ControlNet のネットワーク構造
ControlNet は追加のネットワークを挿入するタイプのファインチューン技法だ。ControlNet のネットワークは U-Net の IN と MID のコピーで、学習開始前の状態ではウェイトも丸々コピーする。
通常は U-Net にノイズ画像を入力してデノイズするように学習させる。しかし ControlNet の入力には目的タスクに応じて線画画像や棒人間などを入力して、コピーした U-Net の IN と MID を学習させる。
他のファインチューン技法との比較
ControlNet は U-Net の IN ブロックに追加情報を注入するようネットワークを変更するので、Hypernetwork や LoRA とは使い勝手が違う。
| 技法 | ネットワークの挿入位置 |
|---|---|
| Hypernetwork | Attention ブロックの k, v の前 |
| LoRA | Attention ブロックの q, k, v, o の全結合層と並列接続 |
| ControlNet | U-Net の OUT ブロックに出力を注入 |
ControlNet のネットワーク
下の図で x はノイズ画像、c は輪郭画像や棒人間の画像などのタスク特有の画像だ。neural network block (locked) は U-Net の IN と MID ブロック。ControlNet では trainable copy と zero convolution をチューニングする。
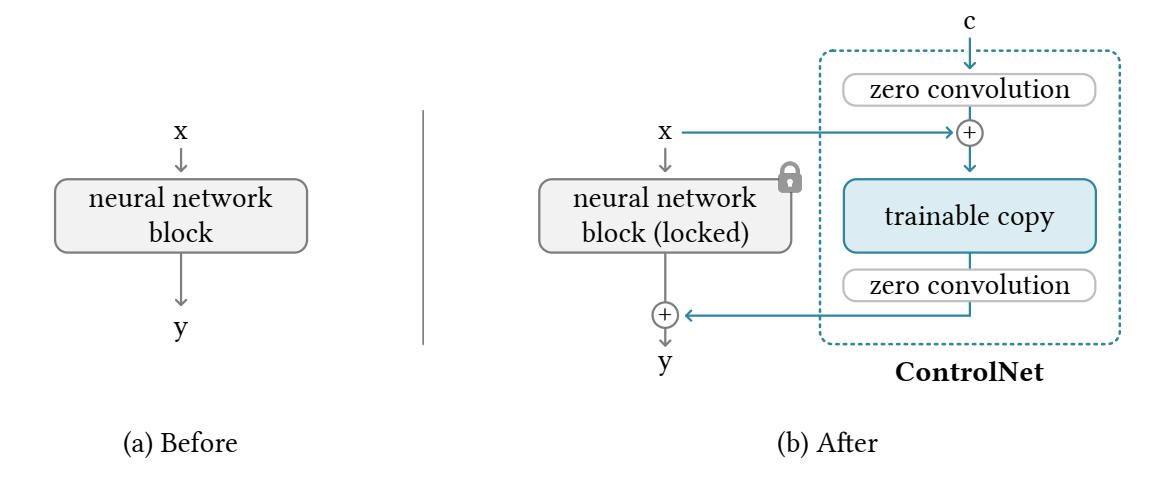
出典:Lvmin Zhang, Maneesh Agrawala (2023), Adding Conditional Control to Text-to-Image Diffusion Models, ArXiv
zero convolution
バイアスとウェイトとの初期値が0で初期化された 1x1 の畳み込みレイヤー。学習によってウェイトを獲得する。初期値が0なので、一番最初の学習時に出力に影響を与えない
c と x の次元の違い
Stable Diffusion は潜在空間(64 x 64)でデノイズを行うので、c の次元を一致させるための畳み込みレイヤー(4 x 4 カーネル, 2 x 2 stride, ReLU)が配置されている(図には描かれていない)。
詳細図
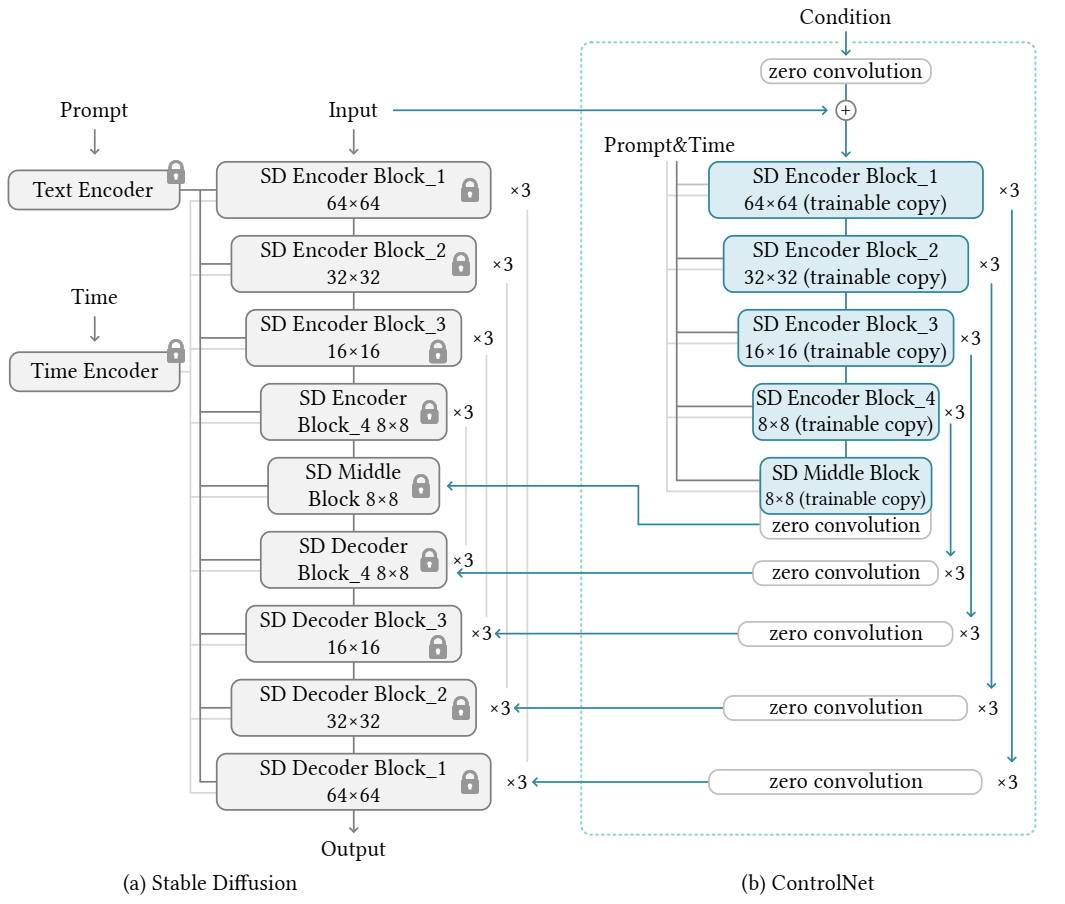
出典:Lvmin Zhang, Maneesh Agrawala (2023), Adding Conditional Control to Text-to-Image Diffusion Models, ArXiv
外部リンク
Adding Conditional Control to Text-to-Image Diffusion Models