイズ量を制御している。
外部リンク
Improvements to SDXL in NovelAI Diffusion V3
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
SDXL-Lightning: Progressive Adversarial Diffusion Distillation
Illustrious XL 3.0-3.5-vpred, 2048 Resolution and Natural Language