AUTOMATIC1111 の便利な機能
AUTOMATIC1111 は更新を停止している。以下の移行先がある。
- ComfyUI:最もユーザーが多く最新技術がいち早く取り入れられる。AUTOMATIC1111 と互換性はない
- sd-webui-forge-classic:SD 1.5・SDXL 専用。AUTOMATIC1111 と互換性あり
- sd-webui-forge-neo:classic と同じ作成者で最新機能を取り入れるブランチ。すでに Qwen Image Edit・Lumina Image 2.0・Wan・SageAttention などの技術は実装済み。AUTOMATIC1111 と互換性あり
- vladmandic/sdnext:A1111 と互換性はないが、最新モデルの対応が早く、AMD の ROCm に対応
目次
- デティール追加
- Refinier
- CD(Color/Detail) Tuner(色調や書き込み量を調節)
- After Detailer(顔を検出して顔を加筆)
- Dotgeo(hijack) Detection Detailer(顔を検出して顔を加筆)
- LLuL - Local Latent upscaLer(指定した矩形の箇所を加筆)
- Detection Detailer(マスクの自動生成)
- img2img
- img2img のステップ数を直接指定
- Only masked(マスクした部分を拡大してから再生成して合成:旧 Inpaint at full rsolution)
- Batch img2img(フォルダ内の画像すべてに img2img を実行)
- Face Restration(顔を修復する機能)
- Loopback(img2img の結果に img2img を実行する)
- --gradio-img2img-tool(簡易ペイントツール追加)
- 色の補正
- Detection Detailer(顔のマスクを自動生成してくれる Extension)
- Depth-guided model(深度情報を使った img2img)
- Novel AI のような noise strength
- プロンプト
- ファインチューン
- 操作
- Generate ボタンを右クリック > Generate forever で止めるまで生成。止めるときは右クリック > cancel
- Ctrl + Enter で Generate
- Ctrl + Z プロンプトを元に戻す
- スライダーをクリックした後十字キーで1ずつ増減できる
- Alt + ← or → カンマ区切りの文字を選択して左右移動(1.5.0 以降)
- 検証
- X/Y plot(パラメーターの検証に使う)
- Prompt matrix
- Visualize Cross Attention(プロンプトが画像のどこに効いているか可視化)
- DAAM Extension for Stable Diffusion Web UI(プロンプトが画像のどこに効いているか可視化)
- UI
- 高速化
- forgeを使う
- sd-forge-blockcache
- 532.03 以降の GeForce ドライバを使う
- xformers
- FlashAttention-2
- --opt-sdp-attention(VRAM 消費量が増えるが xFormers より速くなるかもしれない)
- Token merging
- HyperTile
- ライブプレビューを切る
- pytorch 2.0(RTX4000番台で高速化する)
- TensorRT Extension for Stable Diffusion Web UI
- TensorRT support for webui
- Lsmith
- Latent Consistency Model
- Adversarial Diffusion Distillation
- SDXL Turbo
- 省メモリ
- そのほか
- Extension など
- Config Presets(設定保存)
- sd_web_ui_preset_utils(設定保存)
- Booru tag autocompletion for A1111(タグ補完)
- extensionEditor(AUTOMATIC1111向けのプロンプトエディター)
- Dataset Tag Editor(タグで画像を編集したり、タグを編集するエディタ)
- Helper GUI for manual tagging/cropping(画像のタグ管理エディタ)
- embedding editor(768 個ある潜在表現ベクトルを手動で調整)
- multi-subject-render(背景とオブジェクトとを雑コラしてくれる)
- Regional Prompter (プロンプトの効く領域を指定)
- Latent Couple extension(プロンプトの効く領域を指定)
- Depth map library and poser(手の深度マップライブラリ)
- Cutoff - Cutting Off Prompt Effect(色移り防止)
- ABG_extension (背景透過)
- 【Stable Diffusion】WebUIに必ず導入したいおすすめの拡張機能40選+α【Extensions】
- animeDiff
- Controlnet
- ポーズ・構図の指定と着色ができる。Image2Image はグレースケール画像の着色ができなかったが Controlnet ではそれができる。
- ControlNet の新モデル Anystyle
- Reference-Only(参考画像を基にイラスト作成)
- ControlNetでポーズや構図を指定してAIイラストを生成する方法
- AUTOMATIC1111+ControlNetのつかいかた2(目当ては自動塗り)
- AIで適当な線画を清書し、さらに色を塗って高品質なイラストに仕上げる方法【ControlNet活用術】
- 画像生成AIを線画整えツールや自動彩色ツールにする
- Character bones that look like Openpose for blender _ Ver_6 Depth+Canny+Landmark(Blender 上でポージングできるツール)
- 「ControlNet 1.1」の新機能まとめ!新しいモデルや改善点を紹介【Stable Diffusion】
- ControlNet(v1.1)の詳しい解説!輪郭やポーズから思い通りの絵を書かせる
- 入力線画を全く変えずに画像生成AIに色塗りさせる方法
- MLSD
- プリプロセッサの dw_openpose(写真から棒人間を作成して入力)
- Multi-Controlnet
- Extension
- Model
AUTOMATIC1111のアップデート
以下のどちらかでアップデートできる。
- 端末(コマンドプロンプトや Powershell)から git pull
- zip をダウンロードしてきてファイルの置き換え
AUTOMATIC1111 はアップデートで環境がよく壊れるので、最新版と安定版でフォルダを分けるといい。git でタグを使うと管理が容易になる。
git の操作
リポジトリの取得
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
最新版にアップデート
stable-diffusion-webui のディレクトリで git pull
You are not currently on a branch. がでるときは、git checkout master を実行。
更新履歴の閲覧
半角の q で終了。commit の後ろの数字が SHA。
git log
--grep でログを検索できる。
git log --grep "検索したい文章"
git pull で環境が壊れた時
git clone したあと git checkout 戻りたい地点の SHA] を実行する。SHA は[ここで取得できる。
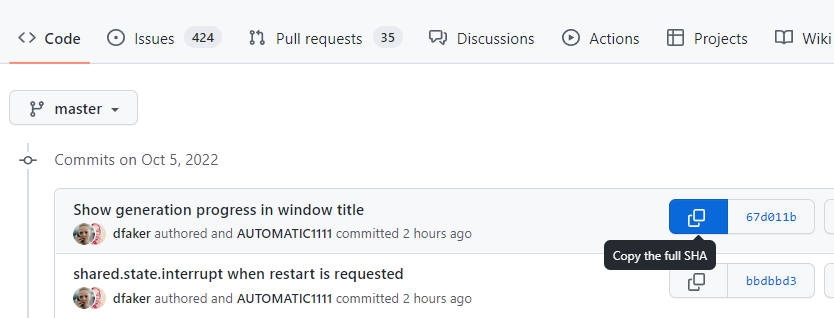
SHA の取得
強制的に戻すには git reset --hard [SHA]。
git のタグ
タグをつける
git tag "タグ名" で今のコミットにタグをつける。タグ名は半角英数を推奨する。
タグのバージョンに移動
git checkout "タグ"
タグの一覧を表示
git tag
タグの削除
git tag -d "タグ"
コミットはせずに変更を退避したいとき
ソースや設定ファイルを変更して git pull が失敗するときは一度変更を退避する。
変更を退避する
git stash -u
退避した作業の一覧を見る
git stash list
退避した作業を戻す
git stash apply stash@{0}
退避した作業を消す
git stash drop stash@{0}
SDXL
--xformers と --medvram とを指定すると、VRAM8GBでも SDXL が実行できる。2023年7月現在では、リファイナーは image2image で実行する。
set COMMANDLINE_ARGS=--xformers --no-half-vae --medvram
アップスケーラー
アップスケーラーの追加
models/ESRGAN にモデルの pth ファイルを追加する。ファイルはhttps://upscale.wiki/wiki/Model_Databaseが網羅的。
Kohya HRFix Integrated
WebUI Forge で使える。特定のブロック(構図に影響のあるブロック)で画像を縮小することで、高解像度画像生成時の分裂を防ぐ。
| パラメータ | 解説 |
|---|---|
| Block Number | 適用するブロック |
| Downscale Factor | 縮小率。縮小後の解像度が 1024 x 1024 に近くなるように設定する。例えば 3k x 3k で生成するなら、Downscale Factor に3を設定する |
| Start Percent | 適用を開始するステップ数 |
| End Percent | 適用を終了するステップ数 |
webui/ui-config.json の以下の項目を編集すればスラーダーで 2k を超える解像度を設定できる。
"txt2img/Width/maximum": 2048, "txt2img/Height/maximum": 2048,
外部リンク
forward_of_sdxl_original_unet.py
Highres. fix
2023 年1月のアップデートでスケール率を指定するようになった。width, height に 512 を指定して、Hires. fix の Upscale by に2を指定すると、出力画像サイズは 1,024 x 1,024 になる。
Latent は書き込み量は多いが、ノイズが花びらになったりして不便だ。4x-UtraSharp や Real-ESRGAN を使うと、それがある程度抑えられる。pth ファイルを models/ESRGAN フォルダに入れて WebUI を再起動すると使える。
生成可能解像度
以下の表は xformers と --no-half-vae を有効にしている。--no-half-vae を外すと、VRAM8GBでもフルHDの画像を生成可能。
| VRAM 容量 | 9 : 16 | 2:3 | 1:1 |
|---|---|---|---|
| 8 GB | 921 x 1,728 | 1,024 x 1,536 | 1,280 x 1,280 |
| 12 GB | 1,484 x 2,784 | 1,587 x 2,380 | 2,048 x 2,048 |
| 16 GB | 2,048 x 3,840 | 2,304 x 4,096 | 3,072 x 3,072 |
Upscale latent space image when doing hires. fix
Upscale latent space image when doing hires. fix が有効な場合は潜在空間でアップスケールする。無効な場合は一度初期ノイズ画像を生成してから、その生成したノイズ画像をアップスケールする。そしてアップスケールしたノイズ画像を潜在空間に戻して絵を描く。
なので Upscale latent space image when doing hires. fix を有効にした方が少し早くなる。場所は Settings タブ。
外部リンク
Stable Diffusion Upscale
Stable Diffusion Upscale は以下の工程で画像を拡大する。
- 画像を RealESRGAN/ESRGAN で拡大
- 拡大した画像を分割
- 分割したそれぞれの画像に対し img2img を実行
- 結果を結合
Tile overlap
スケール後の画像が 1024px * 1024px でタイルサイズが 512px * 512px の場合9回 img2img が実行される。なぜなら、分割境界を自然にするための余白が必要になるからだ。タイルサイズが 640px * 640px なら img2img の実行は4回ですむ。
Tile overlap で余白のサイズを設定できる。大きくすれば継ぎ目は自然になるが、大きすぎると余計に img2img を実行するので遅くなる。
img2img の実行が4回ですむ width と height の計算方法は単に Tile overlap を2倍して足すだけだ。元の画像サイズが width 512px, height 768px で Tile overlap が 64px のとき各値は以下のようになる。
512 + (64 * 2) = 640px(width)
768 + (64 * 2) = 896px(height)
推奨設定
- サンプラー:Euler a
- Denoising strength 0.2~0.4
Seed resize
シードの画風を維持したまま、解像度を変更する機能。通常はシードやプロンプトを固定しても、出力解像度を変更すると画像が大きく変化してしまう。
この設定の場所は Extra。
アウトペインティング
アウトペインティングはアップスケーラーとは違い、作成した画像に追記して拡張する。
アウトペインティングをする場合はステップ数を大きく(50~100)した方がいい。そして denoising と CFG スケールとを最大にする。
Extension の Tiled Diffusion
img2img のように画像をタイルごとに分割してアップスケールする。Tiled VAE により継ぎ目が自然になることと、Region Prompt Control でプロンプトが効く範囲を指定できるのが強みだ。
外部リンク
高解像度の画像を生成できる拡張機能「Tiled Diffusion with Tiled VAE」の使い方【Stable Diffusion web UI】
ディテール追加
Refiner
バージョン 1.6.0 から Refiner ワークフローに対応した。これは SDXL で無くても利用できる。
場所は Generation タブの中段。
Switch at は Refiner に切り替えるサンプル数を設定する。例えば Step 20 で Switch at が 0.8 の場合、16 ステップから Refiner のモデルが使われる。
以下のサンプラーが対応している。
- kdiffusion
- DDIM
- PLMS
- UniPC
initial refiner support #12371
FreeU
FreeU はファインチューニングも追加学習もせずに画像の品質を向上させる。
解説
U-Net のバックボーン(後半)はデノイズを行っている(前半は情報抽出)。U-Net はスキップ接続によって U-Net のデコーダーが高周波数の情報(絵のディティール・エッジ・テクスチャなど)を復元できるようになっている。しかしスキップ接続で渡された情報の低周波数の部分(全体の構図など)が、バックボーンのデノイズ能力を低下させている。
FreeU は2つの情報の制御を行う。ひとつはスキップ接続でバックボーンに提供する情報で、もうひとつはバックボーンネットワークの影響力の強さだ。バックボーンに提供する情報の影響力は s で、バックボーンネットワークの影響力の強さを b で制御する。公式の GitHub では b を少し強くして、s を小さくするように指示している。
バックボーンに提供する情報は高速フーリエ変換した後に、s で調整し、逆高速フーリエ変換している。全体を s で調整すると出力がスムースになりすぎるので、s で調整するのは低周波数の部分だけに限定している。
出口に近いバックボーンの b を強くすると出力がスムースになりすぎるので、出口に近いバックボーンの影響力は強化しない。
拡張機能
- Start At Step:FreeU を開始するステップ数
- Stop At Step:FreeU を終了するステップ数
- Transition Smoothness:FreeU をいきなり開始・終了しないようにスムースに適用する
- Backbone n Scale:U-Net stage n のバックボーンの強さ
- Backbone n Offset:バックボーンに適用するウインドウのオフセット
- Backbone n Width:バックボーンに適用するウインドウの幅
- Skip n Scale:U-Net のステージ n でスキップ接続で提供される情報の低周波数成分のスケール
- Skip n High End Scale:U-Net のステージ n でスキップ接続で提供される情報の高い周波数成分のスケール
- Skip n Cutoff:低周波数と高周波数とのしきい値。0は最低周波数のみ、1は全周波数が Skip n Scale の影響を受ける
バックボーンの Offset と Width は Backbone Scale の適用範囲をきめる。例えばバックボーンのウェイトが以下のような 100 個の1次元配列とする。
w_1, w_2, ..., w_100
このとき Offset = 0.1、Width = 0.5 なら Backbone Scale の適用範囲は w_10 ~ w_60 になる。
Stage 1 は構図に与える影響が強く、Stage 3 はテクスチャに強い影響を与える。
tips
Backbone Scale は色や構図自体が変わるので1にした方がいいかもしれない。手を描くのに失敗した場合に以下の設定で生成すると、うまくいくケースが多い(モデルは Counterfeit v3)。
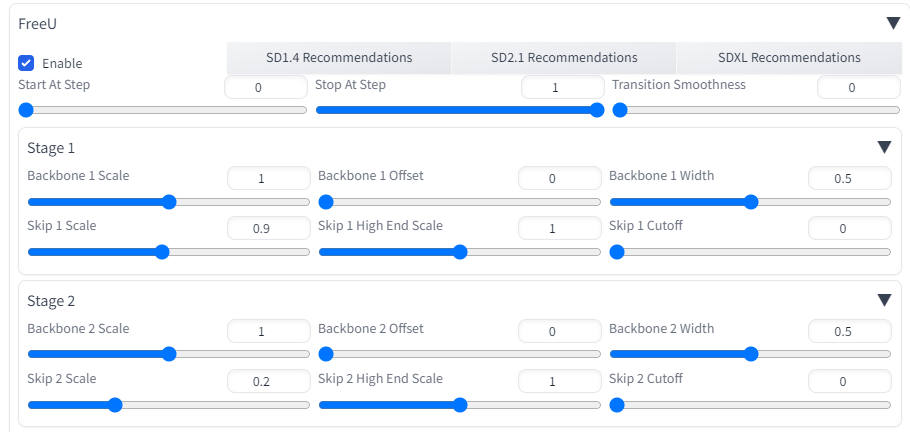
Skip Scale 設定
うまくいかないときは Skip 1 Scale を 0.1 ずつ下げていく

FreeU なし

FreeU あり
Skip 1 Scle:0.7
Skip 2 Scle:0.2
プロンプト:2girls hugging
ネガティブプロンプト:lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
モデル:Counterfeit-V3.0_fp16
へそ乳首抑制にも使える。
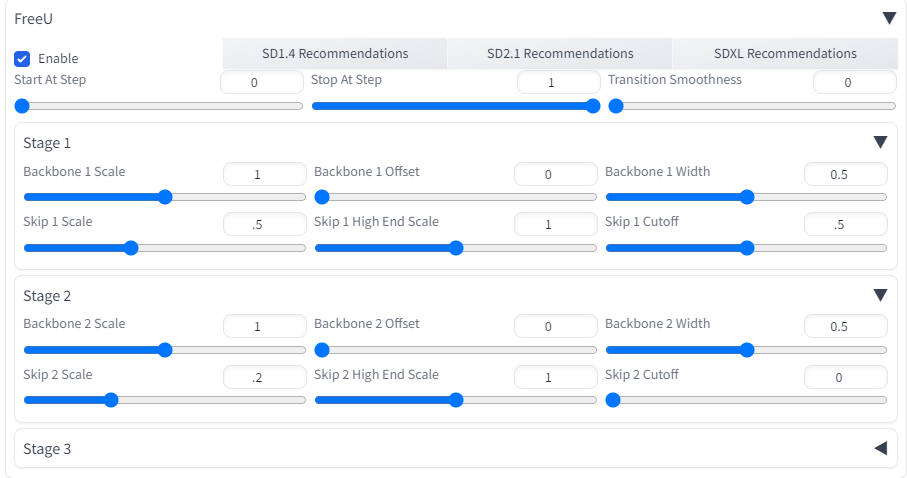
へそ乳首抑制(Counterfeit v3)
論文
FreeU: Free Lunch in Diffusion U-Net(arXiv) GitHub Project Page
img2img
img2img のステップ数を直接指定
img2img のステップ回数は「Denoising strength * ステップ数」回程度しか実行されない。なのでDenoising strength を 0.1 のような低い値にするとステップ数を上げないと画質が下がる。
Settings タブのStable Diffusion の With img2img, do exactly the amount of steps the slider specifies にチェックを入れると指定したステップ回数実行されるようになる。
Only masked(旧:Inpaint at full resolution)
マスクした部分をターゲット解像度に拡大してから再生成して合成する機能。
Mask blur
マスクの境界をぼかす機能。継ぎ目が気になるときに数値を上げる。
Batch img2img
フォルダに入れた画像すべてに img2img を実行する機能。Output directory を空欄にしておくと、Input Directory にファイルを出力する。
Face Restoration
顔を修復する機能。実写向け。
Loopback(img2img の結果に img2img を実行する)
Loopback は img2img の結果を img2img に入力することを繰り返す機能だ。使い道がなさそうだが、白黒の線画画像の着色に使える。線画の着色はControlNetを使う方が高品質だ。
--gradio-img2img-tool(簡易ペイントツール追加)
img2img に簡易ペイントツールを追加する。
コマンドライン引数に --gradio-img2img-tool color-sketch を追加すると使える。
set COMMANDLINE_ARGS=--gradio-img2img-tool color-sketch
色の補正
Settings タブの Stable Diffusion の Apply color correction to img2img results to match original colors. で img2img の色補正を有効にできる。
Depth-guided model(深度情報を使った img2img)
512-depth-ema.ckptでのみ使える。
インストール方法
- models/Stable-Diffusion フォルダに 512-depth-ema.ckpt を配置する
- models/Stable-Diffusion フォルダに v2-midas-inference.yamlを配置する
- v2-midas-inference.yaml を 512-depth-ema.yaml にリネーム
- Stable Diffusion checkpoint で 512-depth-ema.ckpt を選択する
外部リンク
[Stable Diffusion] Depth-to-Imageモデルを学習なしで特定のドメインに適応させる
Depth map library and poser(手の深度マップライブラリ)
Novel AI のような noise strength
Settings タブの Stable Diffusion の Noise multiplier for img2img で設定できる。
プロンプト
プロンプトのトークン数表示
ネガティブプロンプト
ネガティブプロンプトについてはネガティブプロンプトを参照。
Attention/emphasis(語の強調)
強調したい語(複数可)を() で囲む。逆に弱くしたい語を [] で囲む。
- "a (word)" - word の影響力を 1.1 倍にする
- "a ((word))" - word の影響力を 1.21 倍(=1.1 * 1.1)にする
- "a [word]" - word の影響力を 0.9 倍にする
- "a (word:1.5)" - word の影響力を 1.5 倍にする
- "a (word:0.25)" - word の影響力を 0.25 倍にする
- "a \(word\)" - 文字通りの () を入力したい場合
数値による重み付けは () にだけ有効で [] ではできない。"[word:2.0]" は無効な書式。なぜなら "[word:2.0]" は Prompt Editing と解釈されるから。
語を選択して Ctrl + 十字キー Up や Down で強調の強さを変更できる。
2022-09-29 のアップデートで影響力を数値で指定できるようになったが、後方互換性は失われた。たとえば古い実装では "a (((farm))), daytime" は "a farm daytime" とコンマを抜いた文として解釈されることがあった。新しい実装ではこのバグが修正されている。現状はオプション設定で古い実装を使用できるようにしてある。
AUTOMATIC1111 では "\(\)" で文字通りの () が入力できる。文字通りの () は danbooru タグで名前の衝突を解決するときによく使われる。
- pokemon \(anime\)
- pokemon \(creature\)
- shimakaze \(kancolle\)
- shimakaze \(azur lane\)
- shimakaze \(azur lane\)\(cosplay\)
- tied up \(nonsexual\)
- tied up \(sexual\)
- photo \(background\)
- pom pom \(cheerleading\)
- pom pom \(clothes\)
- dakimakura \(medium\)(ベッドで寝ている画像を出したいときによく使う)
- dakimakura \(object\)(普通の抱き枕)
- masturbation \(female\)
- masturbation \(male\)
- stocking
- stocking \(psg\)
- lily \(flower\)
- lily \(vocaloid\)
- lily \(granblue_fantasy\)
- >:\((怒り顔)
- \(o\)_\(o\) :漫画でよく見る黒目
Styles
プロンプトを保存しておける機能。フロッピーのアイコンの "Save prompt as style" を押すと、styles.csv にプロンプトが保存される。
Style 1 もしくは Style 2 を選択して、クリップボードのアイコンをクリックすると、プロンプトやネガティブプロンプトに「追加」される。
プロンプト内容は stylec.csv で編集できる。
CLIP interrogator
画像のプロンプトを推測する機能。img2img タブにある。
Deepdanbooru(画像の Danbooru タグを表示する)
img2img タブで画像をセットして、interrogate deepdanbooru を押す。
Increase coherency by padding from the last comma within n tokens when using more than 75 tokens
トークンが 75 を超えるとそこでプロンプトを分割して、別に別に処理して合成する。この時コンマやピリオド以外の場所で分割されると意味が変わってしまう。そこで 75 文字を超える場合はある程度までプロンプトを見返して、コンマのところで分割するようになっている。
Increase coherency by ~の設定は何トークンまでさかのぼるかを設定する。
Prompt Editing
Prompt Editing は画像生成の途中でプロンプトを変更する機能だ。Prompt Editing を使うと通常では不可能な表現が可能になる。たとえば "a girl [wearing a onepiece:naked:0.5]" とすると、服が透けている表現になる。これはステップ数が 50 とすると、最初の 1~25 ステップは "a girl wearing a onepiece" を実行し、26~50 ステップは "a girl naked" を実行する。
- [smile:sad:0.5] として表情をブレンドすることも可能。
- "[white::0.5] hair, [:red:0.5] eye" などで色移り対策
- [octane render::0.5] で実写とイラストをブレンド
- [cloth:naked:0.5] で透けを表現できる
- [no wearing:wearing blue dungarees:0.1] で裸オーバーオール
色のコントロール
色の制御については以下のリンクが参考になる。
PART3 -プロンプトの工夫で指定色が混ざるのを防ぐ方法-
第5回 -プロンプトに入力しても意味をなさない単語はあるか?-
色を複数指定すると色うつりする問題は、色の数が2~3ぐらいなら以下の方法で対処できる。
黒いドレスと銀髪の例
- [black dress:((((white silver)))) hair:0.8]
- [black::0.8] dress and [((((silver)))):0.8] hair
AI が絵を描く過程
AI はステップが小さいうちは大まかな形を描き、ステップが進むにつれて細部の描きこみを行う。たとえば牛からカエルへ変化する "a [cow:frog:0.5]" という Prompt Editing を考えてみる。最初は牛を描くので牛の外見をしている。そして細部の描きこみを行うステップでカエルを描くようになる。最終的には、牛の形だがディティールはカエルという絵になる。
Wiki の翻訳
Prompt Editing は画像生成の途中でプロンプトを変更する機能だ。基本的な文法は以下のようになる。
[from:to:when]
from と to には任意のテキストが入る。when にはプロンプトを変更するステップ数が入る。遅く変更すればするほど to の影響力は小さくなる。when には0~1の数値を指定することもできる。その場合は「ステップ数 * when」が計算されて自動的に入力される。
以下のような表記も可能だ。
- [to:when] - when ステップ後に to を追加する
- [from::when] - when ステップ後に from を除去する
例 "a [fantasy:cyberpunk:16] landscape"
- 1~16 ステップは a fantasy landscape で描く
- 17 ステップ以降は a cyberpunk landscape で描く
より複雑な例 "fantasy landscape with a [mountain:lake:0.25] and [an oak:a christmas tree:0.75][ in foreground::0.6][ in background:0.25] [shoddy:masterful:0.5] "(ステップ数は 100)
| ステップ | プロンプト |
|---|---|
| 01~25 | fantasy landscape with a mountain and an oak in foreground shoddy |
| 26~50 | fantasy landscape with a lake and an oak in foreground in background shoddy |
| 51~60 | fantasy landscape with a lake and an oak in foreground in background masterful |
| 61~75 | fantasy landscape with a lake and an oak in background masterful |
| 76以降 | fantasy landscape with a lake and a christmas tree in background masterful |
Alternate Prompt(1ステップごとに語を切り替え)
[parrot|owl] というプロンプトは奇数ステップは parrot、偶数ステップは owl になる。
[parrot|owl|cow] の場合は、1ステップごとに parrot と owl と cow が順に切り替わっていく。
外部リンク
BREAK(プロンプト分割)
プロンプト中に BREAK を入れると 75 トークンになるように残りを埋めてくれる。自然言語でプロンプトを書く人向けの機能。
75 トークンを超えるプロンプトは以下のように分割して結合される。
- 75 トークンごとにプロンプトを分割
- 分割されたプロンプトをそれぞれ CLIP に通して embedding に変換
- embedding を結合
AUTOMATIC1111 はなるべく、コンマやピリオドの位置でプロンプト分割するようになっている。なので danbooru タグでプロンプトを書く場合は、分割位置は問題にならない。
しかし自然言語でプロンプトを書く場合は、その分割位置によっては意図しないプロンプトになる。たとえば red hair の red の後でプロンプトが分割された場合、髪は赤くならない。このような場合に、きりのいい場所に BREAK を入れることで、プロンプトの意図しない分割を防げる。
Booru tag autocompletion for A1111(タグ補完)
Extensions からインストールできる。プロンプト入力時に danbooru タグを補完してくれる。
dynamic prompt
Extension でインストールできる。プロンプトをランダム選択する。
- {A | B | C} : A, B, C の中のどれかがランダムに選択される
- {2$$A | B | C} : A, B, C のうちのどれか2つが選択される
- {1-3$$A | B | C}:A, B, C のうちのどれか1~3つが選択される
- {2$$and$$ A | B | C}:A, B, C のうちどれか2つが選択され、カンマではなく and で結合される。例 C and A
variables
男女同数にするには以下のようにする。
${num=!{3|4|5|6}} ${num}boys, ${num}girls
wildcards
extensions/sd-dynamic-prompts/wildcards にプロンプトを書いたテキストファイルを置くと、そのファイルからランダムにプロンプトを選択する。たとえば以下のような color.txt の場合はプロンプトに __color__ を入れると機能する。
red blue green
空白行と # で始まる行は無視される。
1行だけ書いたファイルを用意してマクロ代わりに使う方法もある。
wildcards は dynamic prompt と合わせて使うと便利だ。以下のプロンプトは adjective.txt の中から2~4つランダムに選択して and で結合する。
a photo of a {2-4$$and$$__adjective__} house
wildcards は再帰もサポートしている。txt ファイルに {A | B} や __color__ を入れると、それを展開して実行する。
ワイルドカード
python の glob で使えるワイルドカードが使える。
__color*__ とすると以下のようなファイルとマッチする。
- color.txt
- color1.txt
- nested/folder/colors1.txt
__light/**/*__ とすると以下のようなファイルとマッチする。
- nested/folder/light/a.txt
- nested/folder/light/b.txt
[0-9] (0から9までの任意の数字一文字)や [a-z] (a から z までの任意の一文字)や ? (任意の一文字)が使える。
Combinatorial generation
すべての組み合わせのプロンプトで画像を生成する。
text2prompt
data フォルダに入っている danbooru タグの説明文と入力したテキストとのコサイン類似度を計算して、その結果をもとにプロンプトを生成する。
ファインチューン
学習についてはStable Diffusion のファインチューンの Tips を参照。
Embedding (.pt や .bin ファイル)を使う
Embedding は .pt や .bin ファイルで提供される。それらを embedding フォルダにいれて、プロンプトにファイル名を入れると使える。たとえばファイル名が〇〇だったとすると、プロンプトに "portrait of 〇〇" とすると使える。再起動不要。
Embedding はトレーニングされたモデルで使わないと意味がない。Waifu Diffusion で学習したデータを Stable Diffusion で使っても意味がない。
CLIP Aesthetic
インストール
以下のコマンドを実行する。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients extensions/aesthetic-gradients
使い方
embedding を models/aesthetic_embeddings 入れると、txt2img タブの Open for Clip Aesthetic で設定できる。
サンプルファイルが vicgalle/stable-diffusion-aesthetic-gradients/aesthetic_embeddings からダウンロードできる。サンプルの作例は vicgalle/stable-diffusion-aesthetic-gradients で見れる。
Aesthetic steps
最適化ステップの実行回数。2や3ぐらいから始めて少しずつ大きくしていく。大きくするほど embedding の影響が強くなる。
Aesthetic learning rate
最適化の学習率。デフォルトの 0.0001 から動かす必要はない。
外部リンク
Using Aesthetic Images Embeddings to improve Dreambooth or TI results #3350
【NovelAI】开源的WebUI即将引入重磅更新,大幅提升图像品质
Hypernetwork を使う
models フォルダに hypernetwork フォルダを作成しそこに pt ファイルを配置する。たとえば test.pt を使用する場合はプロンプトに以下のようなテキストを配置する。
<hypernet:test:1.0>
Lora を使う。
Lora ファイルの配置場所
Lora の safetensors や pt ファイルを models/lora に配置する。
Lora ファイルの適用
test.safetensor を使用する場合はプロンプトに以下のようなテキストを配置する。
<lora:test:1.0>
GUI から Lora ファイルの適用
Generate の下の花札🎴のアイコンをクリックして、適用する Lora ファイルをクリックするとプロンプトに自動的にテキストが配置される。閉じる場合はもう一度花札🎴のアイコンをクリックする。
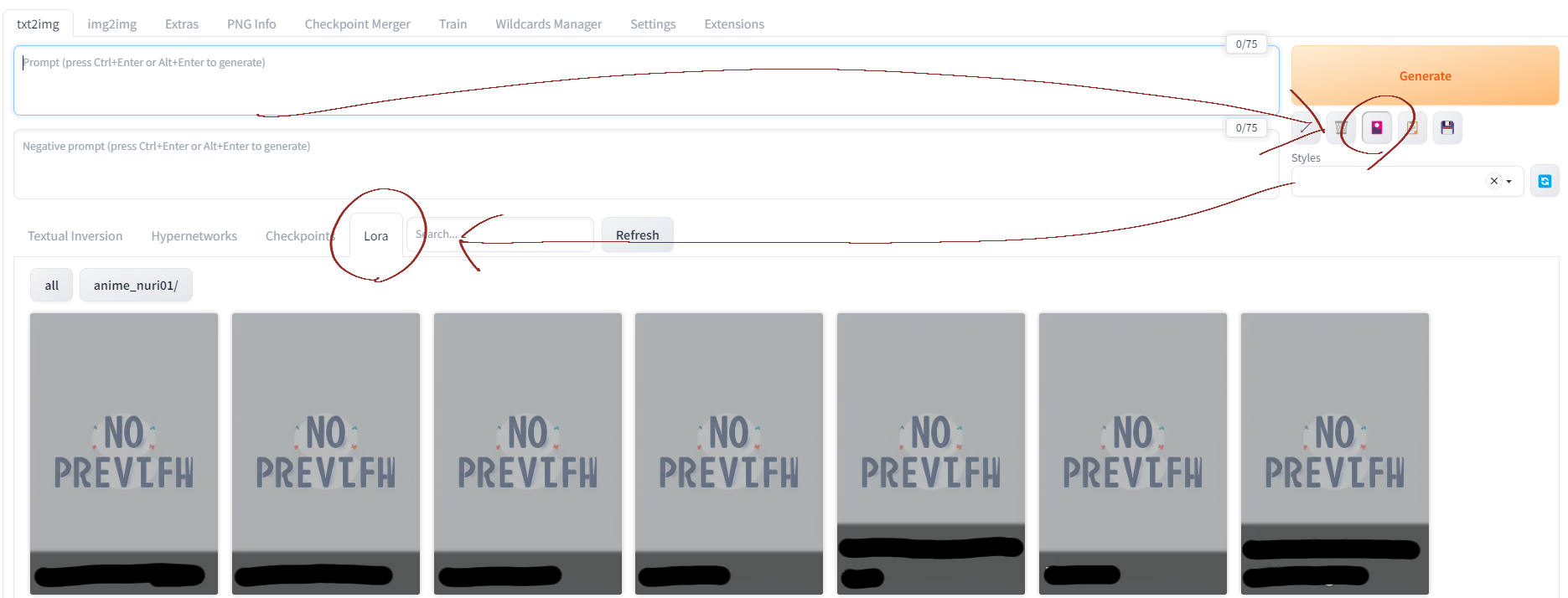
Lora と同じ名前の画像ファイルを配置すると、サムネが表示される。
Lora と同じ名前のテキストファイルを配置すると、Lora 名の下にそのテキストが表示される。トリガーワードを書いておくと便利。
Extension からインストールできる sd-webui-additional-networks は GUI で、使用する Lora を編集できる。この Extension を使う場合は、Lora ファイルを extensions/sd-webui-additional-networks/models/lora に配置する。
locon と loha を使う
Extension の a1111-sd-webui-locon をインストールすれば、Lora と同じ方法で使用できる。
Lora を使うと画像がガビガビになる
CFGスケールを3~4程度に下げる。
VAE を使う
自動選択
○○.ckpt のある場所に ○○.vae.pt という名前に変更した VAE を配置する。
手動選択
models/vae に *.vae.pt を配置する。Settings の SD VAE で VAE を選ぶ。
VAE リンク
検証
X/Y plot(パラメーターの検証に使う)
Script の X/Y plot で使える。プロンプトやサンプラーや CFG スケールを変化させたときに画像がどう変化するのかを、実際に画像を生成して検証できる。
Prompt S/R は最初の語がプロンプト内に含まれている必要がある。たとえば "masterpiece, best quality, dog" というプロンプトで dog を cat や cow に変化させるには、以下のように設定する。シードは何でもいい。
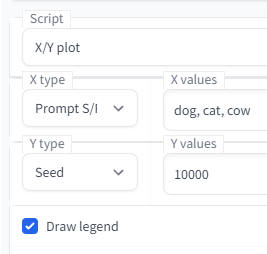
dog と cat でプロンプトを検証
シードステップ
シードは範囲とステップとを指定できる。たとえば 1000-10000(+1000) と書くと 1,000 から 10,000 まで 1,000 刻みで出力してくれる。
Prompt matrix
プロンプトの末尾を変えた時の比較ができる。プロンプトの一部を変えたい場合は、X/Y plot の Prompt S/R を使う。 以下の例では画像が4枚作成される。
a busy city street in a modern city | illustration | cinematic lighting
- a busy city street in a modern city
- a busy city street in a modern city, illustration
- a busy city street in a modern city, cinematic lighting
- a busy city street in a modern city, illustration, cinematic lighting
| の数の2乗の枚数の画像が作成される |
|---|
Visualize Cross Attention(プロンプトが画像のどこに効いているか可視化)
Extension としてインストールする。
使用方法
VXA タブで使える。画像とプロンプトとトークンとを指定して Visualize Cross-Attension を押す。トークンを指定するのは、カンマや and などの不要なトークンの影響を除外するため。プロンプトは画像を生成したプロンプトではなく、影響を知りたいプロンプトを指定する。
トークンを指定するのが面倒なので1語ずつ使うことになるだろう。Extension で Tokenizer を入れると、トークン分割を可視化できる。
例
- Prompt:hat and neck
- Indices of tokens to be visualized:1, 3
画像サイズは 256 の累乗である必要がある。
Cross-attention layer
可視化する Cross-Attention 層。以下の層が影響力が分かりやすい。
- model.diffusion_model.middle_block.1.transformer_blocks.0.attn2
- model.diffusion_model.output_block.3.1.transformer_blocks.0.attn2
Stable Diffusion は画像を 64x64 の潜在表現に変換した後、32x32、16x16 とダウンサンプルして、64x64 にアップサンプルする。最も低解像度の middle_block が分かりやすいのでデフォルトになっている。
DAAM との違い
- DAAM は画像生成時にしか使えない
- DAAM は可視化したいワードの指定がやりやすい
- DAAM は複数のワードを一度に指定できる
DAAM Extension for Stable Diffusion Web UI(プロンプトが画像のどこに効いているか可視化)
Extension としてインストールする。Script で Daam script を選択する。
Attention texts for visualization. (comma separated) に可視化したいワードをカンマ区切りで入力する。ワードごとにヒートマップが作成される。() がついていると機能しない。プロンプトが (masterpiece) の場合は、Attention texts に masaterpiece を入力する。
Visualize Cross Attention との違い
- VCA は作成した画像に対して行うので AI 作成でない画像に対しても機能する
- VCA は Cross-Attention Layer によって影響力が違うので分かりづらい
- VCA はトークンで指定するので面倒
高速化
532.03 以降の GeForce ドライバを使う
GeForce RTX 3050 で以下の設定で 1056 x 1408 の画像を作成した際の時間は、86 秒から 54 秒に短縮(37%高速化)された。
- 384 x 512
- upscale 2.75
- DPM++ 2M Karras
- steps 20
速度低下問題
532.03 以降の GeForce ドライバの中には VRAM が少なくなると、DRAM を使用することで速度低下を引き起こすものがあった。
546.01 ではユーザーがこの挙動を制御できるようになっている。
設定
546.01 のNVIDIA コントロールパネルで「3Dの設定 > 3D設定の管理 >CUDA - System Fallback Policy」を Prefer No System Fallback にすると、DRAM を使用しなくなる。
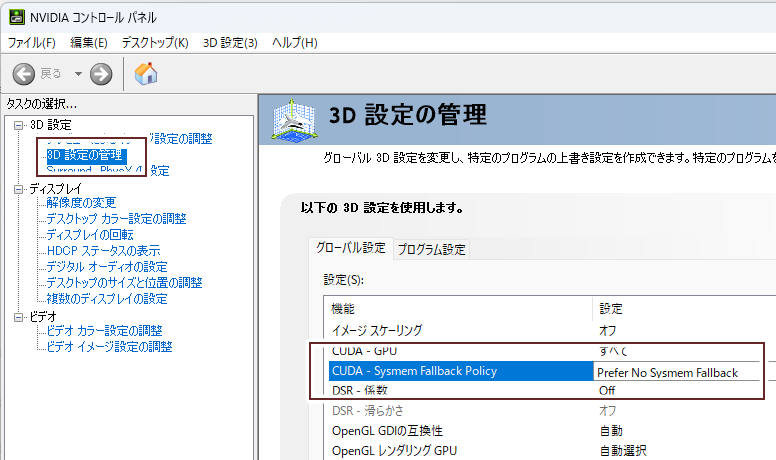
設定
外部リンク
NVIDIA RTX環境での「Stable Diffusion」はVRAMを使い果たすとDRAMも使えるが、逆にVRAMだけにもできる
System Memory Fallback for Stable Diffusion
xformers(高速化)
--xformers オプションを有効にすると 30% 以上高速化する。出力される画像は少し変わる。成功すると起動時の PowerShell の画面に Launching Web UI with arguments: --xformers と表示される。RTX 3050 で xformers を有効にすると以下のような結果になった。サンプラーは Euler a。
| 解像度 | 速度(it/s) |
| 512x512 | 4.5 |
| 512x768 | 3.0 |
| 1024x1024 | 0.7 |
インストール時の注意点
xformers は Python 3.10 以上でないと動かない。Python 3.8 で動かそうとすると ModuleNotFoundError: No module named 'xformers' が出る。
Python 3.10 をインストールしているのに認識しない場合は webui-user.bat を以下のように編集する。
set PYTHON=C:\Users\あなたのユーザー名\AppData\Local\Programs\Python\Python310\python.exe
使い方
- webui-user.batを編集して、set COMMANDLINE_ARGS=--xformer にする
- webui-user.batから起動する
外部リンク
Building xFormers on Windows by @duckness
Token Merging (ToMe) for SD
不要なトークンをマージすることで transformer を高速化する。
バージョン 1.3.0 以降で拡張機能から本体へ取り込まれた。Settings > Optimizations の Token merging ratio で設定できる。
外部リンク
Token Merging (ToMe) for SD - possible 2x speedup #9204
Token Merging for Stable Diffusion
Token Merging for Fast Stable Diffusion
ライブプレビューを切る
Settings タブの Live Previews タブの Show live previews of the created image のチェックを切る。
xformers と tome が有効な場合、差はほとんどない。
外部リンク
Stable Diffusion高速化技術続々登場!TensorRT、SSD-1B、LCMなどを試してみる
HyperTile
U-Net と VAE の self-attention layer を最適化し、10 %程度高速化する。Settings の Hypertile から設定できる。
パラメータの設定例はこちらを参照。
外部リンク
support HyperTile optimization #13948
Latent Consistency Model
LCM は元のモデルを蒸留して、少ないステップ(4~8ステップ)で画像を生成するバージョンに変換する。
Latent Consistency Model Consistency Models: 1~4stepsで画像が生成できる、新しいスコアベース生成モデル
LCM LoRA
Stable Diffusion高速化の決定版登場!?品質落とさず制限もほぼなしで2~3倍速に
fastsdcpu
そのほか
出力画像が真っ黒になる
起動オプションの --no-half-vae を追加すると大抵は直る。
ただし VAE で VRAM を余計に消費するため生成可能解像度が小さくなる。たとえば VRAM8GB で --no-half-vae が有効な場合 1,500 x 1,000 程度が最大解像度だが、--no-half-vae がない場合はフルHDの画像を生成可能。
Extensions(追加機能)
Extension タブでインストールできるようになった。Available タブで Extensions を選択してインストールできる。
メタデータにモデル名を追加
Settings タブの User Interface の Add model name to generation information。
任意解像度
スライダーではなく数値を直接入力すると任意解像度で画像を生成できる。
Stable Diffusion 2.0
- 768-v-ema.ckpt を models/Stable-Diffusion に配置
- yaml ファイルを ckpt と同じ名前(768-v-ema.yaml)にして models/Stable-Diffusion に配置
- UI から選択
使用する GPU の選択
webui-user.bat に set CUDA_VISIBLE_DEVICES=0 や CUDA_VISIBLE_DEVICES=1 と追加すると使用する GPU を選択できる。
--device-id コマンドライン引数で CUDA デバイスを選択できる。
Variations
同じシードでもちょっと違う絵を再生成できる。場所は Extra。
たとえば「Variation seed -1、Variation strength 弱め」にするとちょっと違う絵になる。
Checkpoint Merger
ckpt ファイルをブレンドする機能。models/Stable-Diffusion フォルダにブレンドしたい ckpt ファイルを置いて、実行するだけ。
Add difference の使い方
Add difference は Dreambooth や追加学習の内容を抽出する時に使う。たとえば Waifu Diffusion の学習内容を抽出して Easter に追加したければ、Easter + (Waifu Diffusion - Stable Diffusion v1.4) を実行する。
user.css
webui.py の場所に user.css を作成すると UI のレイアウト等を変更できる。
/* ギャラリーの高さを変更する */
#txt2img_gallery, #img2img_gallery{
min-height: 768px;
}
Interrupt
Interrupt ボタンを押すと現在の処理を中断できる。
4GB の VRAM で実行
4GB の VRAM で 512px * 512px の画像が生成できる機能。
--lowvram はモデルをモジュールに分割して、必要なモジュールのみ VRAM に展開することでメモリ使用量を節約している。ステップごとに大量のデータ転送が必要になるためとても遅い。RTX 3090 でこのオプションを有効にすると 10 倍遅くなる。
--medvram は同一バッチ内で conditional denoising と unconditional denoising を行わないことでメモリ容量を削減している。
--medvram-sdxl
バージョン 1.6.0 で --medvram-sdxl が追加された。これは SDXL のモデルを読み込むときのみ medvram の動作になる。
ロードの進捗表示
Gradio のローディング表示は遅い。これを切ると RTX 3090 で 10% 高速になる。現在はデフォルトで非表示になっている。
コマンドラインオプションの --no-progressbar-hiding を使うと表示できる。
Png へデータの埋め込み
埋め込まれたデータはPNG file chunk inspectorで確認できる。
最新版では jpg へのデータ埋め込みもサポートしている。
ローカルネットワーク(スマホ)から UI にアクセス
--listen をつけて webui-user.bat を起動する。詳細はStable Diffusion Web UI(AUTOMATIC1111版)を導入したのとWaifu DiffusionやTrinArtのモデルを使ってみたのと【AI画像生成】#スマホからでもアクセスできるようにを参照。
通知音を鳴らす
notification.mp3 を AUTOMATIC1111 のフォルダに入れておけば、画像生成時に鳴らしてくれる。
Settings
UI で設定できる項目の半数以上はコマンドラインでも設定できる。その設定値は config.js に保存されている。
ファイル名タグ
Images filename pattern でファイル名を設定できる。以下のタグが使える。
[steps], [cfg], [prompt], [prompt_spaces], [width], [height], [sampler], [seed], [model_hash], [prompt_words], [date], [model_hash]
アップデートによりタグは追加される。実際に使えるタグは"Images filename pattern" ラベルの上にマウスカーソルを持っていくと表示されるウインドウで確認できる。
[prompt_spaces] は生のプロンプト。[prompt_words] は単純化されたプロンプト。
例:s=[seed],p=[prompt_spaces]
UI
日本語化
Extensions タブで言語ファイルをインストールした後、設定で有効にする。
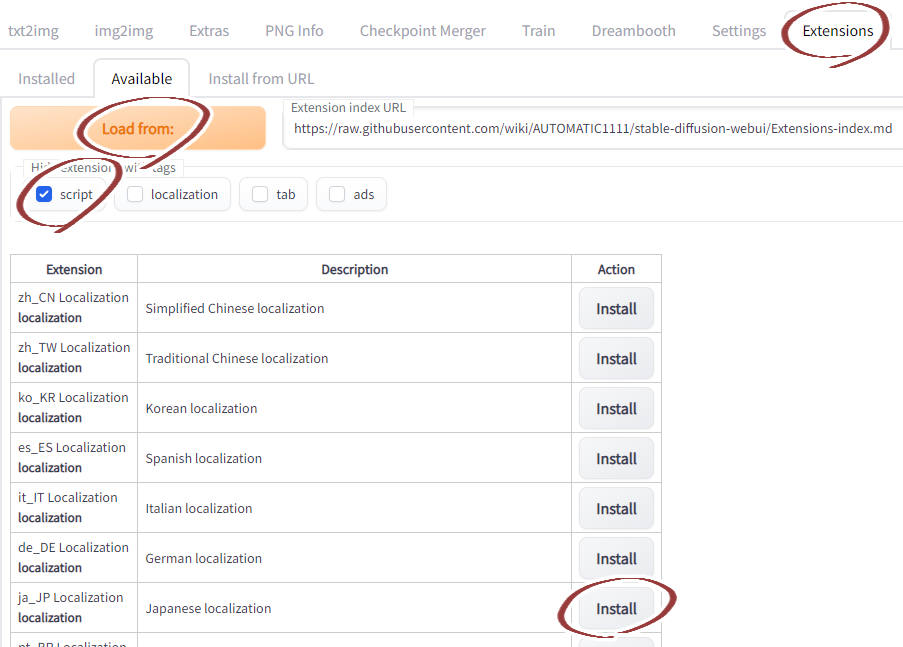
言語ファイルのインストール
- Settings タブの User interface の Localization (requires restart) で ja_JP を選択
- 画面上の Apply settings を押す
- 画面下の Restart Gradio and Refresh components を押す
ダーク UI
http://127.0.0.1:7860/?__theme=dark にアクセスする。
ui-config.json
ui-config.json はラジオグループのデフォルト値やチェックボックスのデフォルト値、テキストや数値のデフォルト値を設定できる。
一度に生成する画像の枚数等の設定も変更できる。一度の生成する画像の枚数は "txt2img/Batch count/maximum": で変更できる。
コマンドラインが使えるなら --ui-config-file でカスタム設定ファイルを読み込むことも可能。
AnimeDiff
AnimateDiff for Stable Diffusion Webui
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Controlnet
Reference-Only(参考画像を基にイラスト作成)
Reference-Only は追加のモデル不要(Preprocessor で reference_only を選択するだけ)で、参考画像を与えるだけで使える。
インペイントと違い、画像がめちゃくちゃにならない。
影響力を強くするには、Style Fidelity を1にして、Control Mode を ControlNet is more important にする。
外部リンク
[Major Update] Reference-only Control #1236
[Major Update] Reference-only Control #1237
MLSD
MLSD は直線を抽出して背景を描かせるのが主な使い道だ。しかし、コマ画像を入力すれば漫画のような画像を出力させられる。Regional Prompter を併用すればコマごとにプロンプトを指定することも可能。

コマ画像

prompt: comic, the city on the coma, 1girl sitting in the room, 2girls talking
negative: monochrome, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
ADetailer prompt: highly detailed eyes, simple high light
Controlnet Preprocessor mlsd, Model control_canny-f16
モデルマージ
[実験レポ] Model Block Merge で、 U-Net の各レイヤーの影響を調べる #1
Merge Block Weighted - GUI(U-Net のブロックごとにマージ比率を変える)
modify_middleblock.py(attn2 を attn1 に変更して SelfAttention にする)
ツール
stable-diffusion-webui-dumpunet
U-Net の特徴量を可視化するための stable-diffusion-webui の拡張。
モデルマージでテキストエンコーダーが壊れる
モデルが壊れる現象、再現できました
— 白月めぐり (@alice_diffusion) December 29, 2022
層別マージ関係なく、普通のマージでも壊れます
Add differenceでマージしたモデルを、さらに別のモデルとWeighted sumでマージすると壊れるようです
一時期流行った〇〇mixみたいなモデルや、さらにそれを混ぜた物は高確率で壊れてると思います#AIイラスト https://t.co/CuZKMQaGqW pic.twitter.com/dKh0T6k9c3
壊れたモデルのtext_encoderを直す方法は2つ
— 白月めぐり (@alice_diffusion) December 29, 2022
・モデルをfp16化する。マージでAとB両方に壊れたモデルを突っ込んで、(M)を0にしてsave as float16する
・層別マージで正常なモデル(A)と壊れたモデル(B)を入れ、ALL_Bでbase_alphaだけ0に指定してマージする
お好みの挙動の方でどうぞ#AIイラスト https://t.co/CuZKMQaGqW