T2I 拡散モデルの設計メモ
目次
- 概要
- クラウド GPU
- テキストエンコーダー
- VAE
- GAN
- コンディショニング
- 位置埋め込み
- 目的関数
- Transformer アーキテクチャ
- Transformer を使わないアーキテクチャ
- Gated MLP
- ブロック図
- データセット
- キャプショニング
- スケジューラー
- 学習方法
- Classifier Free Guidance
- Adaptive Projected Guidance
- Reinforcement Learning Guidance
- タイムステップスケジューラー
- ノイズスケジューラー
- 蒸留
- 画像編集
- 省メモリ学習
- 性能検証
- 高速化
- ワーキングメモリー
- 教師ありファインチューニング
- 強化学習
- 丸暗記の仕組み
概要
拡散モデルのまとめは The Principles of Diffusion Models を参照。
クラウド GPU
ローカルでスモールモデルの検証を行い、本番はクラウドを使うのがコスパがよい。Runpod は先払いも選択でき、過払いの心配がない。
H100 や B200 のような業務用 GPU なら NEBIUS や Lambda がある。
料金は以下の3つの合計であることに注意する。少額の利用の場合、ストレージ料金や通信料の方が高額になりやすい。
- GPU のレンタル料金
- ストレージ利用料
- 通信料
| サービス名 | 最小チャージ金額 | A6000 48GB/hr | A5000 24GB/hr |
|---|---|---|---|
| runpod | $10 | $0.33 | $0.27 |
| vast.ai | $5 | $0.40 | $0.17 |
| CUDO | $0.40 | $0.29 | |
| OBLIVUS | $0.55 | ||
| Lambda | $0.80 |
テキストエンコーダー
CLIP や T5 が長らく使われてきたが、軽量 LLM を使うケースが増えている。
テキストエンコーダーのトークンの次元は重要だ。小さい拡散モデルはトークンの次元を小さくすることが多い。拡散モデルのトークンの次元を削減すると、テキストエンコーダーのトークンの次元も Linear 等で削減する必要があり、テキストの追従性が低下する。
| LLM・VLM | モデル |
|---|---|
| phi-3 | OmniGen |
| Qwen2.5-VL-3B-Instruct | OmniGen2 |
| Qwen2.5-VL-7B-Instruct | Qwen Image |
| Qwen3-VL-4B-Instruct | Z-Image |
| Gemma 2 | Lumina-Image 2.0, SANA |
| Llama3-8B | Playground v3 |
主な LLM と VLM
Is GPT-OSS Good? A Comprehensive Evaluation of OpenAI's Latest Open Source Models によると 120b より 20b の方が LLM の評価に使われる複数のベンチで性能が良い。gpt-oss-20b より Gemma 3 27b の方が性能が良い。phi-4-reasoning は 14b で gpt-oss-20b や Gemma 3 27b を上回るスコアを出してる。
Unsloth を使うと省メモリで LLM を学習できる。OpenAI GPT-OSS 20Bモデルのファインチューニング完全ガイド。
性能比較
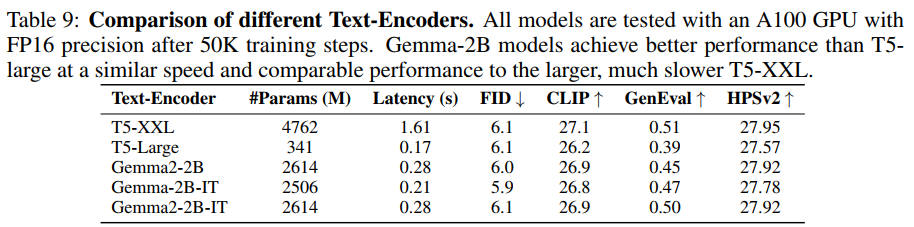
Params(M) は間違いで、数値は FP32 精度の時のファイルサイズ
出典:SANA: Efficient High-Resolution Text-to-Image Synthesis with Linear Diffusion Transformers. Enze Xie et al. Table 9. https://openreview.net/forum?id=N8Oj1XhtYZ
むしろ T5-Large がコスパがよい。fp16(性能劣化なし)だと 1.6GB、GGUF Q8_0 量子化すると 900MB になる。
T5-XXL を使うよりは軽量 LLM の方が速いし性能もよい。
T5 と LLM を混ぜて使う場合は注意が必要だ。T5 は LLM に比べて出力の分散が小さい。なので LLM の出力に RMSNorm などの Normalization レイヤーが必要になる。
参考文献
Unified Multimodal Understanding via Byte-Pair Visual Encoding。画像にも byte-pair encoding を適用する。
VAE
なぜ KL VAE を使うのか
潜在空間の統計的制御(規則性)
KL loss を入れることで、潜在空間に意味的なスムーズさや構造性が生まれる。以下のような特徴を持つ潜在空間は拡散モデルにとって扱いやすい。
- 同じ意味を持つ画像は近い z にエンコードされる
- ノイズを加えてもデコーダーが画像として再構成しやすい
- 正規分布に従うことで、サンプリング可能な「全体的に埋まった」潜在空間になる
VAE のトリレンマ
以下の3つを同時に満たす VAE を作成するのは難しい。
- 拡散モデルの解釈容易性。latent が解釈しやすく圧縮されていると拡散モデルの性能が上がる
- 再構成品質
- 圧縮率
圧縮率を上げると品質は下がる。
VAE の再構成品質を上げると解釈容易性が下がり、拡散モデルの性能が下がる。
解釈容易性を上げるには
- チャンネルサイズを小さくする。すると圧縮率は犠牲になる
- KL 正則化を上げる。すると画像がボケる
- 現在の最適解は REPA や DINOv2 で正則化すること
詳細は FLUX.2 VAE を参照。
VAE の圧縮率
VAE の圧縮率を決めるパラメータは2つある。
- F:解像度の縮小率
- C:潜在空間のチャンネル数
拡散モデルの隠れ層の次元はさらにパッチサイズが関係している。
- P:パッチサイズ
VAE の隠れ層の次元数は以下のようになる。
\[{H \times W \times 3 \rightarrow \dfrac{H}{F} \times \dfrac{W}{F} \times C}\]拡散モデルの隠れ層の次元は以下のようになる。
\[{H \times W \times 3 \rightarrow \dfrac{H}{PF} \times \dfrac{W}{PF} \times (C \times P^2)}\]各 VAE の設定
| モデル | F | C | P |
|---|---|---|---|
| SD1.5 | F8 | C4 | P2 |
| SANA | F32 | C32 | P1 |
| SDXL | F8 | C4 | P2 |
| Dit-Air | F8 | C8 | P2 |
| SD3 FLUX.1 Lumina-Image-2.0 Qwen Image | F8 | C16 | P2 |
| モデル | エンコーダー パラメータ数 | デコーダー パラメータ数 |
|---|---|---|
| SD3 FLUX.1 Lumina-Image-2.0 | 34M | 50M |
| Qwen Image | 54M | 73M |
Transformer の隠れ層の次元 >> C なので、既存の VAE の P を大きくすれば、トークン数が減るので拡散モデルの処理速度を向上させられる。
DC-AE 1.5 の論文で述べられているように、VAE のチャンネル数を上げると VAE の性能は上がるが、DiT の性能は低下する傾向にあった。VAE の性能を上げつつ、DiT が解釈しやすい latent のデータ構造をとるように VAE を学習するのは難しい。詳細は DC-AE 1.5 の論文を参照。
SD-VAE・FLUX.1 VAE のレイヤー情報
Notes / Links about Stable Diffusion VAE
SDXL の VAE のレイヤー情報は sdxl-vae/config.json を参照。
SD3 の VAE や FLUX.1 の VAE にアクセスするには認証が必要。
Diffusers で様々な VAE の実装が見れる。
SD や FLUX は Diffusers の AutoencoderKL を使用しているので以下のコードで簡単にモデルを構築できる。学習するコードも 100 行程度あれば可能。block_out_channels は最終的には [128, 256, 512, 512] を使うことが多い。
AutoencoderKL を定義するコード
from diffusers.models import AutoencoderKL
F = 8
C = 16
resolution = 1024
model = AutoencoderKL(
sample_size=resolution,
in_channels=3,
out_channels=3,
latent_channels=C,
block_out_channels=[
int(resolution/F),
int(resolution/4),
int(resolution/2),
int(resolution/2)
],
layers_per_block=2,
down_block_types=[
"DownEncoderBlock2D",
"DownEncoderBlock2D",
"DownEncoderBlock2D",
"DownEncoderBlock2D"
],
up_block_types=[
"UpDecoderBlock2D",
"UpDecoderBlock2D",
"UpDecoderBlock2D",
"UpDecoderBlock2D"
],
act_fn="silu",
scaling_factor=0.18215,
mid_block_add_attention=True
)
VAE を学習させるコード
# train
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')
model.to(device)
model.train()
for i, (x, labels) in enumerate(train_loader):
x = x.to(device)
# encode
posterior = model.encode(x).latent_dist
latent_representation = posterior.sample()
# decode
# tanh で出力の範囲を [-1, 1] に制限
reconstructed_x = torch.tanh(model.decode(latent_representation).sample)
# loss
reconstruction_loss = F.mse_loss(reconstructed_x, x, reduction="sum")
kl_loss = torch.mean(posterior.kl())
vae_loss = reconstruction_loss + kl_loss
# back propagation
optimizer.zero_grad()
vae_loss.backward()
optimizer.step()
パッチサイズは小さい方が拡散モデルの性能が良い
パッチサイズは VAE の性能とは関係がない。パッチ処理があると拡散モデルが余計な処理をしないといけないので、拡散モデルの性能がわずかに低下する。
ただし MicroDiT はパッチマスクを行う前に Patch-mixer でテキスト Embedding を取り込むことで性能を向上させている。
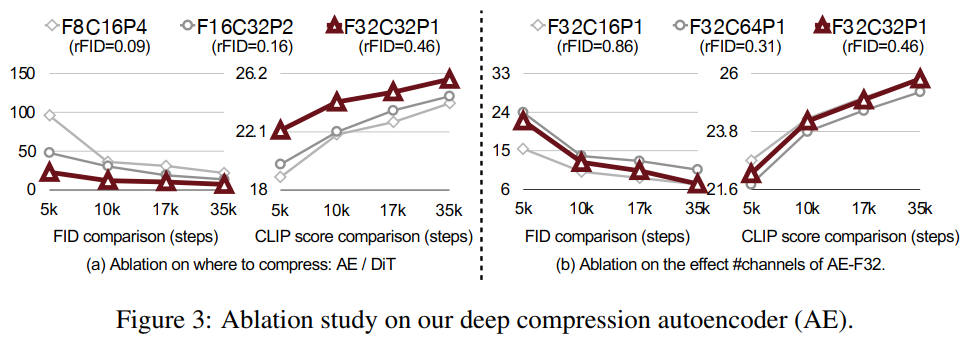
パッチサイズは小さい方が拡散モデルの性能が良い
出典:SANA: Efficient High-Resolution Text-to-Image Synthesis with Linear Diffusion Transformers. Enze Xie et al. Figure 3. https://openreview.net/forum?id=N8Oj1XhtYZ
UNILIP: ADAPTING CLIP FOR UNIFIED MULTIMODAL UNDERSTANDING, GENERATION AND EDITING
CLIP を2つ使い、片方を学習可能する。
D2iT
D2iT は圧縮率の異なる2つの潜在空間表現にエンコード可能な VAE を使う。ディティールの細かい部分は低圧縮率、情報の少ない部分は高圧縮率と使い分ける。デノイザもディティールの細かい部分は多くのネットワークが通過する。
DC-AE Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models
2025 年以降に発表された DiT でよく使われる。SANA や Nitro-T で使われている。space-to-channel, channel-to-space(要はパッチとアンパッチ)を学習可能な残差接続と、3段階の学習で性能を向上させる。
- 低解像度でエンコーダーとデコーダーを学習させる
- 高解像度でエンコーダーの終わりとデコーダーの入り口とのみを学習させる
- 高解像度でデコーダーの終わりのみを学習させる
DC-AE は dc-ae-f32c32-sana-1.1-diffusers からダウンロードできる。モデルの定義は efficientvit。
DC-AE 1.5: Accelerating Diffusion Model Convergence with Structured Latent Space
VAE の圧縮率とチャンネル数とにはトレードオフがあった。VAE の圧縮率を上げて性能を維持するにはチャンネル数を増やすしかない。そうすると VAE の性能は上がるが、拡散モデルの性能は下がる。これは VAE の潜在空間に構造情報が拡散して保存されないことが原因だ。
潜在空間に情報を構造化して保存させるために、潜在空間ベクトルをチャンネルごとにマスクして学習させた。例えば、C=128 とすると、0~127 の乱数を生成し、その数字以下のチャンネルを使ってデコードさせる。これによって、VAE 前半に構造情報、後半にディティールを保存するようにした。
augmented diffusion objectives(拡散モデルで実際にノイズを予測させた loss を使う)を導入することで学習を高速化した。
CoVAE: Consistency Training of Variational Autoencoders
FLUX.2 VAE
VAE の学習
VAE の学習は簡単ではない。VAE 単体ではぼやけた画像にしかならない。
Stable DiffusionのVAEは、LPIPS、パッチベースのGAN損失、およびMSE損失を含む複雑な損失関数を使用して訓練される。この組み合わせにより、VAEは、ピクセル単位で正確 (MSE)、知覚的に整合 (LPIPS)、かつ全体的にリアル (GAN損失) な、高品質でぼやけのない再構成を生成できる。
taming-transformers は LPIPS と GAN とを使用して VQ-VAE を学習させており、VAE の作成の時に参考になる。
VIVAT: Virtuous Improving VAE Training through Artifact Mitigation は VAE の学習でよく起こるアーティファクトの対処法を解説している。
Generative modelling in latent space
posterior collapse
VAE は同じ画像ばかり出力する posterior collapse(KL loss が急速に0に近づく)が起こりやすい。そこで以下のような戦略が良く使われる。
- KL Loss の逆伝播の量を調整する kl_beta を設定する。
- 最初の数万ステップは kl_beta を0にする。
- 次にウォームアップ区間を設ける。 kl_beta が 0→1 になる“ウォームアップ区間”は、実装・データ規模により 1 万〜10 万 SGD ステップ、あるいは 50〜200 エポック程度
- 各ピクセルの小さい loss を、ノイズとみなして、フィルターして無視する
- 各ピクセルの KL loss の最大値を設定する。max(KLi, threshold)
- ウォームアップ区間が短すぎると posterior collapse が起こりやすく、長すぎると訓練が停滞するため、近年では「1〜2% の総ステップ数をウォームアップに割く」か「 ELBO が安定するまでβを上げない」設計が主流
- 最低でも1万ステップのウォームアップ期間が必要。高解像度画像・映像用 VAE では 2.5〜5 万ステップ程度の長めのウォームアップが採用される傾向があり、テキスト VAE では 1〜2 万ステップ前後が多い
- posterior.mean を可視化して、すべて 0 近辺になっている場合、posterior collapse の疑いが強い
prior hole problem
VAE の潜在空間(latent space)において、事前分布(通常は標準正規分布)に従ってサンプリングした点が、まともな出力を生成できないことがあるという問題。エンコーダーが潜在空間 z の全体を使用していないことが原因。
対策
- VAE with a VampPrior
- KL loss の重みを適切に調整(例: KL annealing)
- beta VAE の β を高める(GAN や LPIPS を使わないと画像がぼける)
- デコーダーの能力を上げる(ただし posterior collapse が起こりやすくなる)
- Two-stage VAE などの構造的改良(例: hierarchical VAE)
正規化
画像の表示時や保存時に逆正規化を忘れるのはよくやりがちだ。
transforms.Normalize([0.5], [0.5]) # 訓練画像の正規化 x = (x * 0.5 + 0.5).clamp(0, 1) # 逆正規化
MSE 単体では目的関数として力不足
The reasonable ineffectiveness of pixel metrics for future prediction (and what to do about it)
- ぼやけた画像は MSE が小さいことが多い。ぼやけた画像は位置の微妙な変化にも対応できる
- 最尤推定は訓練データとは著しく異なるデータを生成してもペナルティがない
正則化項
- KL。KL VAE はオートエンコーダーに KL 正則化項を追加したもの
- LPIPS
- GAN
- Masked AutoEncoders
- EQ-VAE
- Watsonの知覚モデル。離散フーリエ変換 (DFT) 等を使い特徴を抽出。LPIPS より6倍高速で、省メモリ
- 輪郭情報。Unleashing the Power of One-Step Diffusion based Image Super-Resolution via a Large-Scale Diffusion Discriminator
- そのほかは画像比較手法まとめを参照
LPIPS
LPIPS の損失の計算をするコード
import lpips
# LPIPS の準備('vgg' or 'alex')
lpips_fn = lpips.LPIPS(net='vgg').to(device)
lpips_fn.eval() # 推論モード
for epoch in range(num_epochs):
for i, (x, labels) in enumerate(train_loader):
x = x.to(device)
# encode
posterior = model.encode(x).latent_dist
latent_representation = posterior.sample().float()
# decode
# [-1, 1] に正規化
reconstructed_x = torch.tanh(model.decode(latent_representation).sample)
# loss: MSE
reconstruction_loss = F.mse_loss(reconstructed_x, x, reduction="sum")
# loss: KL
kl_loss = torch.mean(posterior.kl())
# loss: LPIPS
# LPIPS に入力する画像は [-1, 1] に正規化されている必要がある
lpips_loss = lpips_fn(x_norm, reconstructed_x).mean()
# AMP を使う場合は lpips の計算中は AMP を無効にする
# with autocast('cuda', enabled=False):
# lpips_loss = lpips_fn(x.float(), reconstructed_x.float()).mean()
# 総合 loss
vae_loss = reconstruction_loss + kl_loss + lpips_lambda * lpips_loss
optimizer.zero_grad()
vae_loss.backward()
optimizer.step()
lpips の動作は以下のコードで検証できる。> 0.1 なら lpips は正常。
x_noise = x + torch.randn_like(x) * 0.1
x_noise = torch.clamp(x_noise, 0.0, 1.0)
x_norm = x * 2 - 1
x_noise_norm = x_noise * 2 - 1
lpips_test = lpips_fn(x_norm, x_noise_norm)
EQ-VAE: Equivariance Regularized Latent Space for Improved Generative Image Modeling
EQ-VAE は SD-VAE が同変性(equivariance)を持たないことに注目し、スケール・回転変換を使った正則化で高画質を実現した。入力を変換したものと、潜在空間表現を変換したものをデコードしたものとの再構成 loss をとる。
以下の式で $ \tau$ はスケール・回転変換、$ \mathcal{E}$ はエンコーダー。$ \mathcal{L}_{rec}$ は再構成 loss。$ \mathcal{L}_{reg}$ は KL loss。エンコーダーで変換する画像は、スケール・回転変換しないことに注意。
\[ \mathcal{L}_{EQ-VAE}(x, \tau) = \mathcal{L}_{rec}(\tau \circ \mathbf{x}, \mathcal{D}(\tau \circ \mathcal{E}(\mathbf{x}))) + \lambda_{gan}\mathcal{L}_{gan}(\mathcal{D}(\tau \circ \mathcal{E}(\mathbf{x}))) + \lambda _{reg}\mathcal{L}_{reg} \]潜在空間表現の回転と拡大縮小するコードは以下のようになる。潜在空間表現は3次元 [C, H, W] である必要がある。
import random
# 普通はスケールしてから回転させるが、このコードでは回転させてからスケールしている
def rot_scale(x, angle, size):
# x.shape = [B, C, H, W]
x_s = torch.nn.functional.rotate(latent, angle)
return torch.nn.functional.interpolate(
x_s,
size=size,
mode='bicubic', # 'nearest', 'bilinear', 'bicubic' などが選択可能
align_corners=False # デフォルトはFalse。Trueにすると端のピクセルのアライメントが変わる
)
angle = 90 * random.randint(0, 3) # angle = 0, 90, 180, 270
size = (random.uniform(0.25, 1.0), random.uniform(0.25, 1.0)) # sx, sy = 0.25~1.0
x_rs = rot_scale(x, angle, size)
latent_rs = rot_scale(encoder(x), angle, size)
reconstructed_x = decoder(latent_rs)
reconstruction_loss = F.mse_loss(reconstructed_x, x_rs, reduction="sum")
Latent Diffusion Models with Masked AutoEncoders
Masked Autoencoders に KL 項を追加して、潜在空間のスムースさ・知覚的圧縮品質・再構成画像の品質の3つの指標を同時に達成。Loss は以下の4つ。
- マスクしていない部分の再構成 loss
- マスク部分の再構成 loss
- マスクしていない部分の LPIPS loss
- マスクしていない部分の KL loss
対称形の ViT ベースのエンコーダーとデコーダーとを採用している。SD-VAE がファイルサイズ 320MB に対して VMAE は 43MB で、性能で SD-VAE を上回る。
F4C16 のモデルの処理は以下のようになる。Transformer の次元は dmodel とする。Transformer は Transformerエンコーダの単一の層(Multi-Head Self-AttentionとFeed-Forward Network) のみの torch.nn.TransformerEncoderLayer が便利。
- 元画像(3 x 512 x 512)
- 画像のパッチ化によるダウンサンプル(3 x 512 x 512)->(64 x 128 x 128)-> (16,384 x 64)
- Linear で隠れ層の次元を調整 (16,384 x 64) ->(16,384 x dmodel)
- Transformer
- Linear 等で ${\mu}$ と ${\sigma}$ とを計算(それぞれ(16,384 x 16))
- z をサンプリング(z.shape =(16,384 x 16))
- Linear(16,384 x 16)->(16,384 x dmodel)
- Transformer
- Linear で隠れ層の次元を調整 (16,384 x dmodel) -> (16,384 x 64)
- アンパッチ (16,384 x 64) -> (64 x 128 x 128)->(3 x 512 x 512)
Transformer VAE の設計
Transformer VAE は出力がブロック状になりやすい。原因は、Transformer のパッチ化と KL loss との2つ。
KL loss 対策
- ステップ数が十分か確かめる。ブロック感をなくすには 50 万ステップは必要
- β-VAE を採用し、ベータを抑え気味にする
パッチ化対策
- 学習可能な位置エンコーディングを使う
- VIVAT: Virtuous Improving VAE Training through Artifact Mitigation
- トランスフォーマーブロックは最低でも8は必要
- パッチ化に畳み込みを使いオーバーラップさせる
- デコーダーの最後に refiner の畳み込みを追加する
オーバーラップのサンプルコード
self.image_to_token_cnn = nn.Conv2d(
in_channels=3,
out_channels=model_dim,
kernel_size=patch_size,
stride=patch_size//2, # stride < kernel_size → オーバーラップあり
padding=patch_size//4
)Refiner のサンプルコード
self.reconstruction_refiner = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 3, kernel_size=3, padding=1)
)
# after rearrange
img = self.reconstruction_refiner(img)参考文献
Self-Guided Masked Autoencoder
Masked Autoencoders Are Scalable Vision Learners
MaskGIT: Masked Generative Image Transformer
MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis
Latent Denoising Makes Good Visual Tokenizers
MVAE のように入力画像をマスクした上に、潜在空間表現にノイズを乗せてデコーダーを学習させる。MVAE の loss に加えて GAN も使う。
補間ノイズ $ x' = (1-\tau)x + \tau \epsilon$ と加算ノイズ $ x' = x + \tau \epsilon$ とでは補間ノイズの方が性能がよかった。$ \epsilon(\gamma) \sim \gamma \cdot \mathcal{N}(\mathbf{0},\mathbf{I})$ で $ \gamma = 3$ が最も性能がよかった。加算ノイズはオリジナルのシグナルを損なわないようなショートカットが作成される恐れがある。それにも関わらず VAR では性能が改善されたが、SiT では性能は改善されなかった。
マスク率は 70~90% が性能が高い。マスク率をランダム化した方が性能が良い。
マスクと潜在空間ノイズとを併用すると VAR では性能が上がったが SiT では性能が上がらなかった。SiT の場合は、マスクはしなくてもいい。
エンコーダーをフリーズしてデコーダーを訓練させたところ性能が劣化した。つまり、エンコーダーの能力強化が VAE の性能を上げるうえで重要。
REPA-E
REPA-E: Unlocking VAE for End-to-End Tuning with Latent Diffusion Transformers REPA を使用し、VAE と拡散モデルとを同時に学習させることで、品質を向上させかつ学習速度も高速化する。
VAE 学習の参考文献
Community Training AutoencoderKL #894
Cyclical Annealing Schedule: A Simple Approach to Mitigating KL Vanishing (pdf)
Summary: Beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework
beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework
Taming Transformers for High-Resolution Image Synthesis
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric
Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models
ALVAE Adversarial Latent Autoencoders
AS-VAE Adversarial Symmetric Variational Autoencoder
A Loss Function for Generative Neural Networks Based on Watson's Perceptual Model
参考文献
Conditional VAE Semi-Supervised Learning with Deep Generative Models
Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models
VQ-VAE
VQ-VAE Neural Discrete Representation Learning
Generating Diverse High-Fidelity Images with VQ-VAE-2
SoftVQ-VAE: Efficient 1-Dimensional Continuous Tokenizer
Quantize-then-Rectify: Efficient VQ-VAE Training
Instella-T2I: Pushing the Limits of 1D Discrete Latent Space Image Generation。1次元バイナリ潜在空間に圧縮することで VQ-VAE 比で 32 倍の圧縮率を達成している。
VQ-Diffusion Vector Quantized Diffusion Model for Text-to-Image Synthesis。VQ-VAE は量子化されているので、小さなミスが大きな意味の変化へつながる恐れがある。VQ-Diffusion では Mask-and-replace という学習手法でその問題に対処している。
AR
DC-AR: Efficient Masked Autoregressive Image Generation with Deep Compression Hybrid Tokenizer
NextStep-1: Toward Autoregressive Image Generation with Continuous Tokens at Scale
GAN
GAN は拡散モデルの主要技術ではないが、VAE の学習や蒸留のときに必要になる。
GAN の学習についてはGAN の学習を参照。
コンディショニング
拡散トランスフォーマーではタイムステップをコンディショニングする。キャプションをコンディショニングする場合もあるが、拡散トランスフォーマーではキャプションはノイズ画像と結合して入力されることが多い。
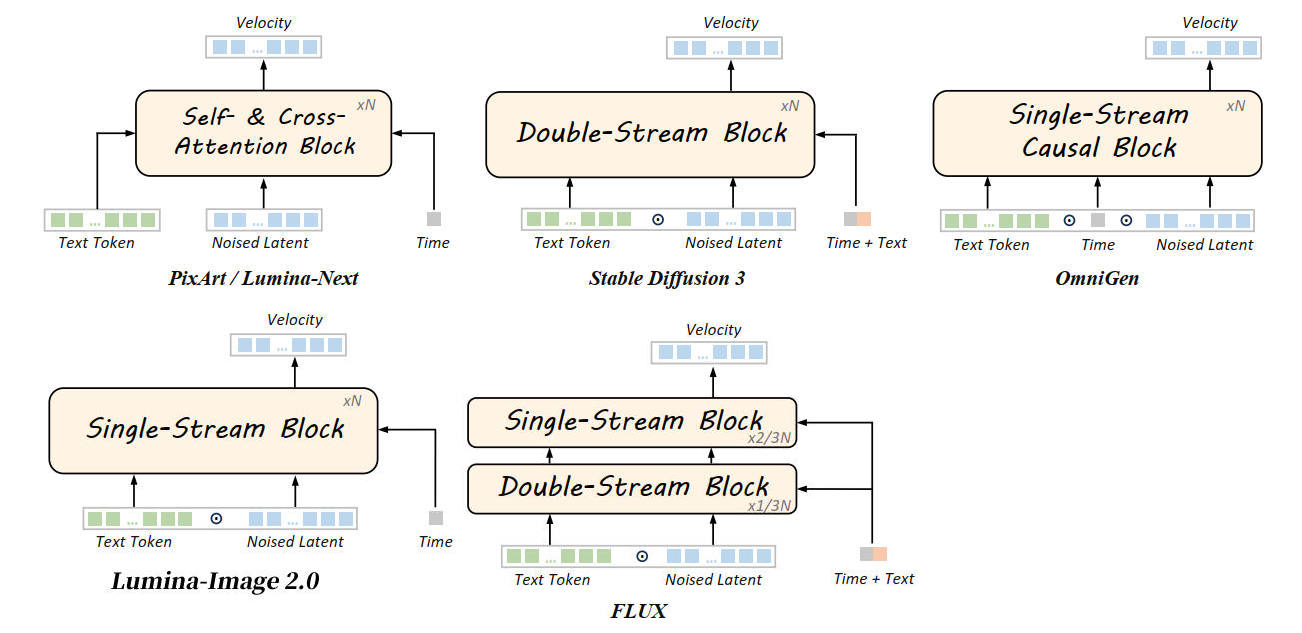
出典:Qi Qin et al. Lumina-Image 2.0: A Unified and Efficient Image Generative Framework. Figure 3.
https://arxiv.org/abs/2503.21758
図の位置の改変は筆者
タイムステップは AdaLN でコンディショニングする。
キャプションはクロスアテンション(SD3, PixArt-α, Hunyuan-DiT, SANA, FLUX, HiDream-I1)かセルフアテンション(OmniGen, FLUX, Lumina-Image 2.0, DiT-Air, Qwen-Image)で取り込む。
DiT-Air: Revisiting the Efficiency of Diffusion Model Architecture Design in Text to Image Generation によると、クロスアテンションよりノイズ画像と結合してセルフアテンションでキャプションを取り込む方が、パラメータ効率が良い。
結合
モデルの隠れ層の次元が dmodel で、テキストエンコーダーの出力 T が [nt, dt] で、潜在空間の画像の次元 IMG が [ni, di] とする。
これらを結合するには Linear などで、T と IMG の隠れ層の次元を dmodel に変換する必要がある。
t_hidden = self.fc_t(T) # [n_t, d_t] -> [n_t, d_model]
img_hidden = self.fc_img(IMG) # [n_i, d_i] -> [n_i, d_model]
input = torch.cat([img_hidden, t_hidden], dim=0) # 実際はバッチサイズがあるので dim=1 になる
print(input.shape) # [n_t + n_i, d_model]
# 分離
img = [:n_i, :] # [n_i, d_model]
t = [n_i:, :] # [n_t, d_model]
Mod
\[x_{out} = x_{in} \odot (1 + \gamma) + \beta\]AdaLN
Layer Nomalization のガンマとベータは学習可能なパラメータだ。AdaLN はこれを線形変換などを使用して動的に変更するもの。つまり
c = タイムステップなど γ = Linear(c) β = Linear(c)\[ \displaylines{ \mathrm{LN}(x) = \gamma \odot \dfrac{x - \mu}{\sigma} + \beta \\ {\mathrm{Layer Normalization} の数式} } \]\[ \displaylines{ \mathrm{AdaLN}(x, c) = \gamma (c) \odot \dfrac{x - \mu}{\sigma} + \beta (c) \\ {\mathrm{AdaLN} の数式。c \;はプロンプトやタイムステップ等} } \]
AdaLN のサンプルコード
import torch
import torch.nn as nn
class AdaLN(nn.Module):
def __init__(self, embed_dim, style_dim):
super().__init__()
self.norm = nn.RMSNorm(embed_dim)
self.proj = nn.Linear(style_dim, 2 * embed_dim) # Scale and Shift
def forward(self, x, style):
scale, shift = self.proj(style).chunk(2, dim=-1)
scale = scale.unsqueeze(1)
shift = shift.unsqueeze(1)
return self.norm(x) * (1 + scale) + shift
ブロック図での表記法
- Scale & Shift:Scale & Shift とだけ書かれていても、AdaLN の場合がある
- LayerNorm の後に Scale, Shift
- LayerNorm の後に Mod
Unveiling the Secret of AdaLN-Zero in Diffusion Transformer
ゼロではなくガウス分布を利用した初期化をする adaLN-Gaussian を提唱している。
位置埋め込み
画像生成 AI の位置埋め込みには2種類ある。セルフアテンションで使われる RoPE と画像のタイムステップ埋め込みとだ。
可変解像度に対応するには位置埋め込みに加え、畳み込みか Attention かを使う必要がある。
ViT の RoPE については Rotary Position Embedding for Vision Transformer が詳しい。
タイムステップ埋め込み(Sinusoidal Encoding)
ノイズ画像や教師画像にタイムステップの埋め込みをすることが多い。スカラーのタイムステップを Sinusoidal Encoding で隠れ層の次元へ拡張し、シーケンス長の個数だけ複製して潜在ノイズと可算する。
Timestep を Sinusoidal Encoding するコード
import torch
import math
def get_timestep_embedding(
timesteps: torch.Tensor,
embedding_dim: int,
flip_sin_to_cos: bool = False,
downscale_freq_shift: float = 1,
scale: float = 1,
max_period: int = 10000,
) -> torch.Tensor:
"""
This matches the implementation in Denoising Diffusion Probabilistic Models: Create sinusoidal timestep embeddings.
Args:
timesteps (torch.Tensor): a 1-D Tensor of N indices, one per batch element
embedding_dim (int): the dimension of the output
flip_sin_to_cos (bool): Whether the embedding order should be `cos, sin` (if True) or `sin, cos` (if False)
downscale_freq_shift (float): Controls the delta between frequencies between dimensions
scale (float): Scaling factor applied to the embeddings
max_period (int): Controls the maximum frequency of the embeddings
"""
assert len(timesteps.shape) == 1, "Timesteps should be a 1d-array"
half_dim = embedding_dim // 2
exponent = -math.log(max_period) * torch.arange(
start=0, end=half_dim, dtype=torch.float32, device=timesteps.device
)
exponent = exponent / (half_dim - downscale_freq_shift)
emb = torch.exp(exponent)
emb = timesteps[:, None].float() * emb[None, :]
# scale embeddings
emb = scale * emb
# concat sine and cosine embeddings
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=-1)
# flip sine and cosine embeddings
if flip_sin_to_cos:
emb = torch.cat([emb[:, half_dim:], emb[:, :half_dim]], dim=-1)
# zero pad
if embedding_dim % 2 == 1:
emb = torch.nn.functional.pad(emb, (0, 1, 0, 0))
return emb
RoPE の前に APE と RPB の復習
Absolute Positional Embedding
入力サイズが固定の時に使える。APE を sinusoidal にするか学習可能なパラメータにするかすることで性能が上がる。
$\mathbf{x}_0 \in \mathbb{R}^{N \times d}, \mathrm{E}_{\mathrm{APE}} \in \mathbb{R}^{N\times d}$ とすると APE は以下の式になる:
\[ \mathbf{x}_0^\prime = \mathbf{x}_0 + \mathrm{E}_{\mathrm{APE}} \]sinusoidal
1次元のシーケンス長 N を $\sqrt{N} \times \sqrt{N}$ のグリッド $(p_x, p_y)$ として解釈し、4t の周期でループする。やっていることは $p_x, p_y$ にそれぞれ sinusoidal encoding を適用しているだけだ。
位置 $\mathbf{p}_n = (p_n^x, p_n^y)$ を $\mathrm{E}_{\mathrm{APE}}(\mathbf{p}_n) \in \mathbb{R}^d$ と表記すると t の位置 の sinusoidal 埋め込み $\mathrm{E}_{\mathrm{APE}}(\mathbf{p}_n, t)$ は:
\[ \large{ \begin{split} \mathrm{E}(\mathbf{p}_n, &4t) &= \mathrm{sin}(p_n^x/10^{4t/\lfloor \frac{d}{4} \rfloor})\\ \mathrm{E}(\mathbf{p}_n, &4t+1) &= \mathrm{cos}(p_n^x/10^{4t/\lfloor \frac{d}{4} \rfloor})\\ \mathrm{E}(\mathbf{p}_n, &4t+2) &= \mathrm{sin}(p_n^y/10^{4t/\lfloor \frac{d}{4} \rfloor})\\ \mathrm{E}(\mathbf{p}_n, &4t+3) &=\mathrm{cos}(p_n^y/10^{4t/\lfloor \frac{d}{4} \rfloor})\\ \end{split} } \]実装例
import torch
import math
def get_2d_sinusoidal_ape(h, w, d, device="cpu"):
# h, w: グリッドの高さと幅 (h * w = N), d: 埋め込み次元
assert d % 4 == 0, "Dimension d must be divisible by 4"
# meshgrid を使ってグリッド上の x 座標と y 座標を生成
grid_y, grid_x = torch.meshgrid(torch.arange(h), torch.arange(w), indexing="ij")
grid_x = grid_x.reshape(-1, 1) # p_n^x (N, 1)
grid_y = grid_y.reshape(-1, 1) # p_n^y (N, 1)
# 10^(4t / (d/4)) の計算。実質 base = 10000 (10^4)
t = torch.arange(0, d // 4, device=device).float()
inv_freq = 1.0 / (10 ** (4 * t / (d // 4)))
# 各成分の計算
pe = torch.zeros(h * w, d, device=device)
pe[:, 0::4] = torch.sin(grid_x * inv_freq) # 4t
pe[:, 1::4] = torch.cos(grid_x * inv_freq) # 4t+1
pe[:, 2::4] = torch.sin(grid_y * inv_freq) # 4t+2
pe[:, 3::4] = torch.cos(grid_y * inv_freq) # 4t+3
return pe
# 使用例 (例: 14x14のパッチグリッド、次元512)
h, w, d = 14, 14, 512
x = torch.randn(1, h * w, d) # (Batch, N, d)
pe = get_2d_sinusoidal_ape(h, w, d, x.device)
x_prime = x + peRelative Position Bias(RPB)
それぞれの絶対位置に学習可能なパラメータをもつ APE と違い、RPB は相対位置に対して学習可能なパラメータを持つ。つまり RPB テーブル T を、取り得る相対位置すべてに対し学習可能なパラメータ、として定義する:
\[ T = \{ T_{\tilde{p}^x \tilde{p}^y} \in \mathbb{R} \; | \; \tilde{p}^x \in \{ -W, ..., 0, ..., W \}, \tilde{p}^y \in \{ -H, ..., 0, ..., H \} \} \]RPB の適用
QK と softmax とを適用したアテンション行列 $\mathbf{A} \in \mathbb{R}^{N\times N}$ は qk ヘッドを $\mathbf{q}, \mathbf{k} \in \mathbb{R}^{N\times d_{head}}$ とすると:
\[ \mathbf{A} = \mathrm{SoftMax}(\mathbf{qk}^T / \sqrt{d_{head}}) \]RPB テーブルの次元は $T \in \mathbb{R}^{(2W+1)\;\times \;(2H+1)}$。アテンション行列の次元 $\mathrm{E}_{\mathrm{RPB}} \in \mathbb{R}^{N\times N}$ に合わせるために以下の計算を行う:
\[ \Large{ \mathrm{E}^{\mathrm{RPB}}_{nm} = T_{ \tilde{p}^x_{nm} \tilde{p}^y_{nm} } = T_{(p^x_n - p^x_m)(p^y_n - p^y_m)} } \]実装時には W, H のバイアスを加えて [0, W or H] の範囲に変換する。実際の実装では、毎回座標変換の計算をするのは非効率なため、あらかじめ相対座標に対応する「インデックス行列(定数)」を作っておき、それを使ってテーブル $T$ から一気に値を gather する手法が一般的。
最終的にアテンション行列と可算する:
\[ \begin{split} \mathbf{A} &= \mathrm{SoftMax}(\mathbf{qk}^T / \sqrt{d_{head}}) + \mathrm{E}_{\mathrm{RPB}} \; \textrm{もしくは} \\ \mathbf{A} &= \mathrm{SoftMax}(\mathbf{qk}^T / \sqrt{d_{head}} + \mathrm{E}_{\mathrm{RPB}}) \end{split} \]RPB テーブルを SoftMax の中にいれると、相対的に近いパッチ同士のスコアを(学習によって)強調したり弱めたりする効果が、確率分布に直接反映されるようになる。
マルチヘッドの数だけ RPB テーブルが必要になる。
RoPE
1D RoPE
1D RoPE は LLM で使われる。
RPB は qk 行列の乗算後の行列に可算していたので、query-key 類似度に影響を与えることができなかった。RoPE ではオイラーの法則 $(e^{i\theta})$ の乗算を利用することで、qk 行列に直接影響を与える。
n, m 番目の qk ベクトルを $\mathbf{q}_n, \mathbf{k}_m \in \mathbb{R}^{1 \times d_{\mathrm{head}}}$ とすると、RoPE は以下のように適用する:
\[ \begin{split} \mathbf{q}^\prime_n &= \mathbf{q}_n e^{in\theta} \\ \mathbf{k}^\prime_m &= \mathbf{k}_m e^{im\theta} \end{split} \]k に共役を適用すると、アテンション行列の (n, m) は以下のように計算できる:
\[ \begin{split} \mathbf{q}_ne^{in\theta} \cdot (\mathbf{k}_me^{im\theta})^* &= \mathbf{q}_ne^{in\theta} \cdot \mathbf{k}_m^* e^{-im\theta} = (\mathbf{q}_n \mathbf{k}_m^*)e^{i(n-m)\theta}\\ \mathbf{A}^\prime_{(n,m)} &= \mathrm{Re} \left[ \mathbf{q}^\prime_n \mathbf{k}^{\prime *}_m \right] = \mathrm{Re} \left[ \mathbf{q}_n \mathbf{k}^{*}_m e^{i(n-m)\theta} \right] \end{split} \]$\mathrm{Re}[\cdot ]$ は複素数の実部で、* は複素共役。トークン位置(n, m)に依存する複素回転 $e^{i\theta n}, e^{i\theta m}$ を掛けることで、相対位置(n - m)を回転形式でアテンション行列に注入できる。
実装する場合は、RoPE は $\mathbf{q}_n, \mathbf{k}_m \in \mathbb{R}^{1 \times d_{\mathrm{head}}}$ を複素ベクトル $\bar{\mathbf{q}}_n, \bar{\mathbf{k}}_m \in \mathbb{C}^{1 \times (d_{\mathrm{head}}/2)}$ に変換し、(2t) 番目の次元を実部、(2t+1) 番目の次元を虚部として扱う。$\mathbf{q}_n\mathbf{k}_m^T = \mathrm{Re}[\bar{\mathbf{q}}_n \bar{\mathbf{k}}_m^*]$ と同じアテンションの値を生成するが計算の無駄を減らせる。
kq の隠れ層の次元は RoPE の周波数に影響を与える:
\[ \theta_t = 10000^{-t(d_{\mathrm{head}/2})}, \mathrm{where} \; t \in \{ 0, 1, ..., d_{\mathrm{head}}/2 \} \]まとめると、回転行列 $\mathbf{R} \in \mathbb{C}^{N \times (d_{\mathrm{head}}/2)}$ は以下のように定義される:
\[ \mathbf{R}(n, t) = e^{i\theta_t n} \]アダマール積 $\circ$ を使用して、クエリベクトルとキーベクトルとに適用する:
\[ \begin{split} \bar{\mathbf{q}}^\prime &= \bar{\mathbf{q}} \circ \mathbf{R} \\ \bar{\mathbf{k}}^\prime &= \bar{\mathbf{k}} \circ \mathbf{R} \\ \mathbf{A}^\prime &= \mathrm{Re} \left[ \bar{\mathbf{q}}^\prime \bar{\mathbf{k}}^{\prime *} \right] \end{split} \]コード例
import torch
import math
# 毎回作成するのではなく、一度作成してキャッシュする
def build_rope_cache(
seq_len: int,
head_dim: int,
base: float = 10000.0,
device=None,
dtype=None,
):
"""
sin, cos cache を生成する
Returns:
cos, sin: [seq_len, head_dim // 2]
"""
assert head_dim % 2 == 0
half_dim = head_dim // 2
inv_freq = 1.0 / (base ** (torch.arange(0, half_dim, device=device, dtype=dtype) / half_dim)) # θ_t の計算
positions = torch.arange(seq_len, device=device, dtype=dtype)
freqs = torch.einsum("i,j->ij", positions, inv_freq) # 外積を利用して、nθ, mθ の計算
cos = torch.cos(freqs)
sin = torch.sin(freqs)
return cos, sin
def apply_rope(q: torch.Tensor, k: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor):
"""
RoPE を q, k に適用する
B: batch size
H: head
S: sequence length
D: dimension
Args:
q, k : [B, H, S, D]
cos, sin : [S, D//2]
Returns:
q_rot, k_rot : [B, H, S, D]
"""
B, H, S, D = q.shape
assert D % 2 == 0
# [B, H, S, D//2, 2]
q = q.view(B, H, S, D // 2, 2) # q.shape = [B, H, S, D//2, 2]。dimension 次元を2分割
k = k.view(B, H, S, D // 2, 2)
cos = cos[None, None, :, :, None] # [1,1,S,D//2,1]
sin = sin[None, None, :, :, None]
# 回転
q_rot = torch.stack(
[
q[..., 0] * cos - q[..., 1] * sin,
q[..., 0] * sin + q[..., 1] * cos,
],
dim=-1,
)
k_rot = torch.stack(
[
k[..., 0] * cos - k[..., 1] * sin,
k[..., 0] * sin + k[..., 1] * cos,
],
dim=-1,
)
# 次元を元に戻して返す
return (
q_rot.view(B, H, S, D),
k_rot.view(B, H, S, D),
)
実際の運用
sin/cos のキャッシュ
最大長で 1 回作って slice するのが一般的。
cos = cos[:current_seq_len]
sin = sin[:current_seq_len]
sin/cos を static buffer として register_buffer 化。
2D RoPE
軸の周波数
1D トークン位置 $n$ を 2D のトークン位置 $\mathbf{p}_n = (p_n^x, p_n^y) \; \mathrm{where}\; p_n^x \in \{ 0, 1, ..., W \}, p_n^x \in \{ 0, 1, ..., H \}$ に変換する:
\[ \large{ \begin{split} &\mathbf{R}(n, 2t) &= e^{i\theta_t p_n^x}\\ &\mathbf{R}(n, 2t+1) &= e^{i\theta_t p_n^y} \end{split} } \]なお $(p_n^x, p_n^y)$ の位置インデックスの範囲は平方根で削減される。周波数 $\theta_t$ も同様に:
\[ \large{ \theta_t = 100^{-t/(d_{\mathrm{head}}/4)}, \; \mathrm{where} \; t \in \{ 0, 1, ..., d_{\mathrm{head}}/4 \} } \]学習可能な周波数のミックス
軸で RoPE を拡張するのは単純で効率的だが、対角方向の成分を処理できない。これは画像処理モデルの性能を低下させる可能性がある。
対角成分も処理できるようにするには、回転行列を以下のように定義する:
\[ \large{ \mathbf{R}(n, t) = e^{i(\theta_t^x p_n^x + \theta_t^y p_n^y)} } \]RoPE アテンション行列は以下のようになる:
\[ \large{ \mathrm{A}^\prime_{(n,m)} = \mathrm{Re}\left[ \mathbf{q}_n \mathbf{k}_m^* e^{i(\theta_t^x (p_n^x - p_m^x) + \theta_t^y (p_n^y - p_m^y))} \right] } \]LLM では RoPE と軸の周波数は固定値だったが、画像処理モデルでは $(\theta_t^x, \theta_t^y)$ を学習可能にする。
最小構成の 2D RoPE の実装
import torch
def apply_2d_rope(q, k, base=10000.0):
# q, k: [B, H, W, D]
B, H, W, D = q.shape
assert D % 4 == 0
Dh = D // 2
P = Dh // 2 # number of rotary pairs per axis
device, dtype = q.device, q.dtype
inv_freq = 1.0 / (base ** (torch.arange(P, device=device, dtype=dtype) / P))
y = torch.arange(H, device=device, dtype=dtype)[:, None] # y.shape = [H, 1]
x = torch.arange(W, device=device, dtype=dtype)[:, None]
cos_y, sin_y = torch.cos(y * inv_freq), torch.sin(y * inv_freq)
cos_x, sin_x = torch.cos(x * inv_freq), torch.sin(x * inv_freq)
def rotate(t, cos, sin):
t = t.view(B, H, W, P, 2)
t0, t1 = t[..., 0], t[..., 1]
return torch.stack([t0 * cos - t1 * sin,
t0 * sin + t1 * cos], dim=-1).view(B, H, W, -1)
qy, qx = q.split(Dh, dim=-1)
ky, kx = k.split(Dh, dim=-1)
q = torch.cat([rotate(qy, cos_y[:, None], sin_y[:, None]),
rotate(qx, cos_x[None, :], sin_x[None, :])], dim=-1)
k = torch.cat([rotate(ky, cos_y[:, None], sin_y[:, None]),
rotate(kx, cos_x[None, :], sin_x[None, :])], dim=-1)
return q, k
mRoPE・3D Unified RoPE(Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution)
Lumina-Image 2.0 や Z Image Turbo で使われている。
Z Image Edit では入力画像と潜在ノイズとの RoPE の x と y とを一致させ、時間次元だけ変更している。
\[ \large{ \begin{split} \mathbf{R}(n, t) &= e^{i(\theta_t^x p_n^x + \theta_t^y p_n^y + \theta_t^{\mathrm{time}} \mathrm{time}_n)} \\ \mathrm{A}^\prime_{(n,m)} &= \mathrm{Re}\left[ \mathbf{q}_n \mathbf{k}_m^* e^{i(\theta_t^x (p_n^x - p_m^x) + \theta_t^y (p_n^y - p_m^y) + \theta_t^{\mathrm{time}} (\mathrm{time}_n - \mathrm{time}_m))} \right] \end{split} } \]MSRoPE
Column-wise Position Encoding は画像と結合されたプロンプトの座標の x 座標のみを増加させていた。しかし、これは画像が横に続いているのかプロンプトなのかが判別できない。そこで MSRoPE ではプロンプト座標の x, y 両方の座標を増加させ、画像とプロンプトの区別をしやすくした。
Mix-FFN
3x3 の畳み込みによって RoPE なしでも相対位置情報を取得できる。SegFormer の Mix-FFN は以下のようになる。
\[ x_{out} = \mathrm{MLP}(\mathrm{GELU}(\mathrm{Conv}_{3\times 3}(\mathrm{MLP}(x_{in})))) + x_{in} \]SANA の Mix-FFN は GELU ではなく SiLU を使っている。SiLU(Swish) は ReLU に形が似ていて、(0, 0) を通る。0を境界に導関数が急に変化する ReLU と違い、SiLU は導関数が滑らかに変化する。
GELU も SiLU も ReLU のような形で導関数が滑らかに変化するように設計されたもの。GELU の方が性能が良いが、SiLU の方が計算が速く、どちらも ReLU より性能が良い。
SANA が Mix-FFN を使用しているが、その隠れ層の次元が 5,600 もあり、RoPE を使った方が速い可能性が高い。
外部リンク
SANA は RoPE ではなく Mix-FFN を採用している。
RoFormer: Enhanced Transformer with Rotary Position Embedding
Rotary Position Embedding for Vision Transformer
目的関数
ノイズを予測させる epsilon prediction から、ノイズ差分を予測させる v parameterization へトレンドが移り、2025 年では Rectified Flow や Flow matching を使うのが一般的になっている。
シンプルなまとめとしては Diffusion Meets Flow Matching: Two Sides of the Same Coin が参考になる。
将来有望な技術
- Energy-Based Transformers
- Energy-Based Learning については A Tutorial on Energy-Based Learning. Yann LeCun et al. 2006(pdf)を参照
- Transition Matching
- Pixel Neural Field Diffusion
- Network of Theseus (like the ship)。表現を学習させることでモデルのパーツを入れ替える(CNN -> MLP, Transformer -> RNN/Patch-MLP など)。驚くべきことに教師モデルは未学習でも構造を転移可能
- The Neural Differential Manifold: An Architecture with Explicit Geometric Structure ニューラルネットを微分可能多様体として再構築する。各レイヤーは局所座標系(local coordinate chart)として機能する。ネットワークパラメーターは各点でのリーマン計量テンソルを直接パラメータ化する。この手法は性能が向上するのではなく、ネットワークの解釈可能性を大幅に改善する。
- 誤差逆伝播法を使用しない並列学習
v parameterization と Rectified Flow は何が違うか
記号の定義
- $\mathbf{\epsilon}$ ノイズ
- $\mathbf{x}_0$ 教師画像
- $\alpha_t$ ノイズのウェイト
- $\sigma_t$ 教師画像のウェイト
| v-parameterization | Rectified Flow | |
| 予測対象 | $\mathbf{v}_t = \alpha_t \mathbf{\epsilon} - \sigma_t \mathbf{x}_0$ | $\mathbf{v}_t = \mathbf{\epsilon} - \mathbf{x}_0$ |
| 損失関数 | $\mathcal{L} = ||\hat{\mathbf{v}} (\mathbf{x}_t, t) - \mathbf{v}_t||^2$ | $\mathcal{L}_{RF} = ||\hat{\mathbf{v}} (\mathbf{x}_t, t) - \mathbf{v}_t||^2$ |
| 設計目的 | ノイズとデータ両方を学習する | サンプリング経路を直線化し 学習と推論を簡素化する |
$\mathbf{v}_t = \mathbf{\epsilon} - \mathbf{x}_0$ より、Rectified Flow は $\mathbf{v}_t$ の速度が時刻 t に依存せずに一定である、というところが v-parameterization と違う。
v-parameterization は従来の拡散モデルの枠組みの中での損失関数の工夫。Rectified Flow は forward/backward プロセス自体を変更し、それに伴って損失関数も簡素化された。
$\alpha_t = \sigma_t$ ならば v-parameterization と Rectified Flow は同じものになるが、通常は $\alpha_t \ne \sigma_t$。
フローベースモデルの変遷
DDPM / Score-based model
拡散モデルは以下のような確率フロー(SDE)に基づく生成モデル:
\[ d\mathbf{x}_t = f(\mathbf{x}_t, t)dt + g(t) d\mathbf{w}_t \]その生成過程は Probability Flow ODE によって以下のような決定論的フローへ落とし込める:
\[ \dfrac{d\mathbf{x}_t}{dt} = f(\mathbf{x}_t, t) + \dfrac{1}{2}g(t)^2 \nabla_x \mathrm{log}\; p_t(\mathbf{x}) \]この事実が、「そもそも 密度の時間発展を直接 ODE で学習できるのでは?」という流れを生み、フローベース生成モデルの再興につながる。
Continuous Normalizing Flow(CNF)
CNF は連続時間 ODE による可逆変換で分布を輸送するモデル。
\[ \dfrac{d\mathbf{x}_t}{dt} = \mathbf{v}_\theta (\mathbf{x}_t, t), t \in [0, 1] \]初期分布 $p_0(\mathbf{x})$ (たとえば標準正規分布)からデータ分布 $p_1(\mathbf{x})$ へ写像する。
対数尤度をとると:
\[ \begin{split} \dfrac{d}{dt}\mathrm{log}\; p_t(\mathbf{x}_t) &= -\mathrm{div}_{\mathbf{x}} \mathbf{v}_\theta (\mathbf{x}_t, t) \\ \mathrm{log} \; p_1(\mathbf{x}_1) &= \mathrm{log}\; p_0(\mathbf{x}_0) - \int_0^1 \mathrm{div} \mathbf{v}_\theta(\mathbf{x}_t, t) dt \end{split} \]しかし CNF は以下の問題がある:
- divergence 計算が高コスト(画像では致命的)
- MLE 学習が不安定
- 拡散モデルのようなロバスト性がない
なので密度を使わず、流れそのものを直接学習するようになった。
Flow Matching
CNF は密度 $p_t$ を直接扱うため計算が現実的ではなかった。Flow Matching は「中間分布を定義し、そこに対応する真の速度場を教師として回帰する」という発想でこれを回避する。
- $\mathbf{x}_0 \sim p_0$:ノイズ分布
- $\mathbf{x}_1 \sim p_1$:データ分布
に対し、補間分布 $p_t$ を以下のように定義する:
\[ \mathbf{x}_t = (1-t)\mathbf{x}_0 + t\mathbf{x}_1 = \sigma (t)\epsilon \]このときの真の条件付き速度場は:
\[ \mathbf{v}^*(\mathbf{x}_t, t) = \mathbb{E}\left [ \dfrac{d\mathbf{x}_t}{dt} \middle | \mathbf{x}_t\right ] \]Flow Matching 損失は:
\[ \mathcal{L}_{\mathrm{FM}} = \mathbb{E}_{t,\mathbf{x}_t} \left [ || \mathbf{v}_\theta (\mathbf{x}_t,t) - \mathbf{v}^*(\mathbf{x}_t, t) ||^2 \right ] \]Flow Matching は以下の特徴がある。
- スコア $\nabla \mathrm{log} \; p_t$ 不要
- divergence の計算が不要
- ODE サンプリング可能
- ガウシアン補間を使うと Probability Flow ODE と一致し、『Flow Matching は「拡散モデルを密度なしで再定式化したもの」』と解釈可能
Rectified Flow
Flow Matching は速度場が曲がりやすく以下の問題がある。
- ODE 積分誤差が大きい
- ステップ数削減に限界がある
Rectified Flow は「最短経路(直線)に近い流れを学習させる」ことを目的とする。
定義:
\[ \mathbf{x}_t = (1-t)\mathbf{x}_0 + t\mathbf{x}_1 \]このときの真の速度は以下の定数になる:
\[ \dfrac{d\mathbf{x}_t}{dt} = \mathbf{x}_1 - \mathbf{x}_0 \]損失は:
\[ \mathcal{L}_{\mathrm{RF}} = \mathbb{E} \left [ || \mathbf{v}_\theta (\mathbf{x}_t,t) - \mathbf{x}_1 - \mathbf{x}_0 ||^2 \right ] \]Towards Hierarchical Rectified Flow
Rectified Flow はモデルに平均速度を予測させるが、Hierarchical Rectified Flow は加速度を予測させる。CIFAR-10 と ImageNet-32 のデータセットを使った検証では Rectified Flow より収束が速い。
Hierarchical Rectified Flow Matching with Mini-Batch Couplings では Data & Velocity Coupling で1ステップでもそこそこの品質の画像を生成している。
x pred の方が高性能かもしれない
Tianhong Li と Kaiming He は Back to Basics: Let Denoising Generative Models Denoise でノイズを予測する ε pred や「画像 - ノイズ」を予測する v parameterization より画像を直接予測する x pred が性能がよい可能性を指摘した。
多様体仮説*1によれば、画像は高次元のピクセル空間内の低次元の多様体内に存在している。ノイズのない画像は多様体としてモデリング可能だが、ノイズや速度は多様体外にある。なので、ノイズのない画像を直接予測するモデルとノイズや速度を予測するモデルとは根本的に異なる。
論文ではトークナイザ(VAE)なし、事前学習なし、追加損失(LPIPS や GAN)なしで、巨大パッチサイズ(16 と 32。通常は 2)で拡散トランスフォーマーを x pred で学習させている。
ネットワークは画像を直接予測させるが、損失は速度を使うと性能が上がる。
解像度に合わせてパッチサイズを増やすことで、演算負荷をそれほど増やさずに性能をスケールさせられることを実証している。
ネットワークの最初の線形パッチブロックの次元を削減すると性能が上がると報告している。
*1: livier Chapelle, Bernhard Sch¨olkopf, and Alexander Zien, editors. Semi-Supervised Learning. MIT Press, Cambridge, MA, USA, 2006.
数式
ノイズを $\epsilon \sim \mathcal{N}(0, \mathbf{I})$、ノイズの乗ったサンプル $z_t = a_t x + b_t \epsilon, \mathrm{where} \;a_t, b_t \in [0, 1]$ とすると:
\[ z_t = t x_\theta + (1-t)\epsilon_\theta \]$\epsilon_\theta$ は $\epsilon$ pred を考えるときに必要になるが、x pred や v pred の場合は $\epsilon$ とする。
$z_t$ を t で微分すると以下の速度が得られる:
\[ v_\theta = x_\theta - \epsilon_\theta \]上記の3つの式をまとめると:
\[ \large{ \begin{split} x_\theta &= \mathrm{net}_\theta (z_t, t)\\ z_t &= t x_\theta + (1-t)\epsilon_\theta \\ v_\theta &= x_\theta - \epsilon_\theta \end{split} } \]モデルが x pred $\mathbf{x}_\theta := \mathrm{net}_\theta (z_t,t)$ とすると、その v-loss は:
\[ \large{ \begin{split} \mathcal{L}_{v}&= \mathbb{E}||v_\theta - v||^2\\ v_\theta &= (x_\theta - z_t)/(1-t) \end{split} } \]# net(z, t): JiT network
# x: training batch
import torch
import torch.nn as nn
t = sample_t()
e = randn_like(x)
z = t * x + (1 - t) * e
v = (x - z) / (1 - t)
x_pred = net(z, t)
v_pred = (x_pred - z) / (1 - t)
loss = nn.MSELoss(v - v_pred) # L2 loss
パッチ
論文では固定解像度なので Linear でパッチ化しているが、可変解像度の場合は畳み込みを使う。
単段 CNN の実装。表現能力を Transformer に丸投げする設計で、Transformer が余計な表現も学習する必要がある(解像度が変わると トークン統計が大きく変動)ので、性能が低下する。
class PatchEmbed(nn.Module):
def __init__(self, patch=16, dim=768):
super().__init__()
self.proj = nn.Conv2d(3, dim, patch, stride=patch)
def forward(self, x):
# x.shape = [B, 3, H, W]
x = self.proj(x) # [B, dim, H/patch, W/patch]
# 位置埋め込みをする場合はここで行う
x = x.flatten(2).transpose(1, 2)
return x # [B, (H/patch)*(W/patch), dim]
多段 CNN の実装。事実上のデファクト。視覚表現を構造的に整形してから Transformer に渡す設計。
class PatchEmbed(nn.Module):
def __init__(self, patch=4, dim=768):
super().__init__()
self.cnn1 = nn.Conv2d(3, 3, patch, stride=patch)
self.cnn2 = nn.Conv2d(3, 3, patch, stride=patch)
self.cnn3 = nn.Conv2d(3, dim, 1, 1)
def forward(self, x):
# x.shape = [B, 3, H, W]
x = self.cnn1(x) # [B, 3, H/patch, W/patch]
x = self.cnn2(x) # [B, 3, H/(patch^2), W/(patch^2)]
x = self.cnn3(x) # [B, dim, H/(patch^2), W/(patch^2)]
x = x.flatten(2).transpose(1, 2) # [B, (H/patch)*(W/patch), dim]
return x
参考文献
Improving and generalizing flow-based generative models with minibatch optimal transport
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
SiT: Exploring Flow and Diffusion-based Generative Models with Scalable Interpolant Transformers
Transition Matching: Scalable and Flexible Generative Modeling
Transformer アーキテクチャ
U-Net より Transformer が選択されるのは、モデルサイズを大きくしたときの性能のスケール率が大きいため(Transformer の方が巨大モデルのパラメータ効率がよい)。
Transformer のトレンドは以下のように変化した
- sinusoidal positional embedding -> RoPE
- Multi-Head Attention
- GELU -> SwiGLU
- LayerNorm -> RMSNorm
- QK-Norm
- Mixture-of-Experts
- Mixture-of-Recursions
Grouped-Query Attention
Grouped-Query Attention は Multi-Head Attention の K, V を複数のクエリで共有する。 GQA-4 のケースでは、K と V との数が 1/4 になり、推論速度が 1.3 倍高速になり、メモリ使用量 50% 減少、性能の低下は1~3%。
Dit-Air ではヘッドだけではなく、QKVO をすべてのトランスフォーマーブロックで共有している。
スパースアテンション
スパースアテンションの比較は The Sparse Frontier: Sparse Attention Trade-offs in Transformer LLMs を参照。
スパースアテンションはトークン数が少ない場合は効果が薄い。さらに「汎用スパース化」は存在せず、タスク・モデル・長さの組み合わせごとのスパース化手法の詳細評価が必須。
QK 行列を LoRA 化して計算を近似する Low-Rank Approximation for Sparse Attention in Multi-Modal LLMs がある。
Deepseek Sparse Attention はアテンションに MoE のような構造を導入しアテンションのコストを削減した。
Trainable Log-linear Sparse Attention for Efficient Diffusion Transformers ではスパースアテンションを階層化してさらにコスト削減。
Gated Attention
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free は SDPA の後にシグモイドを入れるだけで性能を向上させた。
Multi-Head Latent Attention
DeepSeek-V2 で採用された、KV キャッシュを圧縮する手法。
QK-Norm
Multi-Head Attention の Q, K の RoPE 適用前に RMSNorm を入れる。
SwiGLU
ゲートの活性化関数に Swish を使ったもの。SwiGLU は入力の二乗や乗算のような多項式近似をエミュレートできるのが強み。LLM では事実上のスタンダードになっている。表現力の向上、収束の高速化(学習の高速化)、大規模モデルでの性能向上が見られることが複数の論文で実証されているが、性能向上の理由は不明。
従来の FFN は2つの重み行列(W1, W2)を持つのに対し、GLU 派生は3つ(W, V, W2)持つ。なので SwiGLU を含む GLU の派生形のパラメータ数は、FFN と比較して、隠れ層の次元が 2/3 に削減される。
SwiGLU は外れ値同士が掛け算されて値が増幅されることがある。Smooth-SwiGLU によってその問題は解決され、LLM では FP8 での学習も可能になっている。
ReLUと比較して、SwiGLUは固有のスパース性がほとんどないため、従来のスパース性を活用する技術の効果が薄い。
DiT においては収束を 21 倍加速させた事例が報告されているが、性能が向上した論文はない。
参考文献
ConvSwiGLU
ConvSwiGLU は推論モデルで性能向上が確認されている。
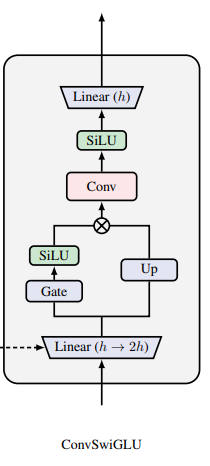
出典:Universal Reasoning Model, Zitian Gao et al. Figure 2
入力シーケンス $X \in \mathbb{R}^{T \times d}$ の潜在次元を拡張したあと、Gate + SiLU と Conv +SiLU を通る:
\[ \large{ \begin{split} [\mathbf{G, U}] &= XW_{\mathrm{up}} \in \mathbb{R}^{T \times 2m}\\ \mathbf{H}_{\mathrm{ffn}} &= \mathrm{SiLU(\mathbf{G}) \odot \mathbf{U}} \\ \mathbf{H}_{\mathrm{conv}} &= \sigma (\mathbf{W}_{\mathrm{dwconv}} * \mathbf{H}_{\mathrm{ffn}})\\ \mathbf{Y}_{\mathrm{ConvSwiGLU}} &= [ \sigma (\mathbf{W}_{\mathrm{dwconv}} * ( \mathrm{SiLU(\mathbf{G}) \odot \mathbf{U}})) ]W_{\mathrm{down}} \end{split} } \]参考文献
The Big LLM Architecture Comparison
シングルストリーム vs デュアルストリーム
デュアルストリームは画像パッチとテキストとで別々の FFN を通過させる。シングルストリームは FFN を分離しない。
デュアルストリームを採用することが多いのは、画像とテキストとのトークン数の違いからくる。例えば、VAE が F8P2 で、画像の解像度が 1024 だとする。すると画像のトークン数は (1024/(8*2))^2 = 4,096 トークン。これにたいしてテキストのトークン数が 1,000 を超えることはまずない。
このような状況なので、シングルストリームでは FFN は、テキストを無視して画像トークンに FFN を最適化するようになる。なのでテキストの追従性を高めるためにデュアルストリームが主流になっている。
Linear Attention
Linear Attention は KV 行列を先に計算することで、トークン数に依存せずに定数時間で計算できるが、性能は低下する。
The Devil in Linear Transformer
- 無限大に発散する勾配:Linear Attention はスケーリングが不要にもかかわらず Attention 行列に過度なスケーリングが入り込み,勾配が発散し収束を阻害する
- 注意の希薄化(Attention Dilution):長い系列に対して Attention weight が一様に分散され、隣接構造への Attention が失われる
FLatten Transformer: Vision Transformer using Focused Linear Attention
Linear Attentionの性能劣化要因として、フォーカス能力の不足・特徴多様性の欠如(ランク制限)を分析し、マッピング関数とランク復元モジュールによって表現力を高める手法を提案。複数のビジョンタスクで一貫して性能向上を確認している。
Breaking the Low-Rank Dilemma of Linear Attention
Linear Attention の出力特徴マップ(KV バッファ)が Softmax Attention に比べて低ランクとなり、表現力を制限する。これらを解消する Rank-Augmented Linear Attention (RALA) を提案し,ImageNet性能でSoftmaxに迫る改善を示している。
Bridging the Divide: Reconsidering Softmax and Linear Attention
理論的観点からLinear Attentionが満たさない2つの性質を指摘している。
- 注入性(Injectivity)の欠如:異なるクエリに同一の Attention weight が割り当てられ、意味的混乱を招く
- 局所モデル化能力の不足:Softmax のように近傍構造を重視できず、視覚タスクでの性能に差が出る
これらを付与すると Linear Attention が Softmax を上回る可能性を示唆している。
DeltaNet Explained
Linear Attention を連想メモリとみなした場合、消去機構がなく既存情報が蓄積し続けるため、長系列で "検索誤差" が蓄積し性能低下を招くと解説。これは固定サイズの状態行列に新しい key–value だけを追加し続ける構造的制約によるもの。
Rectifying Magnitude Neglect in Linear Attention
Softmax Attention ではクエリベクトルの大きさが注意分布に影響を与えるが、Linear Attentionではカーネル変換後の大きさ成分が相殺され、方向情報のみで注意を計算するため適応性を欠く。Magnitude-Aware Linear Attention (MALA) を提案し、大きさ情報を再導入する改善を示している。
Transformer を使わないアーキテクチャ
非 Transformer で Transformer に匹敵する性能を達成できているのは Mamba がある。
Mamba
RNN + CNN でアテンションのような動作をしかつ、シーケンス長に線形な計算負荷を達成している。PLaMo 翻訳や NVIDIA の Nemotron 3 Nano は Mamba を採用している。
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces
- Mamba-2 Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality
Gated MLP
Pay Attention to MLPs では Attention を Gate で置き換えて、Transformerに匹敵する性能を達成できることを示した。
MLP-Mixer
注意機構と畳み込みを完全に排除した純粋なMLPアーキテクチャ。
- Token-mixing MLP:パッチ間の空間的情報を混合
- Channel-mixing MLP:チャンネル次元の特徴を混合
- 線形スケーリング:注意機構のO(N2)から改善
ResMLP
MLP-Mixer 同様、純粋にMLPのみで構成された残差ネットワーク。同等の計算量で MLP-Mixer を上回る。
S2-MLP: Spatial-Shift MLP Architecture for Vision
S2-MLP は空間シフト操作を導入してパッチ間通信を実現する。
- パラメータフリーシフト:隣接パッチへのチャンネルシフトで情報交換
- 局所受容野:隣接パッチのみとの直接的な情報交換
- 計算効率:Token-mixing MLPを完全に排除
S2-MLP は MLP-Mixer より高い精度を達成し、ViT と同等の性能を少ないパラメータで実現した。
ブロック図
トランスフォーマーブロックの内部に以下のパターンが2~3回出現するのが基本。
- AdaLN
- Attention・MLP ・FFN
- Scale
DiT
FFN
Pointwise Feedforward Network と Position-wise Feed-Forward Network とはほぼ同じ意味。バッチ・系列長・埋め込み次元のテンソルにおいて、各位置 i にあるベクトル x_i に対して、まったく同じ重みの MLP を適用する。数式は以下のようになる。
\[\mathrm{FFN}(x) = \mathrm{max}(0, xW_1 + b_1)W_2 + b_2\]Zero-Init. Gate(adaLN-Zero)
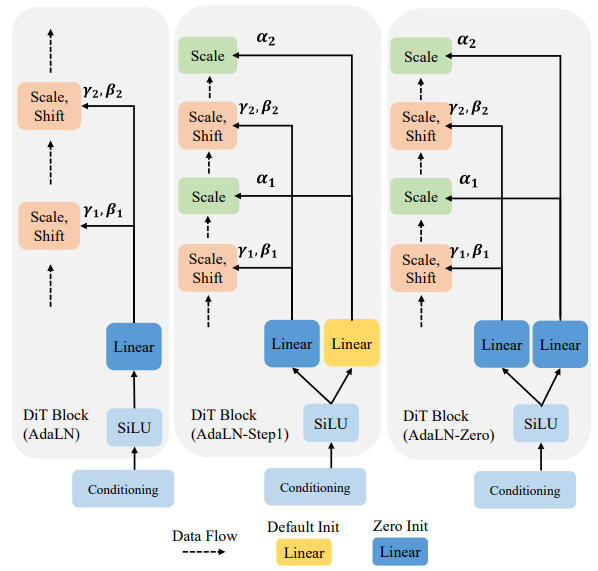
出典:Unveiling the Secret of AdaLN-Zero in Diffusion Transformer Jie Zhu et al. Figure. 2 https://openreview.net/forum?id=E4roJSM9RM
Unveiling the Secret of AdaLN-Zero in Diffusion Transformer はガウス分布で初期化するアイデアに問題があり論文がリジェクトされているが、adaLN-Zero の分析は参考になる。
Patching(Patchify)
Transformer はトークン数の2乗で計算量が増えるので、パッチ化によってトークン数をチャンネル数に変換することで計算負荷を下げられる。dmodel > C * P * P のときにこの戦略は機能する。
VAE の設定が F8C4P2 とする。元の画像が 3 x 1024 x 1024 だとする。その潜在空間表現は 4 x 128 x 128。パッチサイズが2ということは4ピクセル(2 x 2)を一つの埋め込み次元にするので、16 x 64 x 64。16 = チャンネル数 * パッチサイズ^2。幅と高さを1次元化して転置すると、最終的に 4096 x 16 になる。埋め込み次元は 16 になる。
その後で Linear によって任意の埋め込み次元数に拡張する。
from einops import rearrange
# x = [B, C, H, W] -> [B, H*W, C*P*P]
patches = rearrange(x, 'b c (h p) (w p) -> b (h w) (c p p)', p=self.patch_size)
# [B, H*W, C*P*P] -> [B, H*W, D_model]
hidden_states = self.projection(patches)
# [B, H*W, D_model] -> [B, H*W, C*P*P]
patches = self.reverse_proj(hidden_states)
rearrange(patches, 'b (h w) (c f1 f2) -> b c (h f1) (w f2)', f1=P, f2=P, h=int(H/P), w=int(W/P))
# 畳み込みの場合
image_to_patches = nn.Conv2d(input_channel, model_dim, kernel_size=(P, P), stride=P, bias=True)
patches = image_to_patches(x)
tokens = rearrange(patches, 'b c h w -> b (h w) c')
# unpatch
patches_to_image_deconv = nn.ConvTranspose2d(model_dim, input_channel, kernel_size=(P, P), stride=P, bias=True)
patches = rearrange(tokens, 'b (h w) c -> b c h w', h=int(H/P), w=int(W/P))
patches_to_image_deconv(patches)
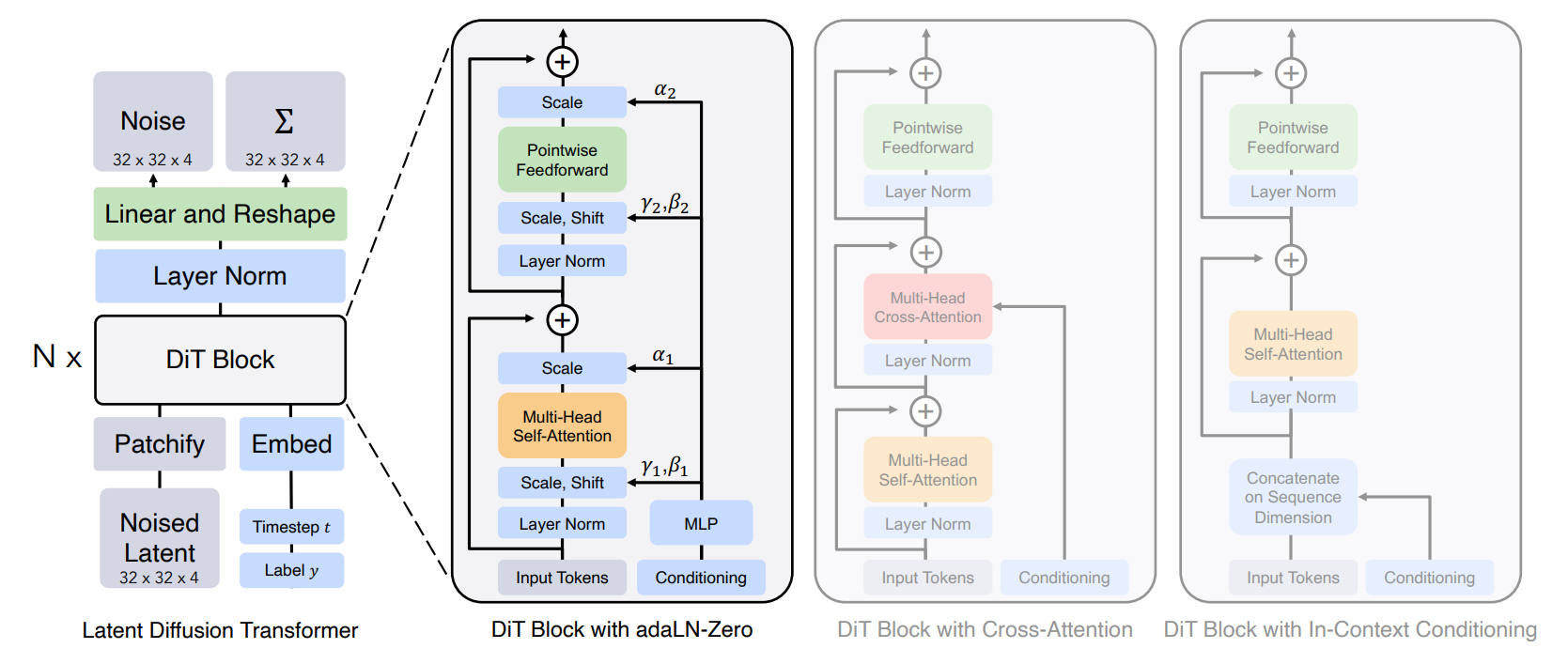
2022年
出典:Scalable Diffusion Models with Transformers. William Peebles et al. Figure 3. https://arxiv.org/abs/2212.09748
PixArt-α
位置エンコーディングには DiffFit: Unlocking Transferability of Large Diffusion Models via Simple Parameter-Efficient Fine-Tuning で使用された、 sinusoidal interpolation を使っている。実装は単純で、DiT の解像度は 256 だが DiffFit は 512 なので、DiT の sinusoidal encoding の (i, j) を (i/2, j/2) にしただけだ。
MLP
トランスフォーマーブロックの隠れ層と同じ次元を持つ、2レイヤーの MLP。活性化関数は SiLU。
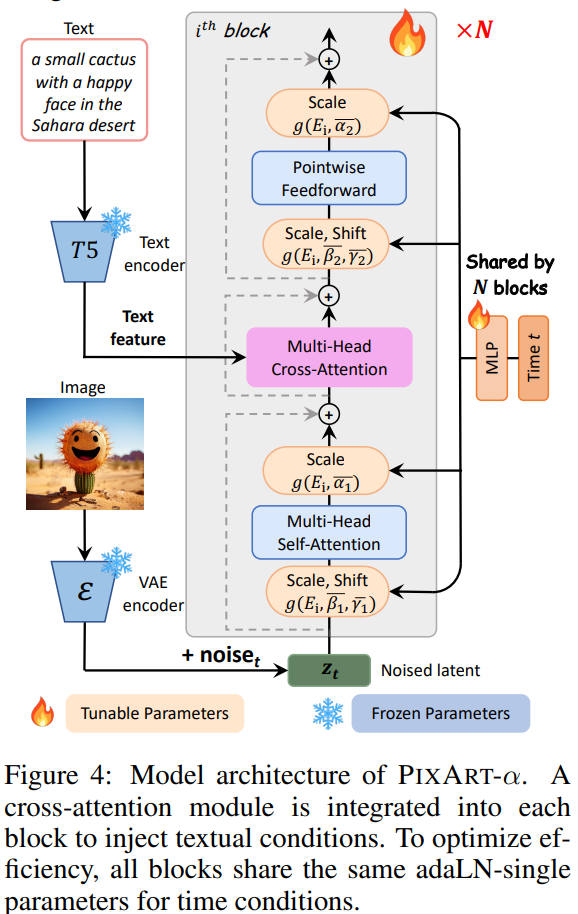
2023年
出典:PixArt-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis. Junsong Chen et al. Figure 4. https://arxiv.org/abs/2310.00426
DiG: Scalable and Efficient Diffusion Models with Gated Linear Attention
2024 年。
Gated Linear Attention を採用し、DiG-S/2 モデルは標準の DiT-S/2 と比較して 2.5 倍高速であり、GPUメモリを75.7%節約できている。さらに FlashAttention-2 を使用した DiT よりも 2,048 解像度で 1.8 倍高速。
Stable Diffusion 3
テキストと画像とを別々に処理するダブルストリーム方式。
SD3 は設計が古いので RoPE を使わず、潜在ノイズをパッチ化した後に、潜在ノイズに位置埋め込みをしている。
Stable Diffusion 3(SD3)の理論やモデル構造について解説
2024年
出典:Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. Patrick Esser et al. Figure 2. https://stability.ai/news/stable-diffusion-3-research-paper
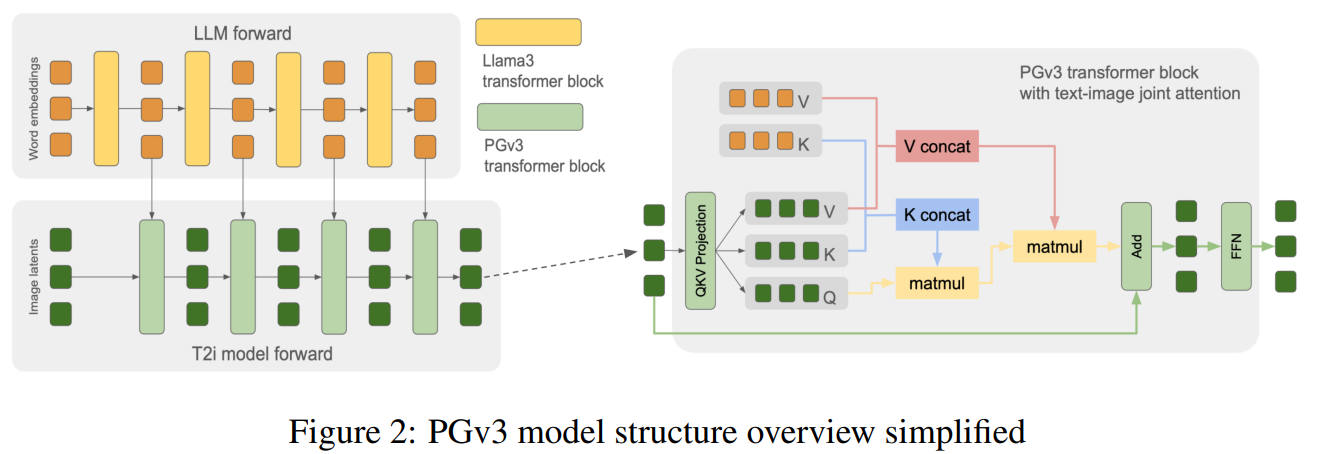
Playground v3
発表は 2024/09/16、設計の終了と学習の開始は Stable Diffusion 3(2024/02/22)の論文の発表前。
EDM スケジューラーを使っている。
2024年
出典:Playground v3: Improving Text-to-Image Alignment with Deep-Fusion Large Language Models. Bingchen Liu et al. Figure 2. https://arxiv.org/abs/2409.10695
FLUX.1
AuraFlow
Hunyuan-DiT
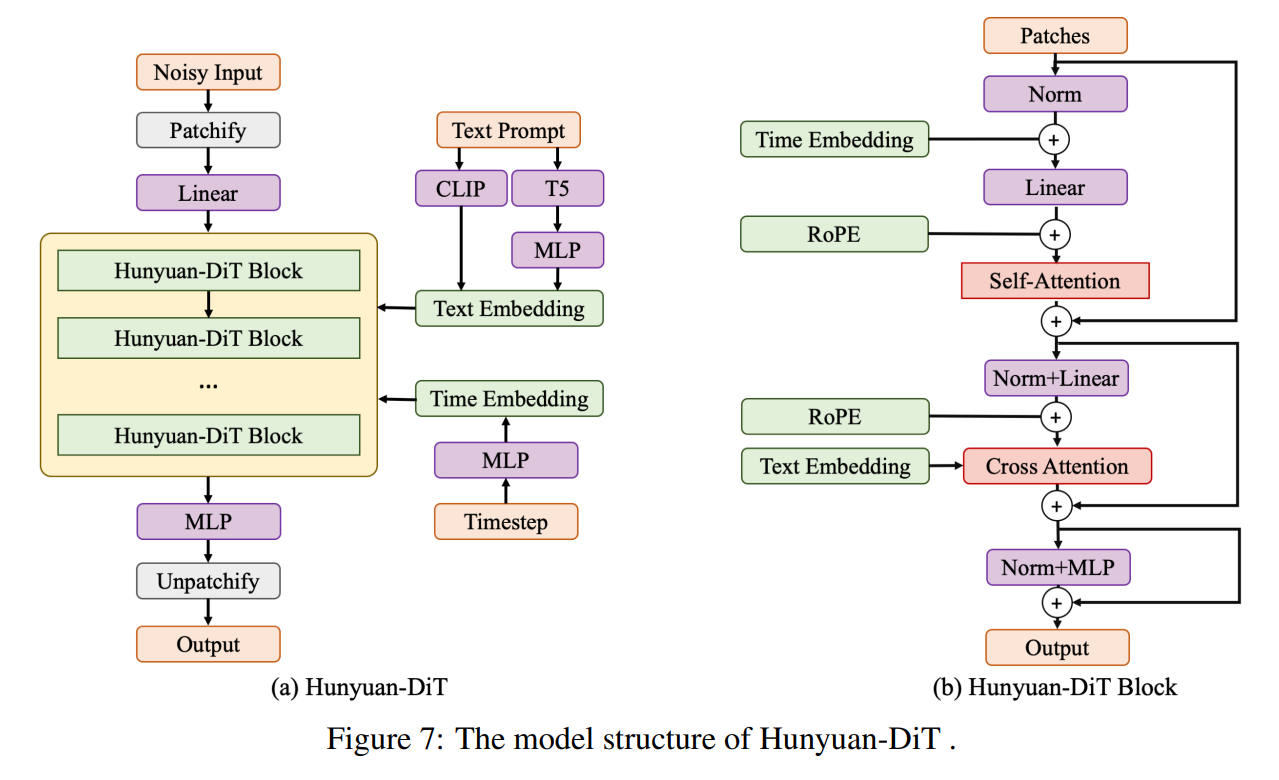
2024年
出典:Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding. Zhimin Li et al. Figure 7. https://arxiv.org/abs/2405.08748
MicroDiT
パッチマスクはパッチのランダムドロップより性能が良いのでよく使われる(BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Masked Autoencoders Are Scalable Vision Learners)。Fast Training of Diffusion Models with Masked Transformers ではマスクパッチの再構成能力を上げるためにオートエンコーダー loss を利用している。これらの従来手法はパッチのマスク率が 50% を超えると性能が低下し始め、75% を超えると大幅に性能が低下する。しかし MicroDiT は 75% のマスク率でもわずかな性能低下に抑えられる。
MicroDiT はパッチマスクを行う前に Patch-mixer でテキスト Embedding を取り込むことで性能を向上させた。Patach-mixer はアテンションと FFN で構成された数レイヤーの Transformer。
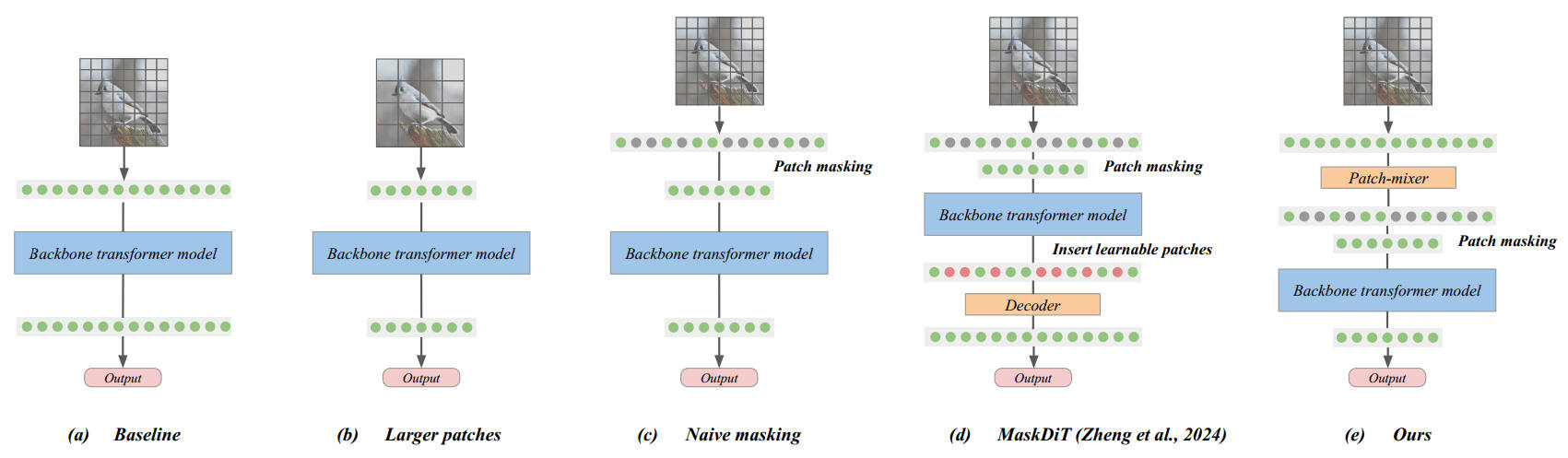
2024年
出典:Stretching Each Dollar: Diffusion Training from Scratch on a Micro-Budget Vikash Sehwag et al. Figure 2. https://arxiv.org/abs/2407.15811
パッチマスクはブロックサイズを小さくしてランダムにした方が性能低下を抑えられる。
クロスアテンションでキャプションを取り込み、位置エンコーディングとタイムステップは Sinusoidal Embedding。
損失関数。マスクした部分は、元の画像+ノイズを予測させる。
\[ \begin{split} \mathcal{L}_{diff}&=\mathbb{E}_{(\mathbf{x},\mathbf{c})\sim\mathcal{D}}\mathbb{E}_{\mathbf{\epsilon}\sim\mathcal{N}(\mathbf{0},\sigma(t)^2\mathbf{I})}\left|\left|\big(\bar{F}_\theta((\mathbf{x}+\mathbf{\epsilon})\odot(1-m);\sigma,\mathbf{c})-\mathbf{x}\big)\odot(1-m)\right|\right|^2_2\\ \mathcal{L}_{mae}&=\mathbb{E}_{(\mathbf{x},\mathbf{c})\sim\mathcal{D}}\mathbb{E}_{\mathbf{\epsilon}\sim\mathcal{N}(\mathbf{0},\sigma(t)^2\mathbf{I})}\left|\left|\big(\bar{F}_\theta((\mathbf{x}+\mathbf{\epsilon})\odot(1-m);\sigma,\mathbf{c})-(\mathbf{x}+\mathbf{\epsilon})\big)\odot m\right|\right|^2_2\\ \mathcal{L} &= \mathcal{L}_{diff} + \gamma\mathcal{L}_{mae} \end{split} \]1.16B のモデルの学習に $1,890 のコストしかかかってない。
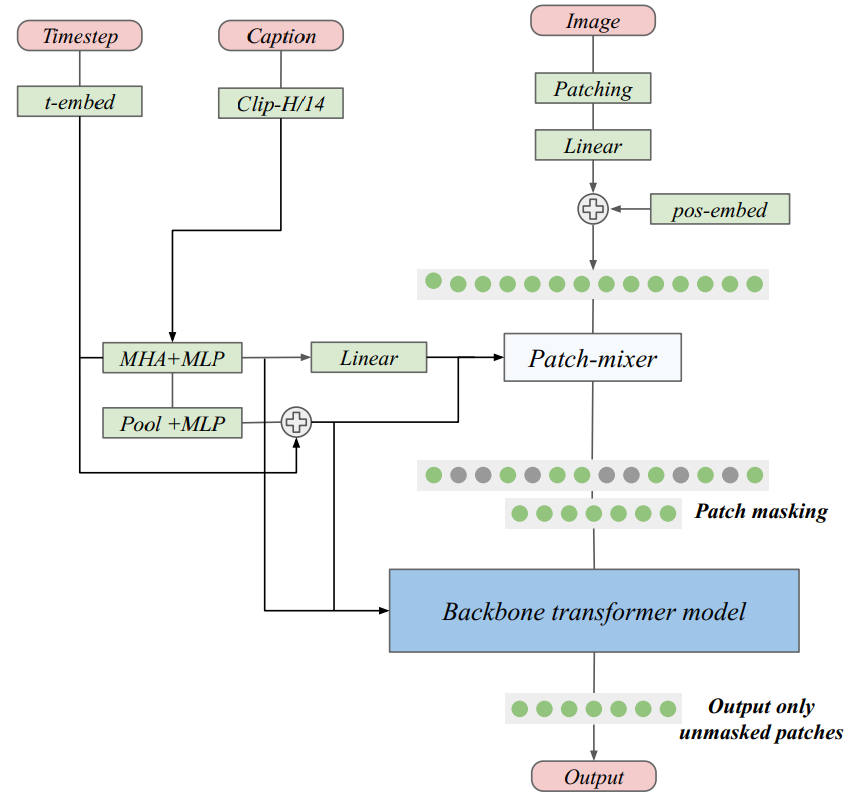
2024年
出典:Stretching Each Dollar: Diffusion Training from Scratch on a Micro-Budget Vikash Sehwag et al. Figure 3. https://arxiv.org/abs/2407.15811
AI 生成画像を学習に使う
学習画像の 40% が JourneyDB や DiffusionDB の画像データ。これらの画像を使ってもベンチのスコアは変わらないが、主観的な品質は明らかに向上する。
そこで ChatGPT にどちらの画像が質が高いか質問した。プロンプトは「Which image do you prefer, Image A or Image B, considering factors like image details, quality, realism, and aesthetics? Respond with 'A' or 'B' or 'none' if neither is preferred.」DrawBench と PartiPrompts で生成したプロンプトで、AI 生成画像を学習に含めたものと含めなかったものとで画像を生成させて ChatGPT に評価させたところ、AI 生成画像を学習に含めたモデルの生成した画像が圧勝している。

出典:Stretching Each Dollar: Diffusion Training from Scratch on a Micro-Budget Vikash Sehwag et al. Figure 9. https://arxiv.org/abs/2407.15811
CLEAR
畳み込みのような演算でアテンションの計算コストを削減する。Linear Attention で計算コストを削減したのが SANA。
Lumina-Image 2.0
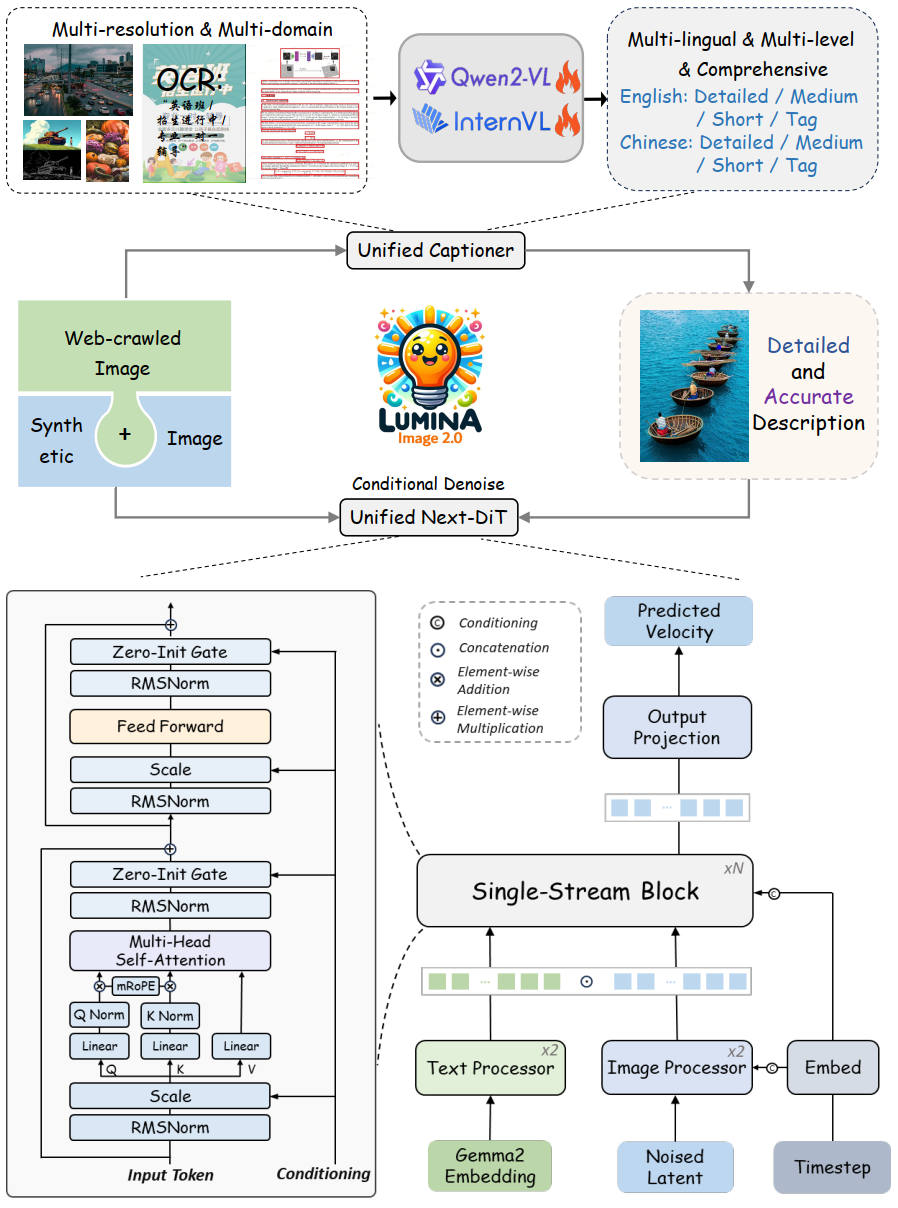
2025年
Element-wise Addition と Element-wise Multiplication は記号が逆
出典:Lumina-Image 2.0: A Unified and Efficient Image Generative Framework. Qi Qin et al. Figure 2. https://arxiv.org/abs/2503.21758
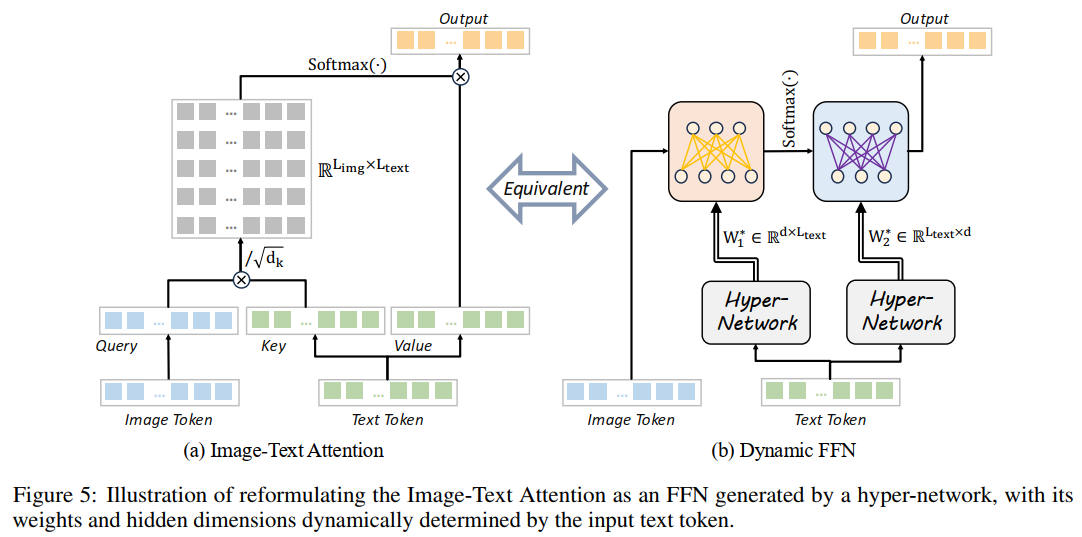
Image Text Attention は右の FFN と等価で、キャプションの量を増やせばネットワークのパラメータ数を増やすのと同じ効果がある
出典:Lumina-Image 2.0: A Unified and Efficient Image Generative Framework. Qi Qin et al. Figure 5. https://arxiv.org/abs/2503.21758
RMSNorm
RMSNorm は Layer Normalization の計算コストを削減したもの。具体的には各層の活性化に対して、平均の計算を省略し、二乗平均平方根 (Root Mean Square: RMS) のみを用いて正規化を行う。RMSNorm は LayerNorm と同等の性能を達成しつつ、計算時間を 7% 〜 64% 削減できる。
最新の pytorch には nn.RMSNorm があるので自分で実装する必要はない。
RMSNorm の実装例
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float=1e-5):
"""
基本的な役割はLayerNormと同じだが計算量が7%から64%少ない。ただし大規模なネットワークでは効果は小さい
Args:
dim (int): 入力次元
eps (float): 0 除算エラーを避けるバイアス
"""
super().__init__()
self.eps = eps
self.dim = dim
self.weight = nn.Parameter(torch.ones(dim))
self.bias = nn.Parameter(torch.zeros(dim))
def forward(self, x: torch.Tensor) -> torch.Tensor:
rms = torch.sqrt(torch.mean(x ** 2, dim=-1, keepdim=True)) + self.eps
x = x / rms
return self.weight * x + self.bias
ゲート
Gate は以下の式で表現される。ただし Normalization の後にゲートを入れる場合は、b1, b2 は、出力平均が0に近いため省略されることが多い。
\[ \displaylines{ \mathrm{Gate}(\mathbf{x}) = (\mathbf{x}W_1 + b_1) \odot \sigma(\mathbf{x}W_2 + b_2)\\ \begin{split} {\odot} &{: アダマール積(要素ごとの積)}\\ {\sigma} &{: 非線形活性化関数(\mathrm{sigmoid, GELU} など)} \end{split} } \]nn.Lienar は bias=False でバイアスを省略できる。
nn.Linear(in_features, out_features, bias=False) # バイアスなしGEGLU の実装例
import torch
import torch.nn as nn
import torch.nn.functional as F
class GEGLU(nn.Module):
def __init__(self, input_dim, hidden_dim):
super().__init__()
self.proj = nn.Linear(input_dim, hidden_dim * 2)
def forward(self, x):
x_proj = self.proj(x) # [B, T, 2*hidden_dim]
x1, x2 = x_proj.chunk(2, dim=-1) # 分割
return x1 * F.gelu(x2) # Gated
# 使用例
batch_size, seq_len, input_dim, hidden_dim = 32, 128, 512, 2048
x = torch.randn(batch_size, seq_len, input_dim)
geglu = GEGLU(input_dim, hidden_dim)
out = geglu(x) # -> [B, T, hidden_dim]
HiDream-I1
- パッチ使用
- Playground v3 のように LLM の中間出力を取り込んでいく
- FLUX.1 のようにデュアルストリームの後にシングルストリームになる
- SD3 と同じ3つのテキストエンコーダーに LLM を加え、合計4つのテキストエンコーダーを使用
- 位置エンコーディングは RoPE
- 拡散モデルでは珍しく MoE を採用している
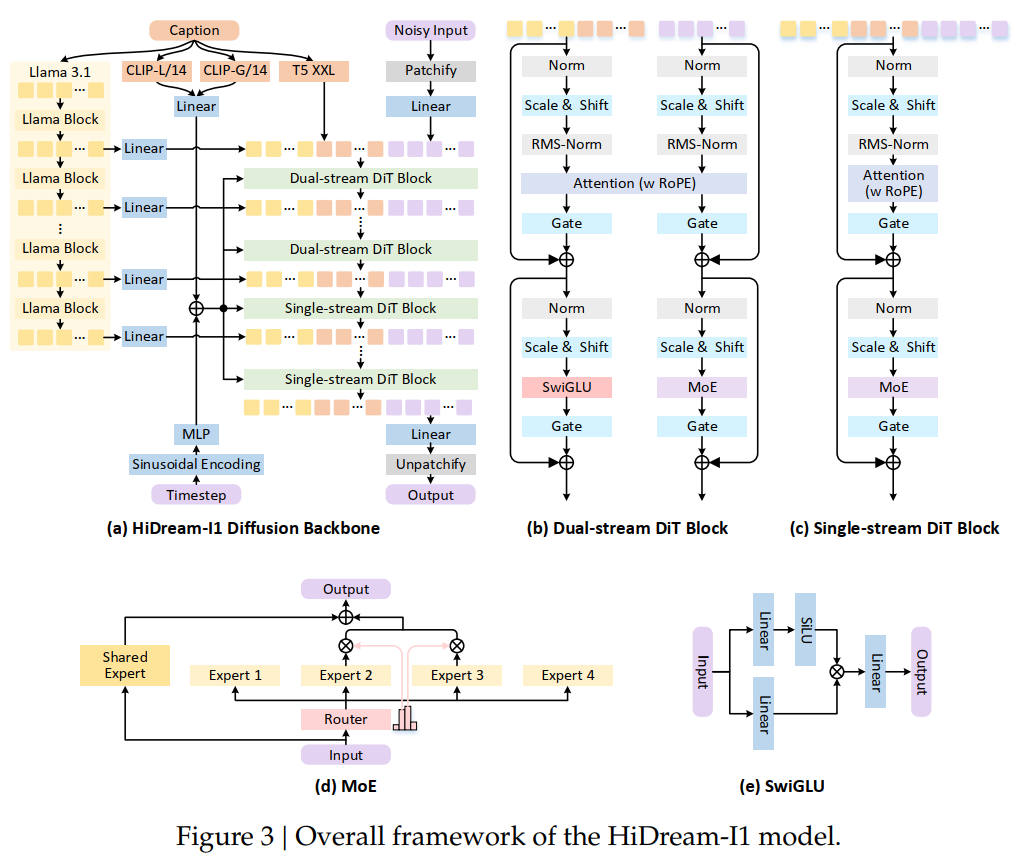
2025年
出典:HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer. Qi Cai et al. Figure 3. https://arxiv.org/abs/2505.22705
SANA
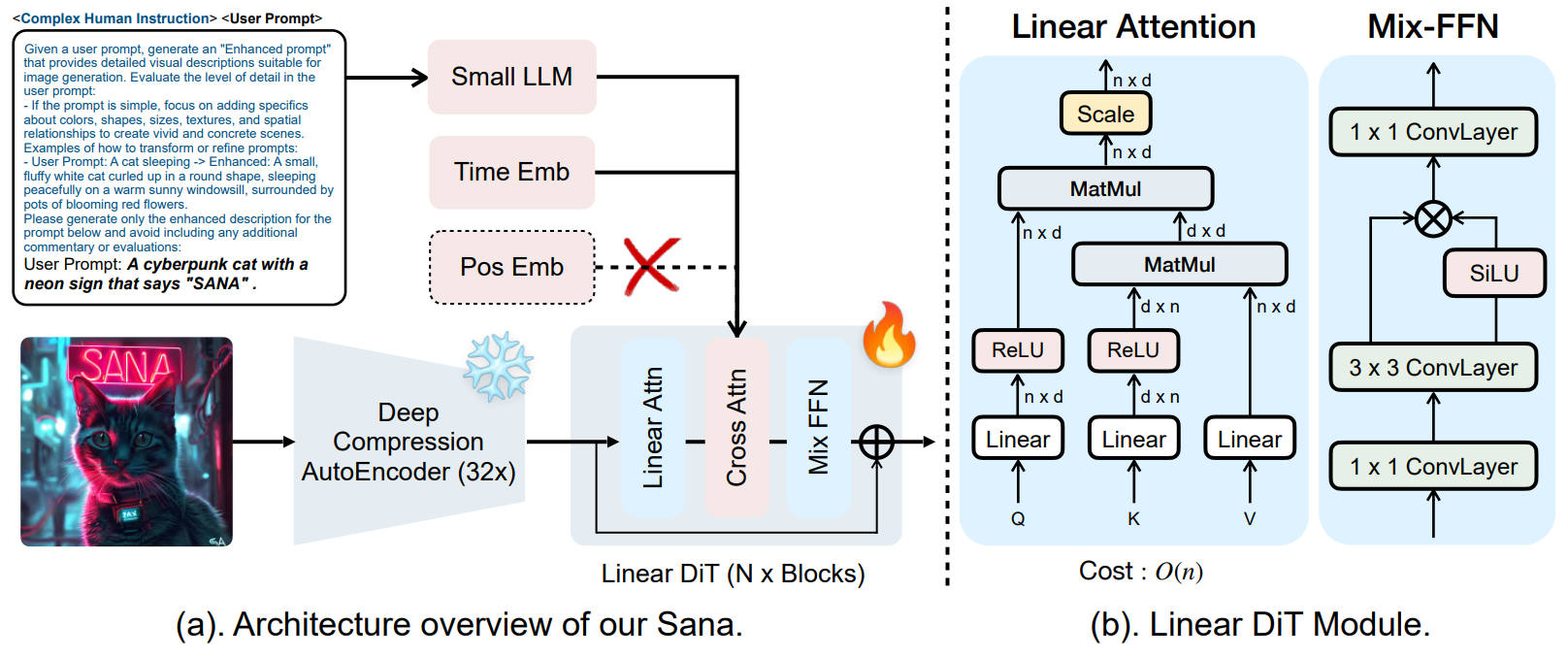
2025年
出典:SANA: Efficient High-Resolution Text-to-Image Synthesis with Linear Diffusion Transformers. Enze Xie et al. Figure 5. https://openreview.net/forum?id=N8Oj1XhtYZ
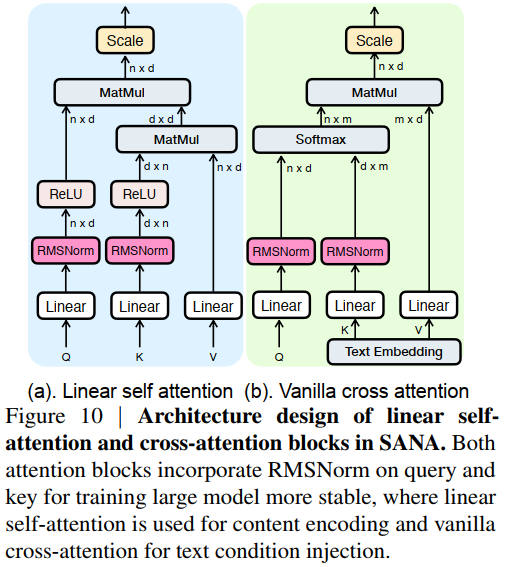
2025年
出典:SANA 1.5: Efficient Scaling of Training-Time and Inference-Time Compute in Linear Diffusion Transformer. Enze Xie et al. Figure 10. https://arxiv.org/abs/2501.18427
Linear Attention
アテンションは (QK)V の順で計算するが Linear Attention は Q(KV) の順で計算する。(QK) = n x n だが、(KV) = dmodel * dmodel 。通常のアテンションはトークン数が n とすると計算量とメモリ使用量とが O(n2) になるが、Linear Attention では O(n) になる。SD3 なら画像サイズが 1024 だと n は 4,096。
Linear Attention は高速だが性能は低下する。その低下分を Mix-FFN でカバーしている。Mix-FFN は RoPE を排除できるが、隠れ層の次元が dmodel = 2,240、dFFN = 5,600 と FFN の隠れ層の次元が巨大になっている。
畳み込み
3x3 の前の 1x1 の畳み込みによって計算量を削減している。1x1 の畳み込みはチャンネル数の次元を削減するのに使われることが多い。例えば (C, H, W) = (3, 8, 8) に 1x1 の畳み込みを実行して (1, 8, 8) にする。その後で計算コストの高い 3x3 の畳み込みを実行し、1x1 の畳み込みで (3, 8, 8) へチェンネル数を復元する。これはピクセル単位の MLP を実行しているとみることもできる。
畳み込みの出力次元数
\[ \begin{split} OH &= \dfrac{H + 2* \mathrm{padding} - \mathrm{filter size}}{\mathrm{stride}} + 1\\ OW &= \dfrac{W + 2*\mathrm{padding} - \mathrm{filter size}}{\mathrm{stride}} + 1 \end{split} \]Exploring 1x1 Convolutions in Deep Learning
パラメータ
dmodel = 2,240、dFFN = 5,600。
4.8B は 60 レイヤー。1.6B は 20 レイヤー。モデルサイズで隠れ層の次元は変わらない。
DiT-Air
ネットワークは Lumina-Image 2.0 とほぼ同じ。
DiT-Air: Revisiting the Efficiency of Diffusion Model Architecture Design in Text to Image Generation によると、テキストコンディショニングはクロスアテンションで取り込むのではなくノイズ画像と結合し、Normalize に AdaLN を使うのが最強らしい。
AdaLN のパラメータをレイヤー間で共有した場合、性能を変えずに 2.7 億個のパラメータを削減できる。アテンションレイヤー(QKVO)をレイヤー間で共有した場合、すべてのベンチでわずかに性能が低下するが、9,000 万パラメータの削減が可能。
結論としては AdaLN とアテンションレイヤーのウェイトを共有して、MLP のみ独立させるのが最もパラメータ効率が良い。
DiT-Air/L-Lite は総パラメータ数 1.15B で内訳は、CLIP/H(335M), DiT(700M), 8ch VAE(84M)。
隠れ層の次元は 64 * レイヤー数。
| モデル | レイヤー数 | 隠れ層の次元 |
|---|---|---|
| S | 12 | 768 |
| B | 18 | 1,152 |
| L | 24 | 1,536 |
| XL | 30 | 1,920 |
| XXL | 38 | 2,432 |
マルチヘッドアテンションの数はトランスフォーマーの深さと同じ。
Pixart と同じ MLP なら、トランスフォーマーブロックの隠れ層と同じ次元を持つ、2レイヤーの MLP。活性化関数は SiLU。
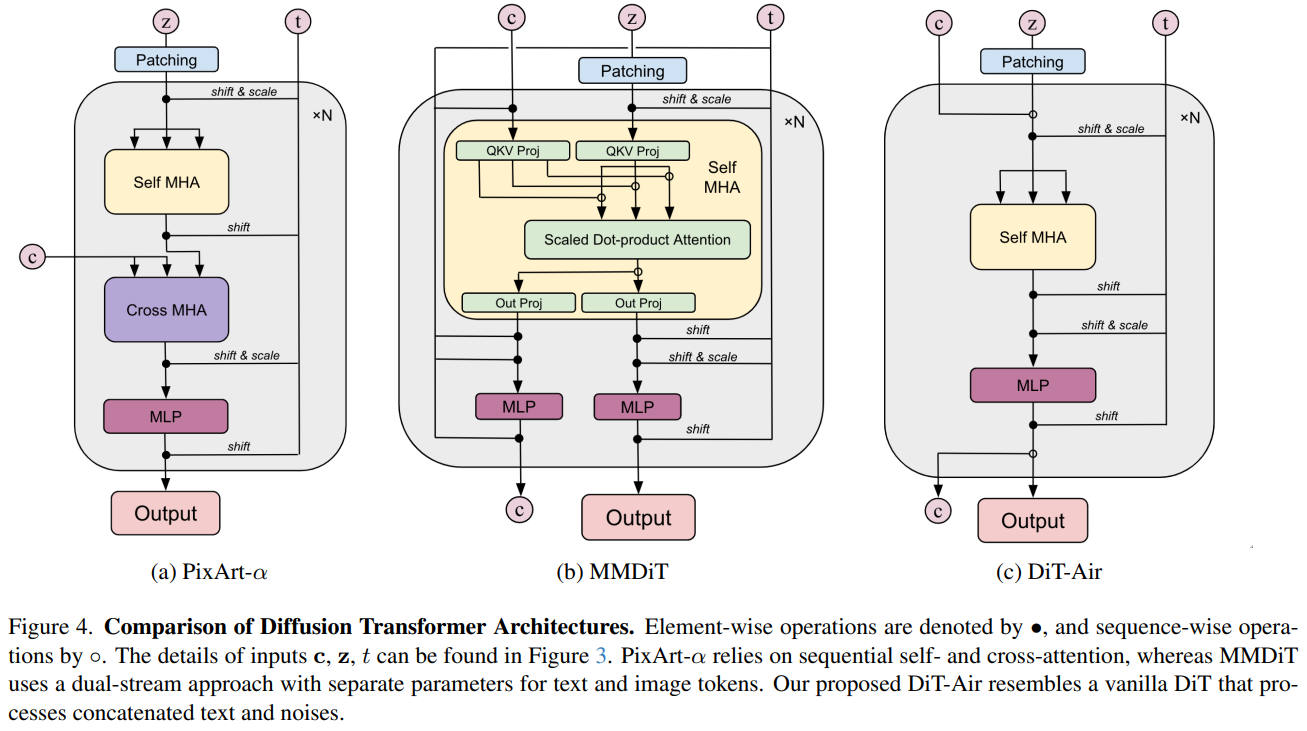
2025年
出典:DiT-Air: Revisiting the Efficiency of Diffusion Model Architecture Design in Text to Image Generation. Chen Chen et al. Figure 4. https://arxiv.org/abs/2503.10618
これは、DiT-Air/XXLでは、できる限り最も優れたモデルを提供したいと考えているためです。この場合、特に複雑なプロンプトや長文の文字表現においては、CLIP単独の場合よりも、CLIPとLLMを組み合わせることで、さらに良い性能が得られます。
— Chen Chen (@alex8937) March 14, 2025
Nitro-T
0.6B は PixArt-α に似たアーキテクチャ、1.2B は SD3 に似たアーキテクチャで、ブロック図はない。
MicroDiT で使用された Deferred Patch Masking を採用しパッチ化の性能が上がっている。
使用技術的に SANA に近い。SANA はパッチを使用しないが Nitro-T はパッチを使うところが相違点。
- テキストエンコーダーに軽量 LLM(Llama 3.2 1B)を使用
- テキストエンコーダーの出力に RMSNorm を通すことで loss を安定させている。
- VAE に 32 倍の圧縮率の DC-AE を使用
35M 枚数の学習画像の過半数が AI 生成(DiffusionDB と JourneyDB)の画像。
Qwen-Image
テキストエンコーダーに LLM を使い、SD3 を現代的にアップデートしたようなアーキテクチャ。
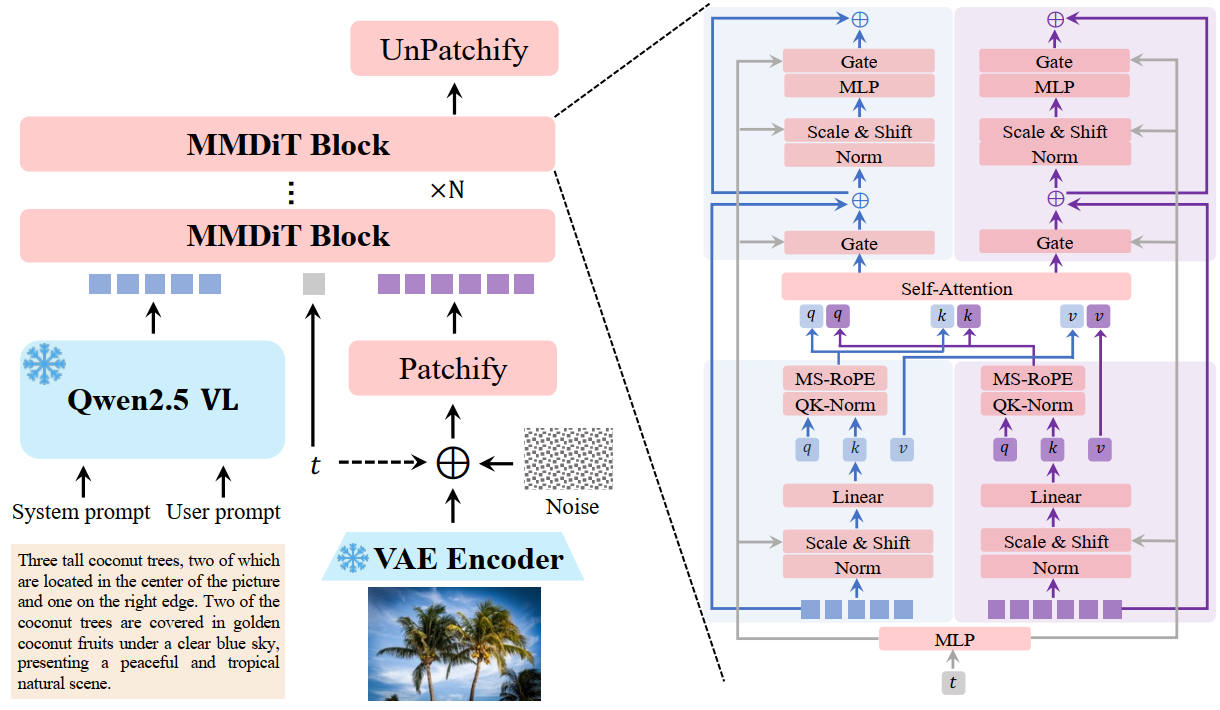
2025年
出典:Qwen-Image Technical Report. Qwen Team. Figure 6. https://huggingface.co/Qwen/Qwen-Image
PixNerd: Pixel Neural Field Diffusion
DiT で Neural Field MLP を計算し、Neural Field MLP にピクセル座標を入力して Diffusion velocity を計算する。
VAE が不要で効率的。
数式
PE(i, j) はピクセル座標 i, j を任意の次元 L にエンコーディングする。
\[ PE(i,j) = \mathrm{sin}(2^0\pi i), \mathrm{cos}(2^0\pi i), ..., \mathrm{sin}(2^L\pi i), \mathrm{cos}(2^L\pi i), ...\mathrm{sin}(2^L\pi j), \mathrm{cos}(2^L\pi j) \]DiT にノイズ画像・タイムステップ・キャプションを入力し、$X^n$ を出力する。$X^n$ は n 番目のトークン。$X^n$ を SiLU と Linear で変換して $W_1^n \in \mathbb{R}^{D_2\times D_1}, W_2^n \in \mathbb{R}^{D_1 \times D_2}$ を得る。
\[ W_1^n, W_2^n = \mathrm{Linear}(\mathrm{SiLU}(X^n)) \]$v^n(i,j)$ は PE とノイズ画像 $x^n(i,j)$ から速度 v を計算する。$x^n(i,j)$ は n 個目のノイズ画像。学習を安定させるため W は行ごとに正規化されている。
\[ v^n(i,j) = \mathrm{Linear}(\mathrm{MLP}(\mathrm{Concat}([PE(i,j), x^n(i,j)]) | {\dfrac{W_1^n}{||W_1^n||}, \dfrac{W_2^n}{||W_2^n||}})) \]HunyuanImage-2.1
FLUX とほぼ同じアーキテクチャで テキストエンコーダーに MLLM を使用している。ふたつ目のテキストエンコーダーの ByT5 はテキスト生成と多言語表現に特化してる。
SANA や Nitro-T のような 32 倍圧縮の VAE を使用し、DINOv2 を使用した REPA で効率的に学習。
HunyuanImage-2.1 の差別化ポイントは、プロンプトを水増しする Prompt Enhancer モデルと、キャプションと画像とから生成画像の品質を評価する Align Evaluator とを作成し強化学習に使っているところ。

2025年
出典:HunyuanImage-2.1 GitHub. https://github.com/Tencent-Hunyuan/HunyuanImage-2.1
HunyuanImage-3.0
パラメータ数 80B、アクティブ 13B、エキスパート数 64、アクティブエキスパ―ト 8。
ChronoEdit
2025 年 11 月。動画生成 AI を使用し TI2V で動画を生成、最終フレームを出力画像とする。直接最終画像を出力する画像編集モデルは、はめ込み合成のような画像を出力することがある。ChronoEdit は動画生成 AI を利用することで、中間フレームを reasoning フレームとして利用して品質を改善する。
FLUX.2
- テキストエンコーダーに Mistral Small 3.1(24B)を使用。max_sequence_length は 512
- FLUX.1 同様に、デュアルストリームの後にシングルストリームになる
- シングルストリームのブロックは並行 DiT。通常はアテンションの後に FFN を計算するが、並行 DiT はアテンションと FFNとを同時に計算する(つまりアテンション後の FFN がない)
- ローカルでは恩恵がないが、複数 GPU がある環境ならアテンションと FFN とを並列計算できる
- デュアルストリームブロック8に対しシングルストリームブロック 48
- AdaLNZero はパラメータ共有
- 全レイヤー bias なし
- SwiGLU に近い構造の FFN を使用
Z-Image-Turbo
すべてシングルストリームブロック。RoPE は Lumina-Image 2.0 でも使われた 3D Unified RoPE。
以下の入力すべてが連結して入力される。
- SigLip-2 Enbedding(Image Edit の場合)
- VAE Embedding(Image Edit の場合)
- プロンプト
- ノイズ画像
タイムステップは AdaLN-Zero にも入力される。画像編集タスクでは参照画像とノイズ画像とを区別するため、参照画像とノイズ画像とは別々のタイムステップでコンディショニングされる。
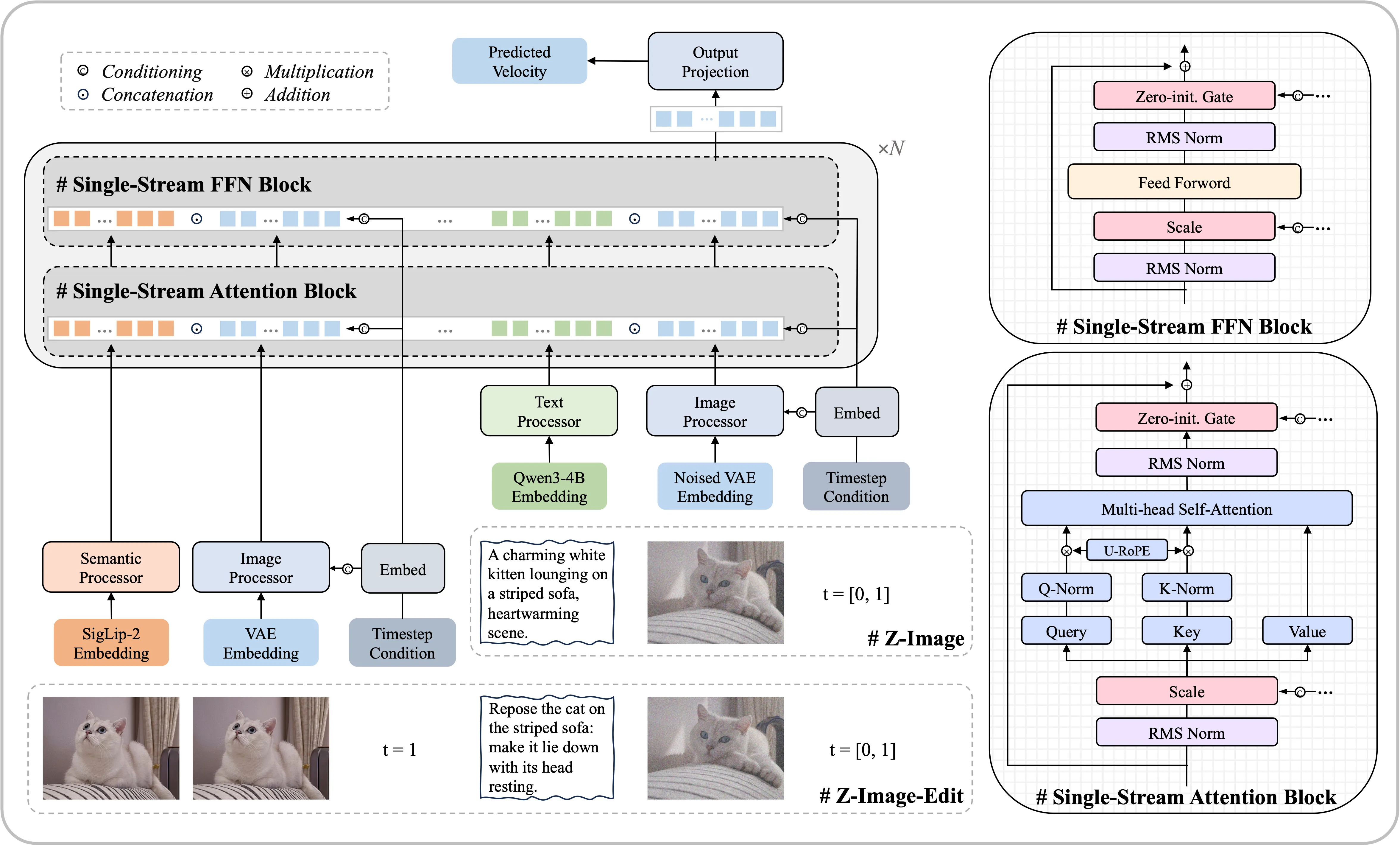
2025年 11 月
出典:https://huggingface.co/Tongyi-MAI/Z-Image-Turbo
SigLip-2 Enbedding
SigLip v2 は SigLip v1 と互換性がある。SigLip v1 のモデルに新たな複数の損失(LocCa, TIPS, SILC)とデータセットとを追加して訓練したモデルだからだ。
AIDC-AI/Ovis-Image-7B
2025年 11 月。テキスト描画に強いモデル。構造は FLUX.1 と同じ。
meituan-longcat/LongCat-Image
2025年 12 月。6B の軽量 FLUX のようなアーキテクチャ。
Qwen-Image-Layered
2025年 12 月。画像をレイヤー分解+アルファ付きに変換する。
GLM-Image
2026年1月。AR で画像を描画し、テキストの修正に拡散モデルを使う。
データセット
データとパラメータ数はセットで考える。パラメータ数だけ増やしても性能は上がらない。データに多様性がなければデータを増やしても性能は上がらない。
最近では多くても 50M 程度の教師画像枚数で学習させることが多い。仕上げのファインチューニングは1~3M枚。
MicroDiT では、生成した画像の品質評価をするために ChatGPT にどちらの画像が質が高いか質問した。プロンプトは「Which image do you prefer, Image A(first) or Image B(second), considering factors like image details, quality, realism, and aesthetics? Respond with 'A' or 'B' or 'none' if neither is preferred.」これは、ローカルの Gemma3 でも実行できる。意味があるかどうかはわからないが「Tell me the reason.」で理由も聞ける。データセットの画像の厳選にも使える。
Sub-Scaling Laws: On the Role of Data Density and Training Strategies in LLMs
LLM ではモデルのパラメータ数が増えると性能向上率が悪化する。その原因はデータの多様性の不足と、学習のさせすぎだ。
論文ではデータをクラスタ分けしてデータの多様性を計測する方法や、Over-Training Ratio の概念を紹介している。
Achieving 10,000x training data reduction with high-fidelity labels
広告分類タスクで、ファインチューニングに必要なデータ量を1万分の1にする。
データをクラスタリングして、境界線上にあり、複数のクラスタに属しているものをファインチューニングに使う。
NoHumansRequired: Autonomous High-Quality Image Editing Triplet Mining
画像・修正指示・修正後の画像のデータセット、の公開と、データセットの作成方法についての解説。
Alchemist: Turning Public Text-to-Image Data into Generative Gold
拡散モデルを使って、大量の学習画像の中から、その拡散モデルで学習効率のいい SFT 用のデータをフィルタリングする。
- NSFW フィルタ
- 解像度フィルタ
- 美的フィルタ
- ウォーターマークフィルタ
- 粗い品質フィルタ
- 圧縮ノイズ
- モーションブラー
- 露出ミス
- 詳細な品質フィルタ
- 重複除去(類似画像も除去し最も美的スコアが高いものを残す)
- 拡散モデルを使用したフィルタ
- キャプションに "high quality", "artistic", "aesthetic", "complex" などを入れ、I2I を実行してクロスアテンションの出力を見る。
著作権について
平成30年著作権法改正により学習は合法。ただしモデルが著作権侵害コンテンツを高頻度で生成する場合、モデルの公開・販売や画像生成サービスの提供は複製権侵害になる。
danbooru タグの artist, copyright, character タグを学習させたモデルは複製権侵害のリスクが非常に高い。
便利ツール
データセット
データセットは画像 URL とキャプションとのペアで提供される。画像のライセンスは画像の所有者ごとに異なる。以下のリストのライセンスが書いていないデータセットの画像のライセンスは画像所有者依存。
商用利用可能な大規模なデータセットは flicker ぐらいしかない。flicker は CC0 で画像を提供すれば無限のストレージが利用できる。
よく使われるデータセット
ImageNet:商用不可
Segment Anything 1B(Meta):Apache 2.0 License だが商用利用不可
AI 生成画像(多様性があり学習に使うと性能が上がる)
JourneyDB:商用不可。商用利用したければプロンプトから自作すればよい。$100万を超える売り上げのある企業は有料プランに加入しないと資産を所持できない。Midjourney は著作権侵害コンテンツを平気で生成してくるので、プロンプトと生成した画像との厳選は必要になる。
CC0
soa-full-florence2 はスミソニアン協会が公開している情報をもとにmadebyollin氏が作成したCC-0の絵画などを集めた画像リンク集。古いものが多く、メインのデータセットにはならない。
flicker
megalith-10m(flicker 画像のキュレーション)
次点
Open Images Dataset V7(Google):画像は CC BY 2.0 だが個々の画像のライセンスには Google は関知しない、キャプションは CC BY 4.0
DOCCI Descriptions of Connected and Contrasting Images
Unsplash:Unsplash ライセンス(商用可能、転売は不可)
LAION-5B:低品質な画像が多く使われなくなってきている
データの水増し
OmniGen2 は動画から画像を切り出して、学習に使用している。
Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing。LLM のケースだが、AI にデータを作成させる方法の紹介。
データの分類
OmniGen2 ではデータを以下のように分類し、均等になるようにしている。
- キャラ
- 男
- 女
- 子供
- 老人
- アニメキャラ
- オブジェクト
- バーチャル
- 食べ物
- 人工物
- 植物
- 動物
- シーン
- コマーシャル
- ランドマーク
- 地方(Domestic)
- 都市(Urban)
- 自然(Natural)
キャプショニング
データセットが提供するキャプションを使うのではなく、LLM で画像のキャプション付けを行うのが一般化している。
解像度を下げる場合は、キャプションを作り直す必要はない。しかし画像をクロップした場合は、キャプションを作り直す。
danbooru タグを使う方が細かい制御が効くので、自然言語のキャプションと danbooru タグのキャプションとをランダムキャプショニングで学習させる方が便利。
LLM で以下の情報を抽出する。単に「車」と記述するのではなく、「通りを走る車」のようにアクションを記述させる。
- 人
- 人数
- 人の表情・感情
- ポーズ・姿勢:例:「走っている子供」、「ベンチに座っている人」
- 身体属性:例:「長い金髪の女性」、「ふわふわの毛の犬」
- 年齢・身長・性別
- 相互作用:例:「握手している二人」、「ボールで遊んでいる犬」
- 服の種類
- 物
- 物の画面内での位置
- オブジェクト間の相対的位置
- 物色、パーツの色
- 形状
- 材質
- サイズ
- 動物の種類
- 背景の詳細: 例:「都市の景観」、「穏やかな森」
- 室内か屋外か
- 全体的な雰囲気/ムード:例:「賑やかな通り」、「平和な庭」
- カメラ・ポストエフェクト(blurry background, chromatic aberration, from below など)
- 人や物の位置関係
- 文字の位置と文字
- 時間帯
- 照明条件:例:「明るい昼光」、「薄暗い夕方の光」
- 季節
- 天候
ランダムキャプショニング
キャプションが複数ある場合は、キャプションをクリップスコアで評価し、正規化することで確率的にキャプションを選択する手法がある。
\[P(c_i) = \frac{exp(c_i/\tau)}{\sum_{j=1}^N exp(c_j/\tau)} \]c は CLIP スコアで、t は温度。0に近い値にすると常に最も高いスコアのキャプションが選択される。
長すぎるプロンプト問題
DetailMaster: Can Your Text-to-Image Model Handle Long Prompts? では長すぎるプロンプトが性能を低下させることを報告している。
The Intricate Dance of Prompt Complexity, Quality, Diversity, and Consistency in T2I Models
キャプションの長さと美的スコアや多様性を調査した論文。キャプションが長いと多様性が低下し再現性が向上するが、美的スコアが低下する。美的スコアを最大化するにはキャプションは長すぎても短すぎてもよくないことを明らかにした。
Collage Prompting
従量課金の MLLM は画像枚数あたりで課金されるため、Collage Prompting では複数の画像を1枚にまとめてキャプションを作成する方法を紹介している。
danbooru タグを利用したプロンプト例
Deepdanbooru 等でタグをつけて、そのタグを LLM・VLM に入力する。
画像につけられたタグを参考に画像のキャプションを作成してください。余計な応答は出力せず、キャプションだけを出力してください。 # 方針 - 人物の位置(左・中央・右)やオブジェクトの位置(上下左右)は必ず書いてください - テキストが存在する場合はダブルクオート "" で囲んでください - 服装・表情・髪や服の色・ポーズ・髪型は必ず書いてください。 # タグ danbooru タグのリスト 余計な応答は出力せず、キャプションだけを出力してください。
プロンプト例
| カテゴリ | 説明 | プロンプト |
|---|---|---|
| 直接キャプショニング | 画像全体を包括的に記述する。MLLMのゼロショット能力を活用。 | 「この画像を詳細に記述してください。」 「画像の内容を包括的な段落で説明してください。」 |
| きめ細かい指示生成(Q&A形式) | 特定のオブジェクト、属性、関係性について質問と回答のペアを生成させる | 「画像内のオブジェクトの色、サイズ、素材、形状について質問と回答のペアを生成してください。」 「画像内の人物の行動と、彼らが他のオブジェクトとどのように相互作用しているかについて質問と回答を生成してください。」 |
| 属性ベースの拡張 | 既存の簡潔なキャプションに、きめ細かい属性(色、サイズなど)や空間的関係を追加して詳細化させる。 | 「このキャプションを、画像内のすべてのオブジェクトの具体的な色、サイズ、素材、形状、およびそれらの正確な空間的配置を含めて拡張してください。」 |
| シーン・文脈の豊かさ | 画像の全体的な雰囲気、照明、時間帯、背景の詳細などを記述させる。 | 「この画像の全体的なムード、時間帯、照明条件、および背景の環境を詳細に記述してください。」 |
| 人物・動物のインタラクション強調 | 画像内の人物や動物の行動、感情、相互作用に焦点を当てて記述させる。 | 「画像内の人物の表情、ポーズ、および彼らが互いに、または周囲のオブジェクトとどのように相互作用しているかを詳しく説明してください。」 |
| T2Iモデル向け最適化 | T2Iモデルの訓練データ分布に合わせた構造や表現でキャプションを生成させる。 | 「Text-to-Imageモデルのプロンプトとして最適化された形式で、この画像を記述してください。タグ形式または詳細な段落形式で、可能な限り多くの視覚的詳細を含めてください。」 |
| コスト効率化(コラージュプロンプティング) | 複数の画像を1つの入力として処理し、それぞれの詳細を記述させる。 | 「提供されたコラージュ内の各画像を個別に識別し、それぞれについて詳細なキャプションを生成してください。」 |
参考文献
Unleashing Text-to-Image Diffusion Prior for Zero-Shot Image Captioning
To See is to Believe: Prompting GPT-4V for Better Visual Instruction Tuning
DetailMaster: Can Your Text-to-Image Model Handle Long Prompts?
L-CLIPScore: a Lightweight Embedding-based Captioning Metric for Evaluating and Training
キャプション付けをするモデルを訓練する際に、モデルの書いたキャプションが正しいかどうか評価する必要がある。BLUE や CIDEr はキャプションが正しいかどうかの判定に、ある単語を含むかどうかで評価する。これは問題が多い。パラフレーズを評価できないし、間違った文や語に対するペナルティもほとんどない。
エッジデバイス向けの論文。
プロンプト例
Improving Image Generation with Better Captions
Prompting Vision Language Models
Synth2: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Improving face generation quality and prompt following with synthetic captions
Dual Caption Preference Optimization for Diffusion Models
Structured Captions Improve Prompt Adherence in Text-to-Image Models (Re-LAION-Caption 19M)
スケジューラー
DDPM
\[ x_t = \sqrt{\bar{\alpha}_t}x_0 + \sqrt{1-\bar{\alpha}}\epsilon, \; \epsilon \sim \mathcal{N}(0, I) \\ \alpha_t = 1 - \beta_t, \; \bar{\alpha}_t = \prod^t_{i=1}\alpha_i \\ \sigma_t = \sqrt{1-\bar{\alpha}_t} \]Linear beta schedule
\[ \beta_t = \beta_{\mathrm{min}} + \dfrac{t-1}{T-1}(\beta_{\mathrm{max}} - \beta_{\mathrm{min}}) \]import torch
def ddpm_linear_sigma(T, beta_min=1e-4, beta_max=0.02, device="cpu"):
betas = torch.linspace(beta_min, beta_max, T, device=device)
alphas = 1.0 - betas
alpha_bar = torch.cumprod(alphas, dim=0)
sigmas = torch.sqrt(1.0 - alpha_bar)
return sigmas # shape: [T]
Cosine schedule (Improved DDPM)
Alex Nichol, Prafulla Dhariwal, Improved Denoising Diffusion Probabilistic Models
\[ \large{ \bar{\alpha}_t = \dfrac{\mathrm{cos}^2 ( \frac{t/T+s}{1+s} \frac{\pi}{2} )} {\mathrm{cos}^2 ( \frac{s}{1+s} \frac{\pi}{2} )} \\ \sigma_t = \sqrt{1-\bar{\alpha}_t} } \]import torch
import math
def cosine_sigma(T, s=0.008, device="cpu"):
t = torch.arange(T + 1, device=device)
f = torch.cos((t / T + s) / (1 + s) * math.pi / 2) ** 2
alpha_bar = f / f[0]
sigmas = torch.sqrt(1.0 - alpha_bar[1:])
return sigmas # shape: [T]
Karras sigma schedule (Stable Diffusion /EDM 系)
Karras et al. Elucidating the Design Space of Diffusion-Based Generative Models
現在の画像生成で最も実用的に使われている σ 定義。
- $\sigma_{\mathrm{max}}$:初期ノイズ
- $\sigma_{\mathrm{min}}$:最終ノイズ
- $\rho$:分布形状(典型値7)
import torch
def karras_sigmas(
n_steps,
sigma_min=0.002,
sigma_max=80.0,
rho=7.0,
device="cpu",
):
i = torch.linspace(0, 1, n_steps, device=device)
sigmas = (
sigma_max ** (1 / rho)
+ i * (sigma_min ** (1 / rho) - sigma_max ** (1 / rho))
) ** rho
return sigmas # shape: [n_steps]
EDM 系では、σ がモデル入力の正規化・損失重みにも直接使われる:
\[ \lambda(\sigma) = \dfrac{1}{\sigma^2} \]学習方法
低解像度で学習した後、高解像度の学習を行い、最後に高品質な画像だけを使った仕上げを行う。
8倍圧縮の VAE の場合は 256 x 256 の解像度で事前学習を行うが、32 倍圧縮の VAE を使う SANA や Nitro-T では 512 x 512 から事前学習を始めている。
Scaling Laws For Diffusion Transformers によると、事前学習の loss もスケーリング則に従う。スケーリング則から、最適なモデルサイズと必要なデータセットの量が計算できる。
Pre-training under infinite compute によると、データ制約下では正則化とアンサンブル学習で性能を向上させられる(ただし大量の計算リソースが要求される)。
Exponential Moving Average of Weights in Deep Learning: Dynamics and Benefits
エポックごとにモデルのコピーを保存しておいて、EMA を使ってモデルの平滑化を行う。たいていは学習の最終段階のファインチューンの時にのみ行われる。
サンプルコードは Model EMA (Exponential Moving Average) を参照。
On the Scalability of Diffusion-based Text-to-Image Generation
隠れ層の次元を増やすよりトランスフォーマーブロックを増やした方が性能が上がる。データセットは質と多様性が重要で、量は重要ではない(現状十分な量の画像が手に入る)。
マスク
MaskGIT: Masked Generative Image Transformer ノイズ+マスクで学習させる。
MADI: Masking-Augmented Diffusion with Inference-Time Scaling for Visual Editing ノイズ+マスクで学習し、推論時にはパディングトークンを追加することで性能を上げる。
Classifier Free Guidance
一定確率(10%前後)でキャプションなしで学習させることで、CFG が使えるようになる。CFG は品質を大きく向上させるが、蒸留モデルでは使えないことが多い。蒸留モデルのみを公開する場合は CFG 学習をしない選択もある。
Adaptive Projected Guidance
ELIMINATING OVERSATURATION AND ARTIFACTS OF HIGH GUIDANCE SCALES IN DIFFUSION MODELS
CFG をデノイズ画像と直交する方向と平行方向とに分解したとき、平行方向ベクトルが彩度を高めることを発見した。なので直交方向のみスケールを効かせることで高い CFG での高彩度化を抑えることに成功した。
APG に追加の学習は不要で CFG が使えれば使える。
DiffIER: Optimizing Diffusion Models with Iterative Error Reduction
CFG のエラー補正技術。
S2-GUIDANCE: STOCHASTIC SELF GUIDANCE FOR TRAINING-FREE ENHANCEMENT OF DIFFUSION MODELS
S2-GUIDANCE は CFG に加えて、タイムステップごとにランダムに DiT ブロックを一つスキップしたものを引き算する。
CFG 比で性能は向上するが、1ステップに3回推論する(CFG は2回)ので、費用対効果は悪い。
Normalized Attention Guidance: Universal Negative Guidance for Diffusion Models
プロンプトとネガティブプロンプトとでアテンションの KV を作成し、引き算することで CFG と同等のことができる。
Reinforcement Learning Guidance
強化学習は本質的に CFG の学習と同じなので、強化学習なしのモデルのノイズ予測から、強化学習済みのモデルのノイズ予測を引くことで CFG のように動的に強化学習の影響力を調整できる。
強化学習のモデルを LoRA 化する方が便利だと思われる。
Inference-Time Alignment Control for Diffusion Models with Reinforcement Learning Guidance
学習率スケジューラー
CosineAnnealingLR のような学習率が上下するスケジューラーは局所的最適解を避けられる。
from torch.optim import lr_scheduler
# T_max: 学習率が最小値に達するまでのエポック数。総エポック数の 1/5 程度が目安
# eta_min: 学習率の最小値。0に設定するコード例が多いが、計算資源の無駄でしかない
scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=20, eta_min=1e-5)
# optimizer.step() の代わりに scheduler.step() を呼び出す
scheduler.step()
タイムステップスケジューラー
タイムステップは通常 0~1,000 の間でランダムに選択される。
A Closer Look at Time Steps is Worthy of Triple Speed-Up for Diffusion Model Training によると、タイムステップの後半は Loss が小さく学習が遅いので、前半(250 前後)に集中して学習させることで3倍学習が高速になる。
Disentanglement in T-space for Faster and Distributed Training of Diffusion Models with Fewer Latent-states
タイムステップを 1,000 より少なくした方が学習が速いという論文。T=8 だと性能が低いが、T=16 以上は性能差がほとんどない。
ノイズスケジューラー
ノイズスケジューラーのまとめは Noise schedules considered harmful を参照。
Stable Diffusion 1.5 や XL はスケジューラーにバグがあり、色の再現性の低下や高解像度での分裂などの問題を引き起こしていた。Stable Diffusion 3 ではタイムステップを以下の式で変換することで高解像度での分裂等に対処している。色の再現性は ZTSNR や Rectified Flow を採用することで改善されている。
\[ \displaylines{ \begin{split} t_m &= \dfrac{\sqrt{\frac{m}{n}} t_n}{1 + (\sqrt{\frac{m}{n}}-1)t_n}\\ {t_m} &{= 変換後のタイムステップ}\\ {t_n} &{= 変換前のタイムステップ}\\ {n} &{= ベース画素数。SD3 は 1,024 \times 1,024}\\ {m} &{= 生成する画像の画素数} \end{split} } \]
${x_t = \sqrt{\gamma}\cdot x_0 + \sqrt{1-\gamma}\cdot \epsilon : \gamma = 0.7}$
高解像度の画像の情報を破壊するにはより多くのノイズが必要になる
出典:On the Importance of Noise Scheduling for Diffusion Models. Ting Chen. Figure 2
ZTSNR(Zero Terminal SNR)
Common Diffusion Noise Schedules and Sample Steps are Flawed では、T=1000 まで学習すべきなのに T=999 で止まるノイズスケジューラーのバグを指摘している。
Input Perturbation Reduces Exposure Bias in Diffusion Models
学習時、ネットワークは実際の画像にノイズを乗せたものを使って学習するが、推論時には自分の推論結果からノイズを徐々に除去していく。これは exposure bias 問題に似ていて、エラーが蓄積していく。
そこで学習時に追いノイズによってこのバイアスを除去する。以下の式の $ \sqrt{1+\gamma^2}$ が追いノイズの部分。
\[ \begin{split} \mathbf{y} &= \sqrt{\bar{\alpha}_t \mathbf{x}_0} + \sqrt{1-\bar{\alpha}_t}\sqrt{1+\gamma^2}\mathbf{\epsilon}\\ \gamma &= 0.1 \end{split} \]A Comprehensive Review on Noise Control of Diffusion Model
以下のノイズスケジューラーのレビュー。
- Linear
- Fibonacci
- Cosine
- Sigmoid
- Exponential
- Cauchy distribution
- Laplace distribution
- Logistic
- Monotonic neural network
高解像度では Cosine より Sigmoid の方が良い。
Improved Noise Schedule for Diffusion Training
ノイズスケジューラ―の Laplace, Cauchy は logSNR=0(つまり純粋なノイズ)の時の学習効率と品質がよい。
参考文献
Common Diffusion Noise Schedules and Sample Steps are Flawed
On the Importance of Noise Scheduling for Diffusion Models
Diffusion Noise Optimization (DNO)
Noise schedules considered harmful
Group Diffusion: Enhancing Image Generation by Unlocking Cross-Sample Collaboration
バッチ生成するさいに、他のバッチの内容を見れるようにすることで画質を上げる。
損失関数の重みづけ
Debiased Estimation Loss
モデルの再構成誤差に $ \dfrac{1}{\sqrt{\mathrm{SNR(t)}}}$ を掛けるだけ。v prediction の場合は、$ \dfrac{1}{\mathrm{SNR(t)} + 1} $。
\[ \begin{split} L &= \sum_t \mathbb{E}_{x_0,\epsilon} \left[ \frac{1}{\sqrt{\mathrm{SNR(t)}}} ||\epsilon - \epsilon_{\theta}(x_t, t)||^2 \right]\\ \alpha :&= \prod^t_{s=1}(1-\beta_s)\\ \mathrm{SNR}(t) &=\dfrac{\alpha_t}{1-\alpha_t} \end{split} \]Rectified Flow の場合
SD3 では以下の式で損失関数を重みづけしてる。ノイズが大きい部分のウェイト大きくなる。T=0, 1 の時ウェイトが0に近い。$ \lambda^{\prime}$ は SN 比の微分。
\[ \begin{split} \mathrm{logit}(t) &= \mathrm{log} \; \dfrac{t}{1-t}\\ \pi_{\mathrm{ln}}(t;m,s) &= \dfrac{1}{s\sqrt{2\pi}}\dfrac{1}{t(1-t)} \mathrm{exp} \left (-\dfrac{(\mathrm{logit}(t)-m)^2}{2s^2}\right ) \end{split} \]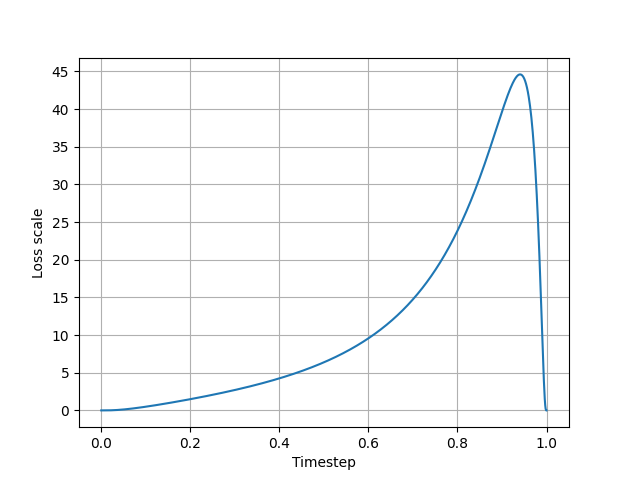
横軸はタイムステップ、縦軸は$\pi_{ln}(t; 0.00, 1.00)(\dfrac{\sigma_t\lambda^{\prime}_t}{2})^2$
$\lambda^{\prime} = 2(\frac{a^{\prime}_t}{a_t} - \frac{b^{\prime}_t}{b_t})$
$\sigma_t = a = t$
$b = 1 - a$
a' と b' はそれぞれ a と b の微分
プロットコード
import math
import matplotlib.pyplot as plt
num_sample = 1000
#f = lambda x: x
old_a = 0
old_b = 1
dt = 1/num_sample
def f(t,m=0,s=1):
if t==0 or t==1:
return 0
global old_a, old_b
a = t # [0, 1]
b = 1 - a
sigma_t = t
logit = lambda x: math.log(x) - math.log(1-x)
coeff = 1/(s*math.sqrt(2*math.pi) * t * (1-t))
logit_coeff = coeff * math.exp(-(logit(t)-m)**2 / 2*s*s)
diff_a = (a - old_a)/dt
diff_b = (b - old_b)/dt
diff_lambda = 2*(diff_a/a - diff_b/b)
old_a = a
old_b = b
return logit_coeff * (sigma_t * diff_lambda / 2)**2
inputs = [i/num_sample for i in range(num_sample+1)]
outputs = [f(x) for x in inputs]
title = ''
label_x = 'Timestep'
label_y = 'Loss scale'
flg = plt.figure()
ax = flg.add_subplot()
ax.plot(inputs, outputs)
ax.set_title(title)
ax.set_xlabel(label_x)
ax.set_ylabel(label_y)
# グリッド線
ax.grid(axis='x') # グリッド線の表示:X軸
ax.grid(axis='y') # グリッド線の表示:Y軸(点線)
ax.set_yticks(range(0, 50, 5))
flg.show()
plt.show()Huber loss
学習速度と外れ値の影響力にはトレードオフがある。学習速度の速い L2 loss は外れ値に弱い。L1 smooth は外れ値に強いが学習は遅い。
Huber loss は δ を変化させることで L2 と L1 の中間を作れる。 δ を上げるとなだらかな L2 に近くなり、下げると L1 に近くなる。
\[ H_\delta(x) = \delta^2 \left ( \sqrt{1+\dfrac{x^2}{\delta^2}-1} \right ) \]Improving Diffusion Models's Data-Corruption Resistance using Scheduled Pseudo-Huber Loss
小さいモデルを先に訓練する
SANA 1.5 では 1.6B を作成した後、学習済みの 1.6B にブロックを追加して 4.8B にしてから学習させることで、4.8B の学習時間を 60% 削減している。
蒸留
性能向上の面から見れば小さいモデルは、大きなモデルから蒸留した方が性能はよくなる。
詳細は蒸留技術まとめを参照。
Subliminal Learning: Language models transmit behavioral traits via hidden signals in data
蒸留するモデルのアーキテクチャが同じ場合、教師モデルの欠点も伝達されることを発見した。これは教師モデルの出力から問題のある出力をフィルタリングしても伝播を防げない。
しかしモデルのアーキテクチャを変えたり、インコンテキスト学習を利用した場合はこの現象は起こらない。つまりデータに問題があるのではなく、モデルとデータの組み合わせの問題の可能性が高い。
大きいモデルのブロックを削減して小さいモデルを作成する
SANA 1.5 では大きなモデルの推論時のブロックの入力と出力との類似度を計算し、性能に貢献していないブロックを削除する。その後でファインチューニングすることで小さいモデルを作成している。ブロック削除後のファインチューニングはたった 100 ステップ程度で十分。
SLEB: Streamlining LLMs through Redundancy Verification and Elimination of Transformer Blocks ではトランスフォーマーブロックの入力と出力との類似度をコサイン類似度で計算している。
Do Language Models Use Their Depth Efficiently? はコサイン類似度と残差ストリームとを使用して分析している。
画像編集
画像編集の学習時にノイズの乗った画像と元画像とを結合して入力する。これによって、モデルは元画像を常に参照できるので不要な部分を変更しない編集の性能が上がる。
画像編集はプロンプトでマスクを作成し、マスク部分に I2I を実行しているだけだ。画像のマスクと違い、プロンプトマスクは潜在空間ベクトルレベルでマスク可能なのが違いだ。
- FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
- Qwen-Image Technical Report
- HIVE: Harnessing Human Feedback for Instructional Visual Editing
Stable Diffusion Models are Secretly Good at Visual In-Context Learning
セルフアテンションの K, V にタスクに対応した画像を入力すると、学習していなくても以下のタスクが実行できる。これはモデルの再学習なしで実現可能。
- セグメンテーション
- セマンティックセグメンテーション
- 物体検出
- キーポイント(関節など)検出
- 輪郭抽出
- 彩色
省メモリ学習
省メモリ技術
- 8-bit Optimizers(AdamW, CAME)
- Gradient Checkpointing
- Gradient Accumulation(バッチサイズによるが、最もメモリ削減効果が大きい)
- Freezing embeddings
- AMP(Automatic Mixed Precision)(NVIDIA GPU のみ。Tensor コア使用。学習が最大2倍高速化する効果もある)
8-bit Optimizers
8bit AdamW は bitsandbytes をインストールすると使える。ただし CNN を多用する VAE では効果は小さい。
bitsandbytes
枯れたバージョンの CUDA を使用しているなら普通にインストールする。
!python -m pip install bitsandbytes
使用している CUDA のバージョンに対応したものをインストール場合。CUDA のバージョンチェックは nvidia-smi。
!python -m pip install bitsandbytes-cuda111
使えるかどうかは python -m bitsandbytes で以下のメッセージが出るか調べる。
PyTorch settings found: CUDA_VERSION=124, Highest Compute Capability: (8, 6). Checking that the library is importable and CUDA is callable... SUCCESS!
使用方法
import bitsandbytes optimizer = bitsandbytes.optim.AdamW8bit(model.parameters(), lr=learning_rate)
Gradient Checkpointing
Training Deep Nets with Sublinear Memory Cost
勾配の計算には各ブロックのフォワードパスの結果を保存しておく必要がある。しかしこれはメモリ使用量が大きい。そこで、チェックポイントに指定したブロックのみフォワードパスの結果を保存しておき、バックプロパゲーション時にフォワードパスの結果が必要になると、一番近いチェックポイントからフォワードパスの結果を再計算する。
メモリ使用量が減るが、学習時間が増加する。
バッチサイズ
大きい場合
利点
- 学習時間の短縮
- 勾配推定の安定性。勾配が均されるため、ノイズが減り学習が安定する
欠点
- 汎化性能の低下。 勾配のノイズが少ないため、局所最適解・sharp minimaに陥りやすい
- メモリ使用量の増加
- 学習率の調整が難しい
小さい場合
利点
- 汎化性能の向上。flat minima に収束しやすく、これは汎化性能の向上に効果があると考えられている
- 局所最適解からの脱却
- メモリ使用量が少ない
欠点
- 学習時間の増加
- 勾配推定が不安定になる
Gradient Accumulation
バッチサイズを小さなミニバッチの集積で近似する。目的のバッチサイズにメモリが足りない場合の選択肢。分散学習時にも使われる。バックプロパゲーションの回数が減るので学習が高速化することもある。
コードはGPUメモリ使用量を削減する を参照。
AMP
16bit でデータを保存するが、精度が必要な部分は 32bit を使う。Tensor コアが使われる。メモリ使用量が減少し、計算が速くなる。
AMP は精度の低下を抑えるために loss をスケールして 16bit の精度の範囲内になるように調整している。なので逆伝播の際にスケールを元に戻す必要がある。
最適化方法は NVIDIA の AMP が遅くなる理由を参照。
分散学習
The Basics of Distributed Training in Deep Learning: Speed, Efficiency, and Scalability
Distributed Deep Learning: Training Method for Large-Scale Model
DeepSpeed Training Overview and Features Overview
データ並列
モデルが各ノードのメモリに収まる場合、まず各モデルでバッチを処理して勾配を計算する。各ノードの勾配を集計して、各ノードのモデルを更新する。この方法だと、バッチの処理の一番遅かったノードに律速される。そこで、各ノードでデータを学習させて後でモデルをマージする方法がある。
モデル並列
LLM のようなモデルが1つのノードに収まらない巨大なモデルは、モデル自体を複数のノードに配置する。
実例
PixArt-α
学習に 28,400 ドル(2025年のドル円レートで、およそ 400 万円)しかかかっていない安価なモデル。学習にかかった時間は 64 台の V100 で 26 日。ちなみに Stable Diffusion 1.5 の学習コストは 320,000 ドル。

出典:PixArt-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis. Junsong Chen et al. Table 4. https://arxiv.org/abs/2310.00426
V100 は 14 TFLOPS、RTX5090 は 105 TFLOPS なので、RTX5090 1台だと学習に 160 日かかる。400 万円で RTX5090 を 10 台買えば 16 日でできる(契約アンペアを 60A 以上にする必要がある)。
オプティマイザーは AdamW。
Stable Diffusion 3
データセットは conceptual-12m と ImageNet。
バッチサイズは 1,024 でオプティマイザーは AdamW、lr = 1e-4 で、1,000 ステップの線形ウォームアップ。
Lumina-Image 2.0
32 台の A100(FP32 は 19.5 TFLOPS) を使用。3段階の訓練でそれぞれ、191, 176, 224 GPU*Days。191 + 176 + 224 = 591GPU*Days、32 台で割ると学習日数は 18.5 日。オプティマイザーは AdamW。

出典:Lumina-Image 2.0: A Unified and Efficient Image Generative Framework. Qi Qin et al. Table 3. https://arxiv.org/abs/2503.21758
HiDream-I1
事前学習
256 x 256 を 600,000 ステップ。24 バッチ/GPU。
512 x 512 を 200,000 ステップ。8 バッチ/GPU。
1,024 x 1,024 を 200,000 ステップ。 2 バッチ/GPU。
AdamW, lr=1e-4, 1,000 ステップの線形ウォームアップ。mixed-precision と gradignt checkpointing を使用。
ファインチューニング
手動でキャプションを付けたハイクオリティな画像で 20,000 ステップ, lr=1e-5, グローバルバッチサイズ 64。
SANA
Pytorch DistributedDataParallel を使用し、64 台の A100 で、かかった時間は非公開。512 x 512 の解像度で 1e-4 の学習率で 200K ステップ以上事前学習を行い、1024 から 4096 へ解像度を増やしながら、2e-5 の学習率で最大 10K ステップの教師ありファインチューニングを行う。オプティマイザーは 8bit CAME。1.6B のモデルで、CAME 8bit は AdamW 8bit よりわずかに性能がよく、メモリ使用量は若干少ない(43GB vs 45GB)。
1/3 のレイヤーだけを使って事前学習させた後、乱数で初期化した残りの 2/3 のレイヤーを追加して学習させる。
DiT-Air
目的関数フローマッチング、オプティマイザーは AdaFactor、1e-4 の固定学習率。ハードウェアは TPU v5p。
- 解像度 256:バッチサイズ 4,096 で500k ステップ
- 解像度 512:バッチサイズ 2,048 で 100k ステップ
- 教師ありファインチューニング(SFT):バッチサイズ 64 で 2.5k ステップ。低解像度トレーニング時と同様の log-SNR タイムステップ分布シフト付き
- reward fine-tuning:バッチサイズ 64 で 4.8k ステップ
Nitro-T
学習期間は 32 AMD Instinct MI300X GPU で1日。
512px を 100k ステップ、1,024px を 20k ステップ。詳細は GitHub を参照。
REPA(DINO v2)はマスクしてないトークンにのみ適用。
データセット。()は使用枚数。
- Segment Anything 1B(10M)
- CC12m(7M)
- DiffusionDB(14M)
- JourneyDB(4M)
AI 生成画像を使いすぎると、画風がカートゥーン化する。JourneyDB は品質がよいので、ファインチューニングには DiffusionDB ではなく JourneyDB を使う。
Qwen-Image
Stage 1 事前学習:256x256 でアスペクト比は 1:1, 2:3, 3:2, 3:4, 4:3, 9:16, 16:9, 1:3, 3:1。
Stage 2 ファインチューニング:以下の画像を除外する。
- EXIF を見て、回転・反転された画像
- ボケた画像
- 露出オーバー・アンダー
- 彩度が高すぎる等、加工しすぎた画像
- 商品写真のような背景が単色の画像
Stage 3 T2I Alignment:スクレイピングした画像を LLM・VLM でキャプションをつける
Stage 4 テキストレンダリング:データセットを、英語・中国語・その他の言語・画像内に文字なし、に分けて偏らないようにする。テキストが小さすぎる画像は除外。以下のような画像でデータを水増し。
- Stage 1:単色にテキストだけ書かれた画像を生成し訓練
- Stage 2:画像にテキストが書かれた紙を配置して訓練
- Stage 3:パワポのスライドを生成できるように、スライドの画像を生成して訓練
Stage 5 高解像度:解像度 640 で訓練。Aesthetic フィルターを使い低品質な画像を除外。QR コードやサインなどがある画像も除外
Stage 6 カテゴリバランスの調整:カテゴリごとにテストして、能力の低い部分を追加学習
Stage 7 高解像度2:640~1,328 解像度で訓練
Z-Image-Turbo
- 314K H800 GPU hours
- 628K ドル
- データセットに AI 生成画像を含んでいない
- Low-res. Pre-Training: 147.5k gpu hours
- Omni-Pre-Training 142.5k gpu hours
- Post-Training 24k gpu hours
データインフラ
正しいステージで正しいデータを取得できるようにするために以下のツールを開発した。データセットは質が重要で多様な概念を含みかつ意味的に重複のないデータが必要だ。
- 多次元特徴抽出のためのデータプロファイリングエンジン
- 画像のメタデータ(解像度・アスペクト比)や明瞭度、画像に何があるかなどで検索できる
- perceptual hash で重複の検出
- カラーシフト・ボケ・ウォーターマーク・圧縮ノイズなどの要素から画像品質をスコア付けするモデルを作成
- 単色背景を検出して自動クロップ
- 美的スコアモデルを作成
- AI 生成画像検出モデルを作成
- 画像を自動タグ付けする VLM を作成。NSFW フィルタもこのモデルで行う
- CN-CLIP でキャプション品質が低いものを学習から除去
- データセットのキャプションは、タグのみ・短いキャプション・詳細なキャプションの3つ
- 意味重複除去と対象取得のためのクロスモーダルベクターエンジン
- k-nearest neighbor 検索関数を使う。8台の H800 で 10 億枚の画像を8時間で処理できる
- 構造的概念組織化のための世界知識トポロジーグラフ。これはデータセット内で不足しているデータを分析できる
- VLM の学習ソースは Wikipedia とそのリンク先。ページランクの低いものは除く
- 学習ソース DB は手動更新可能。ユーザープロンプトから DB に存在しない概念を検出して更新する
- 閉ループ改善のためのアクティブキュレーションエンジン
- モデルがうまく描けない概念の検出
- ループを実行するごとにデータのアノテーション品質が改善される
- うまくキャプション付けできなかった画像は人力で修正し、修正内容を元にキャプション付け VLM を修正
Edit モデルのためのデータ生成
- 既存の Edit モデルが上手くこなせるタスクは既存の Edit モデルを使ってデータを生成する
- 1枚の画像から複数の編集後画像を作成する
- 動画から類似度の高いフレームを抜き出し(CN-CLIP 使用)、それを学習素材にする
- テキスト画像を生成するシステムを作成し、それを使ってテキスト描画を学習させる
キャプショナー
キャプショナーは Chain-of-Thought の要領で徐々に詳細なキャプションを生成する。
t2i の画像をキャプショナーに入れると、順に、タグ・短いキャプション・詳細なキャプションの3つを出力する。短いキャプションはユーザー入力を再現している。
i2i の画像ペアをキャプショナーに入れると、順に、2つの画像それぞれのキャプション・分析(入力された2つの画像の差異を出力)・修正指示の3つを出力する。
VLM には OCR で読み取ったテキスト情報も入れる。
学習戦略
- 低解像度事前学習。2562 の固定解像度で事前学習
- Omni-Pre-Training。可変解像度で t2i・i2i 学習
までは共通。
Z-Image は
- プロンプトエンハンサーを使用した SFT
- 新しい蒸留モデル作成技術
- Decoupled DMD。蒸留プロセスの画質向上と学習安定化との役割を分離
- DMDR。正則化項に distribution matching 項を追加することで蒸留に強化学習を統合
- 強化学習(RLHF)
Z-Image Edit は
- 画像編集のための事前学習
- 画像編集のための SFT
並列学習のために FSDP2 を使い、GPU 間に効率的にオプティマイザステートと勾配とを分配した。モデルのすべてのレイヤーに gradient checkpointing を実装し、メモリ量を削減した。計算量は増えるがバッチサイズを大きくすることでスループットを向上させた。
torch.compile 使用。
aspect ratio bucketing ではなく、画像解像度からシーケンス長を計算し、バッチ内ではシーケンス長が大体同じになるようにした。シーケンス長が大きく異なると短いシーケンスには大きいパディングが必要になり、学習が遅くなる。平均シーケンス長からバッチサイズを動的に制御し、OOM にならないようにしている。
事前学習
解像度 2562 のみの t2i 学習。
全体事前学習
- 可変解像度学習
- t2i・i2i 学習。この i2i は Edit 用の i2i 学習。i2i 学習をしても t2i の性能は劣化しなかった
- 中英キャプション学習・キャプションの詳細度(タグのみ・短・中・長)を変更した学習。i2i では、編集後のみのキャプションと、差分情報のみのキャプションとをランダムに使用
この段階で 1k-1.5k の解像度に対応させる。
教師ありファインチューニング(SFT)
SFT ではサンプルの少ないロングテール概念を忘れる、破滅的忘却が起こりやすい。そこで SFT 段階でクラスバランシングを強制した。世界知識トポロジーグラフと BM25 ベースのモデルとでリアルタイムに学習素材のレア度を計算。特定のアーティストや概念が学習画像に含まれすぎないようにした。
マージチューニング
プロンプト忠実性優先や美的スコア優先など複数のファインチューンモデルを作成し、マージ比率を調整することでベストなモデルを作成した。
蒸留
最初は DMD を使って蒸留モデルを作成したが、周波数成分の高いディティールの消失やカラーシフトが発生した。そこで Decoupled DMD と DMDR とを開発した。
DMD には以下の2つのメカニズムが存在する
- CFG-Augumentation(CA):機能はステップ数削減
- 分布マッチング(DM):機能は正則化
これらを個別に最適化することで DMD の性能を向上させた(Decoupled DMD)。
DMD に強化学習の損失を追加したのが DMDR。分布マッチングの正則化を効かせることで、強化学習の報酬ハッキングを抑制できる。
RLHF
DPO の後に GRPO を行う。
品質基準は以下の3つ
- プロンプト忠実性
- AI フィルタ通過
- 美的品質
プロンプト忠実性は以下の視点から評価する。人間の評価者は満たしていないと思う項目をクリックするだけ。
- 主題
- 属性
- 動作・インタラクション
- 空間位置
- スタイル・ライティング
テキストレンダリングや物体の個数計数タスクは VLM を使った RLVR を使う。
GRPO
評価基準は以下の3つ
- プロンプト忠実性
- フォトリアル
- 美的品質
Edit モデル
ベースモデルを作成した後、Edit モデルは Edit 用の事前学習を行う。Edit 用の事前学習では 5122 の編集タスクを数千ステップだけやり直したあと、10242 で事前学習を続ける。i2i データは作成が高コストなので、t2i データ4に対し、i2i データ1の割合で学習させる。
Edit モデルの教師ありファインチューニング
テキストレンダリングの割合は減らしてある。DTP ソフトを使えば 100% 正確な画像が手に入るし、ユーザーもそのような指示をする割合が低いので。
モデルサイズが限られているので、プロンプトエンハンサー(PE)で性能を底上げすることにした。プロンプトエンハンサーは VLM の推論モデル。プロンプトを PE に入れてプロンプトを水増しして教師ありファインチューニングを行う。
Illustrious: an Open Advanced Illustration Model
| バージョン | ステップ数 | バッチサイズ | データ枚数 | プロンプトスタイル | アノテーション手法 | 解像度 |
|---|---|---|---|---|---|---|
| 0.1 | 781,250 | 192 | 7.5M | タグベース | オリジナルプロンプト + 手動フィルタリング/再構成 | 1,024 |
| 1.0 | 625,000 | 128 | 10M | タグベース | オリジナルプロンプト + 手動フィルタリング/再構成 | 1,536 |
| 1.1 | 93,750 | 512 | 12M | タグベース | マルチレベルキャプション | 1,536 |
| 2.0 | 78,125 | 512 | 20M | タグベース | マルチレベルキャプション | 1,536 |
- タグベース:Danbooru形式などのタグによるプロンプト設計
- マルチレベルキャプション:タグと自然言語キャプションを併用した注釈方式
- 手動フィルタリング/再構成:クリーンデータの選別やタグ整備の工程を含む
Danbooru 画像とタグは以下の問題がある
- 同一トークンに複数の意味が重なることが多く、曖昧性や誤解の原因になる
- 例:「doctor」というタグは職業名としてもキャラクター名としても使われる
- 画像にタグが極端に少ないものが存在する
- 極端に高解像度な画像がある
- 極端なアスペクト比の画像がある
- コミック形式の画像がある
キャプション構造
NovelAI のようなタグオーダーを採用している。
人数 ||| キャラ名 ||| レーティング ||| 一般タグ ||| アーティスト名 ||| パーセンタイルベースのレーティング ||| 年代
最初はパーセンタイルベースではなく、スコアレンジベースのレーティングだった。しかしスコアレンジは年代やカテゴリでばらつきが大きかったので、以下のようなパーセンタイルベースのレーティングを採用することにした。
| レーティングタグ | パーセンテージ |
|---|---|
| worst quality | ~8% |
| bad quality | ~20% |
| average quality | ~60% |
| good quality | ~82% |
| best quality | ~92% |
| masterpiece | ~100% |
解像度
v2.0 では 0.15MP(500px * 300px)から 2.25MiP(1536 px * 1536px / (1024*1024) = 2.25)。
訓練方法
- No Dropout Token。性的(provocative)なトークンを含む NSFW トークンはドロップアウトしない。加えて NSFW トークンを CFG で制御(つまりネガティブプロンプトに NFSW トークンを入れる)することで 100% 性的なコンテンツを生成しないモデルを作成できた。
- コサインアニーリング
- 疑似レジスタートークン。データ数が少なかったりモデルが理解できない概念を吸わせるトークンを入れる。シーケンス長を調整するためのパディングトークンがレジスタートークンとして機能してしまうことがあるので注意が必要。
- キャラ名とアーティスト名をドロップアウトしない Contrastive Learning(ラベルなしで学習させる手法)。キャラの特徴とアーティストのスタイルを効率よく学習できる。ただし、アーティストとキャラとの結びつきが強くなる欠点がある。
- キャプションの言い換え。"1girl" を "one girl", "single woman" に一定確率で入れ替える。
- マルチレベルドロップアウト。No Dropout Token 以外のトークンは以下ドロップアウトのどれかが確率的に適用される。
- 30%: max(0.3 * total tokens, 10)
- 20%: max(0.4 * total tokens, 15)
- 10%: min(total tokens, 6)
- 4%: min(total tokens, 4)
- 36%: ドロップアウトなし?(論文に記載なし)
- Input Perturbation Noise Augmentation(0 < ε < 0.1)(Ning et al. [2023])
- Debiased Estimation Loss(Yu et al. [2024])
訓練設定
| バージョン | データ枚数 | バッチサイズ | 学習率 | テキストエンコーダー学習率 | エポック | 解像度 | プロンプトスタイル | ドロップアウト | レジスタトークン | マルチキャプション |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.1 | 7.5M | 192 | 4.5e-6 | 20 | 1,024 | タグ | ✖ | ✖ | ✖ | |
| 1.0 | 10M | 128 | 1e-5 | 6e-6 | 8 | 1,536 | タグ | 〇 | 〇 | ✖ |
| 1.1 | 12M | 512 | 3e-5 | 4e-6 | 4 | 1,536 | タグ+ | 〇 | 〇 | ✖ |
| 2.0 | 20M | 512 | 4e-5 | 3e-6 | 2 | 1,536 | タグ+ | 〇 | 〇 | 〇 |
v0.1 が 150M ステップなので、1 step/s だとしても 1,736 日かかる。16 GPU で 109 日。少なくとも 10step/s ぐらいの速度が出ないと厳しい。
ファインチューニングの問題点
ユーザーの評価をフィードバックさせたファインチューニングは生成される画像の多様性がなくなる。流行の画風が高く評価され、AI が上手く書けない手や背景などを描かなくなる。
Illustrious がファインチューニング前のモデルを公開しているのはこれが理由だ。ファインチューニング版を LoRA 形式で配布する方法も考えられる。
性能検証
論文で使われるベンチは基本的にプロンプトと生成された画像との忠実性を計測する。以下の要素があっても減点されることはない。
- 指の本数を間違える
- 細部が溶けている
- 画質が悪い
- 直線がゆがんでいる
- 文字がおかしい
- オブジェクトの細部がおかしい
- 水平線がずれている
評価指標
FID や IS はよく使われるが、人間の評価との相関はあまりない。
- Fréchet Inception Distance (FID): 実画像と生成画像の分布類似性を測定
- Inception Score (IS): 生成画像の品質と多様性を評価
- Precision/Recall: 品質(precision)とカバレッジ(recall)を分離評価
- CLIP Score: 画像テキスト整合性を評価
- Aesthetic Score: 美的品質を評価
- Human Preference Score: 人間の嗜好を反映
ベンチ
- GenEval
- GenEval2
- DPG-Bench(ELLA)
- ImageReward
- VisionReward:ImageReward の動画版
- T2I-CompBench
- T2I-CompBench++
- T2I-CoreBench
高速化
DataLoader
persistent_workders
Windows 環境ではエポックの開始のプロセスの生成と破棄とに時間がかかる。persistent_workers を True に設定するとこれを短縮できる。
train_loader = torch.utils.data.DataLoader(
...
persistent_workers=(os.name == 'nt'),
)BatchSampler
DataLoader のデフォルトで設定される BatchSampler はバッチサイズが巨大な場合は遅い。バッチサンプラーを自作する場合は自分でバッチサンプラーをつくる (PyTorch)や PytorchのDataloaderとSamplerの使い方を参照。
学習高速化
torch.compile
GLU Variants Improve Transformer
FFN の代わりに SwiGLU を使うと表現力の向上、収束の高速化(学習の高速化)、大規模モデルでの性能向上が見られる。
REPA Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
pretrained visual encoder の出力を正則化項に追加することで、高速化と生成品質の向上を実現。学習速度が最大 17.5 倍向上する。
DINO v2 がよく使われる。
出典:Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think. Sihyun Yu et al. Figure 1. https://arxiv.org/abs/2410.06940
記号
- $f$:エンコーダー(VAE)
- $\mathbf{x}_*$:ノイズなし画像
- $\mathbf{y}_* = f(\mathbf{x}_*) \in \mathbb{R}^{N \times D}$:エンコーダー(DINOv2 など)の潜在表現
- $\mathbf{h}_t = f_\theta(\mathbf{z}_t)$:拡散トランスフォーマーのエンコーダー出力
- $h_\phi (\mathbf{h}_t) \in \mathbb{R}^{N \times D}$:MLP
Learning Diffusion Models with Flexible Representation Guidance
REPA の発展形の REED は、REPA の4倍速く学習できる。
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
パラメータを共有することで、性能低下を抑えてパラメータ数を削減。
Patch Diffusion: Faster and More Data-Efficient Training of Diffusion Models
パッチ単位で評価すると同時に、パッチサイズを変更することで2倍以上の学習速度を達成。この手法の一番の利点は、学習画像の枚数が最低 5,000 枚から学習できること。
ただし、切り出した画像とキャプションとを一致させるのが面倒。
FlashAttention
FlashAttension の解説はFlashAttention by handが詳しい。
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
アテンションブロックの行列演算の最適化。
Lightning Attention-1: TransNormerLLM: A Faster and Better Large Language Model with Improved TransNormer
アテンションのスケールと softmax をなくして、アテンションを O = Norm(Q(KTV)) に置き換える。
Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models
HBM のあるハードウェアが対象。Linear Attention は cumulative summation(cumsum) のせいで性能の理論値が出せない。Lightning Attention-2 では LLaMA で理論値が出せることを実証した。
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
分散環境でデータの冗長性を減らす技術。
PixArt-Σ
PVT v2 に似た key/value の圧縮によって高速化する。
Transformers without Normalization
Normalization Layer を ${\mathrm{DyT}(\mathbf{x}) = \gamma \times \mathrm{tanh}(\alpha \mathbf{x}) + \beta}$ で置き換えると計算が速くなる。性能は-1~1ポイント上下する。レイヤー単体では 40~50% 高速になり、モデル全体では8%程度高速になる。ただし torch.compile した場合両者に速度差はない。
# x の次元は [B, T, C]
# B: バッチサイズ, T: トークン数, C: 隠れ層の次元
class DyT(nn.Module):
def __init__(self, channels: int, init_alpha: float=1.0):
"""
tanh を使った Normalization。精度を維持して Normalization を高速化
Args:
channels (int): 隠れ層の次元
init_alpha (float): x にかかる係数
"""
super().__init__()
self.alpha = nn.Parameter(torch.tensor([init_alpha]))
self.beta = nn.Parameter(torch.zeros(channels))
self.gamma = nn.Parameter(torch.ones(channels))
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.gamma * torch.tanh(self.alpha * x) + self.beta
Data Efficacy for Language Model Training
データセットをスコアリングし厳選することで、データ量を半減させても同じ性能を出す手法の解説。
Implicit Reward as the Bridge: A Unified View of SFT and DPO Connections
LLM のケースだが、SFT と DPO が暗黙的報酬学習の一種であることを数学的に証明し、SFT の学習率を下げることで性能を向上させられることを実証した。
Compositional Discrete Latent Code for High Fidelity, Productive Diffusion Models
画像を Discrete Latent Code に変換してモデルに入力して学習させることで学習を高速化する。T2I で生成するために、T2DLC のネットワークを追加で学習する必要がある。
Where to find Grokking in LLM Pretraining? Monitor Memorization-to-Generalization without Test
MoE のパスウェイ複雑度を計測することでグロッキングの発生を予測できる。
Bidirectional Sparse Attention for Faster Video Diffusion Training
QK のスパース性を利用して動画生成モデルの学習速度を高速化する。
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
ウェイトが等方性ガウシアン分布になるように正則化(SIGReg)をかけることで、少ない学習データ・比較的小さいモデルでも安定した学習を可能にした。
loss に SIGReg を使った JEPA 予測ロスを使うことで、簡単に(50行程度)既存モデルの学習に統合できる。
推論高速化
xFormers
torch 2.2 から torch.nn.functional.scaled_dot_product_attention で FlashAttention-2 が利用できるので、xFormers を入れることはなくなってきている。
Flash-Attention 2, 1 の実装。推論だけではなく学習時にも使える。性能を落とさずに高速化とメモリ使用量の削減とが可能。他の推論高速化はたいてい性能が劣化する。
SLA: Beyond Sparsity in Diffusion Transformers via Fine-Tunable Sparse-Linear Attention
Attention ブロックを critical, marginal, negligible の3種類に分け、以下のように計算する。
- critical - FlashAttention
- marginal - LinearAttention
- negligible - スキップ
行列変換後にファインチューニングが必要。
LSSGen: Leveraging Latent Space Scaling in Flow and Diffusion for Efficient Text to Image Generation
タイムステップの小さいうちは低い解像度でデノイズをし、徐々に解像度を増やしていく。
Faster Diffusion: Rethinking the Role of the Encoder for Diffusion Model Inference
U-Net のエンコーダーをキャッシュすることで高速化する。
Delta-DiT: A Training-Free Acceleration Method Tailored for Diffusion Transformers
デノイズの初期段階では DiT ブロックの後方をキャッシュし、後半では前方をキャッシュする事で高速化する。これは DiT ブロックが画像の概形(前方のブロック)と詳細(後方のブロック)を生成する役割の違いに基づいている。
Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation
トークンごとに FFN の通過回数を動的に変更する。MoE は横展開だが、MoR は縦展開。
Teaching Pretrained Language Models to Think Deeper with Retrofitted Recurrence
既存の LLM を MoR に改造して再訓練することで、ゼロから MoR モデルを作成するより効率的に学習できる。
Upsample What Matters: Region-Adaptive Latent Sampling for Accelerated Diffusion Transformers
エッジのある部分をアップサンプルして再デノイズする。重要な部分を切り出して i2i するテクニックをモデルレベルで行う手法。
HORDS: Diffusion Sampling Accelerator with Multi-core Hierarchical ODE Solvers
Gated Delta Networks: Improving Mamba2 with Delta Rule
LLM 用の技術で Linear Attention の改良版。
Cache
拡散モデルのキャッシュ手法のまとめは A Survey on Cache Methods in Diffusion Models: Toward Efficient Multi-Modal Generation を参照。
以下の手法がある。
- タイムステップをスキップ
- 特定のブロックをスキップ
- 特定のトークンをスキップ
- 情報密度の低い箇所をスキップ
DeepCache: Accelerating Diffusion Models for Free
U-Net のアップサンプル層をキャッシュする。
Delta-DiT: A Training-Free Acceleration Method Tailored for Diffusion Transformers
トランスフォーマーブロックの前半は輪郭や構図、後半はテクスチャなどのディティールを担当している。なので、タイムステップ前半は後半のブロックをキャッシュし、タイムステップの後半は前半のブロックをキャッシュすることで推論を高速化する。
Accelerating Diffusion Transformers with Token-wise Feature Caching
ToCa。トークンごとにキャッシュの反応感度が異なることを発見し、トークン単位でキャッシュを分析する手法を解説している。
Timestep Embedding Tells: It's Time to Cache for Video Diffusion Model
TeaCache。一定間隔でキャッシュを破棄するのではなく、キャッシュがしきい値を超えるまでキャッシュを使い続ける。しきい値は累計デノイズ量が使われる。
ハイパーパラメータの調整が面倒で、画質もそこそこ劣化する。
MagCache: Fast Video Generation with Magnitude-Aware Cache
モデルの出力と入力との差を出力残差(residual output)と呼び、現在のタイムステップの出力と前回のタイムステップの出力との比を出力比(magnitude ratio)と呼ぶとする。
拡散モデルの動画生成の出力残差と出力比とは以下の特性がある。
- デノイズが進むに対応して安定して出力比が減少する
- プロセスが 80% を超えたあたりから出力比が急減する
- タイムステップ間のトークンごとのコサイン距離が小さい
- 初期ステージでは出力比の標準偏差はゼロに近い
キャッシュ破棄の閾値はモデルの出力の累計デノイズ量の比の累計。
EasyCache Less is Enough: Training-Free Video Diffusion Acceleration via Runtime-Adaptive Caching
蓄積したエラー E を以下の式で表現し、E がしきい値を超えたらキャッシュを破棄する。
\[ \begin{split} k_i &= \dfrac{||\mathbf{v}_i - \mathbf{v}_{i-1}||}{||\mathbf{x}_i - \mathbf{x}_{i-1}||} \\ E_t &= \sum_{n=i+1}^{t} \dfrac{k_i||\mathbf{x}_n - \mathbf{x}_{n-1}||}{||\mathbf{v}_{n-1}||} \end{split} \]OmniCache: A Trajectory-Oriented Global Perspective on Training-Free Cache Reuse for Diffusion Transformer Models
現在のキャッシュ戦略は、モデル出力の類似度が高いサンプリングプロセスの後半に集中している。しかしキャッシュ再利用の判断材料としてモデル出力の類似度を使うのは最適ではない。
サンプリングプロセスの前半でキャッシュ使用によるエラーが発生しても、後半でリカバーできる。しかしサンプリングプロセス後半でキャッシュ使用によるエラーが発生した場合、それを回復するのは困難だ。モデル出力の類似度でキャッシュの使用を判断すると、エラーの回復の困難なサンプリングプロセス後半でキャッシュを使用してしまう。
OmniCache ではモデル出力を PCA で3次元にした後、曲率の小さい部分でキャッシュを使用する。
FlexCache: Flexible Approximate Cache System for Video Diffusion
動画生成サービス提供業者向けのキャッシュ手法。プロンプトに対する潜在空間画像をデータベースに保存しておく。似たプロンプトが入力されると、完全のノイズから生成するのではなく、キャッシュしておいた潜在空間を利用してデノイズの初期段階をスキップする。
潜在空間画像は圧縮する。
H2-Cache
デノイズの前半と後半とでしきい値を変える。
量子化と枝刈り
Transformers ライブラリは量子化のモデルロード・学習に対応している。
SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration
FlashAttention-2 を INT 8 bit 量子化する。FlashAttention3 や xformer より高速。Softmax の精度は FP32。
Attention の行列の量子化には以下の課題があった
- 行列 K はチャンネル単位(channel-wise)の外れ値がある
- 行列 P, V を単純に INT8 に量子化すると精度がばらつく
SageAttention では以下のようにこれらの課題を解決した。
- K にスムージングを適用する
- P, V は INT8 で量子化し、その行列積の計算は FP16 を使う
K の外れ値にはパターンがあり、バイアスが大きいだけで分散は小さい。なので、以下のように K をスムージングすれば INT 8 に量子化しても精度を維持できる。
\[ \begin{split} \gamma(K) &= K - \mathrm{mean}(K)\\ \mathrm{mean}(K) &= \frac{1}{N}\sum^N_{t=1}K[t,:] \end{split} \]この変換でアテンションスコア P は変化しない。
\[ \sigma(q(K - \mathrm{mean}(K)^\top)) = \sigma(qK^\top - q\cdot \mathrm{mean}(K)) = \sigma(qK^\top) \]$\tilde{P}$ はブロック単位の量子化、V はチャンネル単位の量子化を適用する。理由は以下の通り。
- $\tilde{P}$ にチャンネル単位の量子化と V にブロック単位の量子化とを適用するのは不可能。逆量子化は outer axis のスケールファクターが必要なので
- $\tilde{P} = \mathrm{exp}(S_i - \mathrm{rowmax}(S_i)), S_i$ は$QK^\top$ ブロックの行列積の結果なのでそれぞれの行の最大値の $\tilde{P}$ は1。よって $\tilde{P}$ ブロックに s= 1/127 を適用すれば精度はトークンごとの量子化と同じ
- チャンネルごとの量子化は V のチャンネルごとの外れ値に対処可能
SageAttention2: Efficient Attention with Thorough Outlier Smoothing and Per-thread INT4 Quantization
QK を INT4、$\tilde{P}, V$ を FP8 で計算する。K だけでなく Q にもスムージングを適用する。
SageAttention2++: A More Efficient Implementation of SageAttention2
PV の計算に、mma.f32.f8.f8.f32 ではなく、mma.f16.f8.f8.f16 を使用して最大4倍(SageAttention2 比)高速化したバージョン。
SageAttention3: Microscaling FP4 Attention for Inference and An Exploration of 8-Bit Training
Blackwell で導入された FP4 Tensor Core を使う。
INT8 精度の学習方法も解説されている。
Joint Pruning, Quantization and Distillation for Efficient Inference of Transformers
訓練済みモデルから重要度の低い重みやフィルターを削減する枝刈りの解説。
SANA 1.5: Efficient Scaling of Training-Time and Inference-Time Compute in Linear Diffusion Transformer
- 16K 以上のパラメータの Linear と 1x1 畳み込みを8bit 整数で量子化
SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
ウェイトには外れ値がある。この外れ値が量子化の精度を低下させる。そこで、行列を外れ値の部分 W と量子化しやすい部分 X とに分け、元の行列を W + X で表現する。量子化しやすい X は4bit 量子化、外れ値の部分は SVD で分解、16bit の精度で LoRA(rank=32)化する。
SDXL, PixArt, FLUX.1 で動作検証をしている。
LittleBit: Ultra Low-Bit Quantization via Latent Factorization
SVDQuant と同様に、行列を LoRA のように分解してから量子化することで、最大 0.1 BPWを達成している。
Jet-Nemotron: Efficient Language Model with Post Neural Architecture Search
LLM のケースだが、精度が必要なブロックのみをフルアテンション、残りをリニアアテンションにすることで高速化する。MLP の部分は変更しない。JetBlock は入力シーケンスに応じて動的に畳み込みカーネルを生成する。
1 bit is all we need: binary normalized neural networks
バイナリ正規化レイヤーを使用して 1bit の学習をすることで、1 bit 量子化推論を可能にした。
SINQ: SINKHORN-NORMALIZED QUANTIZATION FOR CALIBRATION-FREE LOW-PRECISION LLM WEIGHTS
行単位のスケールだけでなく、列単位のスケールも使うことで、perplexity に対するファイルサイズを最適化した。
通常はバイアス+スケールで量子化するが、SINQ はバイアスは使わず、行単位のスケール+列単位のスケールで量子化する。
GGUF
llama.cpp で実装されている量子化方法。Georgi Gerganov氏(GGMLライブラリの作者)によって、オープンソースプロジェクトとして進化してきたファイルフォーマット。
- レガシー量子化
- Qx_0 や Qx_1 のような形式で表示
- 各レイヤーの重みを、ブロック(通常256個の重み)に分割し、それぞれのブロックに対して異なるスケール係数を適用して量子化
- _0 はバイアスなし、_1 はバイアスあり
- 基本的には、重み = スケール × 量子化された値 または 重み = 最小値 + スケール × 量子化された値 の形式で、各ブロックの重みが低ビット(例: 4ビット)の整数に変換される
- K 量子化
- Qx_K_S, Qx_K_M, Qx_K_L のような形式で表示
- llama.cppのPR #1684 で導入された
- レガシー量子化よりもビット割り当ての性能が上がっている
- ブロックごとの定数も量子化されるなど、より効率的なビット割り当てと精度維持とを目指している
- I 量子化
- IQ2_XXS, IQ3_S などの形式で表示
- PR #4773 で導入された
- QuIP# (Quantization with Incoherence and Preconditioning) 使用
K 量子化
ブロック単位のベクトル量子化
例えば、基本的に 32要素/ブロック(=128bit)のfloat重みを含むブロックを対象に、以下の手順で量子化する
- ブロックごとに min/max または scale/zero_point を求める
- 各値を k-bit 整数にスケーリングして量子化
- 推論時にはブロック単位で復元(dequant)
typedef struct {
uint8_t qs[16]; // 量子化データ
float d; // scale(1ブロックごと)
float m; // offset(optional)
} block_q4_K;
実装例:K量子化された行列との乗算
ggml_vec_dot_q4_K のような関数で、量子化行列との内積計算を行う。K-Quant は以下のように量子化されたまま計算するのではなく、「復元しながら計算する」
- 一定のブロック数を並列SIMD演算でデコード
- デコード時に量子化されたint4をfloatに復元(scaleとoffsetを適用)
- ブロック内で再構成された値との内積を行う
S, M, L の違い
| 名前 | スケール係数の数 | 残差保証 |
|---|---|---|
| S | 1/block | なし |
| M | 2/block(または小分割) | あり(部分保証) |
| L | 多数/block | あり(高精度) |
M
- ブロック内を 2つのサブブロック(16要素 + 16要素)に分割
- 各サブブロックに 別々の scale 値を持たせる(dual scale)
- 一部の実装では補正ベクトル(微調整量)を使って残差補正を適用
L
- ブロック内を 複数のサブブロック(例:8要素×4)に分割
- 各サブブロックに異なるスケール
- 非線形な正規化(L2正規化やGroupNormに近い)を適用可能
- 残差補正量を別途保存し、復元時に補完
- 高速化最適化が難しくなるが、推論精度は非常に高い。Q6_K と同性能を Q4_K_L で達成することもある
そのほか
Understanding Transformer from the Perspective of Associative Memory。活性化関数には速度と記憶容量とのトレードオフが存在する。ReLU は高速だがパラメータあたりの記憶量は小さくなる。Softmax は遅いがパラメータあたりの記憶容量が多くなる。
Accelerate High-Quality Diffusion Models with Inner Loop Feedback
A Simple Early Exiting Framework for Accelerated Sampling in Diffusion Models
サンプラー
PFDiff: Training-Free Acceleration of Diffusion Models Combining Past and Future Scores
ワーキングメモリー
Recurrent Memory Transformer
Transformer model with external token memories and attention for PersonaChat
- モデル外部に配置したトークンメモリと専用のアテンション機構を導入
- ユーザー定義のトークンをメモリとして保存・参照し、従来以上に柔軟な情報蓄積と再利用を実現
Memory Transformer
- 非ローカル表現を保持するためのメモリトークンを入力に追加し、セルフアテンションで参照
- 長距離依存性を扱う際の性能を改善
Fine-tuning Image Transformers using Learnable Memory
- 画像パッチ入力の各 Transformer レイヤーに「学習可能メモリトークン」を付加
- 下流タスク(画像分類など)適応時に少数のメモリトークンのみを微調整し、性能向上とパラメータ効率化を両立
教師ありファインチューニング
Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack は SFT で拡散モデルの性能を向上させた初期の論文。PixArt-α 以降のモデルは SFT を行うのが一般化している。
On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification
LLM で、目的関数をトークンの確率に従って動的にスケーリングすることで勾配を更新を安定化させる手法。強化学習よりも低コストに強化学習を上回る性能が出せる。
従来の SFT が RL に性能で劣っていた原因は、RL の importance sampling の $1/\pi_\theta$ が SFT にかけていたことだった。$\pi_\theta$ が必要なので、モデルは事前学習させておく必要がある。
Diffusion-Sharpening: Fine-tuning Diffusion Models with Denoising Trajectory Sharpening
従来の SFT シングルタイムステップの最適化だったが、Diffusion-Sharpening は複数ステップにまたがる sampling trajectory を最適化する。
そのほか
- Specialist Diffusion: Plug-and-Play Sample-Efficient Fine-Tuning of Text-to-Image Diffusion Models to Learn Any Unseen Style
- DomainStudio: Fine-Tuning Diffusion Models for Domain-Driven Image Generation using Limited Data
強化学習
画像生成 AI の強化学習はうまく描けるものをよく描くようにし、うまく描けないものを描かないようにすることで画質を向上させる。なのでベースモデルが全く描けないようなものは、強化学習ではどうしようもない。
- 強化学習一般については Reinforcement Learning: An Overview を参照
- ビジョンモデル(含む拡散モデル)における強化学習のまとめは Reinforcement Learning in Vision: A Survey を参照
- 推論モデルの強化学習は A Survey of Reinforcement Learning for Large Reasoning Models を参照
- LLM の強化学習の最適解(2025/10 現在)については The Art of Scaling Reinforcement Learning Compute for LLMs
- 拡散モデルの強化学習の論文リストは Awesome Alignment of Diffusion Models を参照
出典:Reinforcement Learning in Vision: A Survey. Weijia Wu et al. Figure 2. https://www.alphaxiv.org/abs/2508.08189
強化項目
- GenEval 等のモデルを使用して計測するプロンプト忠実性
- 美的スコア
- AI フィルター通過
- OCR・VLM モデルを使用して計測するテキストレンダリングの正確さ
- 写真かイラストかを見分けるモデルを使用したフォトリアルさ
SFT vs RL
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training によると、暗記を強化する場合は SFT、データセット外の汎用性を強化したいなら RL を使う方が良い。
RLHF Reinforcement Learning from Human/AI Feedback
- 特定のプロンプトに対する画像のペア比較(例:「画像Aの方が画像Bより優れている」)といった人間の好みに関するデータを収集
- この選好データに基づいて、人間のフィードバックと一致するスコアを予測する独立した報酬モデル(RM)を訓練する
- この訓練されたRMが報酬関数として使用され、通常は PPO のようなポリシー勾配法を用いて、生成モデル(「ポリシー」)を報酬信号を最大化するようにファインチューニングする
PPO Proximal Policy Optimization
PPOは、大きなポリシー更新による不安定性を解決するために、クリッピング(clipping)と呼ばれる特殊な目的関数を使用するポリシー勾配アルゴリズム。そのシンプルさと安定性により、特に複雑で高次元な空間での RL における主要なアルゴリズムになった。
DDPO Denoising Diffusion Policy Optimization
通常 PPO は生成された画像に対して行われるが、DDPO はノイズ除去プロセスにたいして PPO を適用する。DDPO の多段階 MDP 定式化は、より効果的で安定した学習を可能にした。DDPO は Proximal Policy Optimization (PPO) を利用して、テキストプロンプトだけでは表現が難しいさまざまな下流タスクの目標に合わせてファインチューンできる。
美的品質とプロンプト・画像の整合性とを調整可能。
OneReward: Unified Mask-Guided Image Generation via Multi-Task Human Preference Learning
報酬モデルに VLM を使う手法。学習1回ごとに VAE デコードが入るので学習は遅い。VLM のファインチューンは必ずしも必要ではないが、報酬を直接適用するわけではないので、ここに分類した。
FlowRL: Matching Reward Distributions for LLM Reasoning
PPO や GRPO は報酬シグナルが乱高下するので過剰最適化になりやすい。Distribution-matching を行ったモデルを使って報酬を調整することで、GRPO を 10% 上回るモデルを作成した。
Self-Distillation Enables Continual Learning
SDFT は LLM で自己蒸留により破滅的忘却を防ぎかつ、性能を向上させる手法。
SFT は学習させるテキストの次を予測させる。これは事前のテキストにエラーが含まれていないので実際の推論とは異なる。実際の推論はエラーが蓄積し出力が長くなるほど回答は劣化する。
SDFT は実際の推論時同様データと、教師用学習データと両方を使う。教師用データを使った推論を Q、実際の推論時同様データを使った推論を P として以下の損失を計算する:
\[ \mathbb{E}_{y\sim P} \left[ \mathrm{log} \dfrac{P}{Q} \right] \]画像生成用 AI でも同様の方法で学習できる。
報酬モデル不要な選好最適化手法
DPO や GROP は分母に $\pi_{ref}(y_w|x)$ が出てくるが、これは問題にならない。
- LLM の場合は出力に softmax がかかっているので、LLM の出力は0にならない
- 大抵は log を使っているので $log(\frac{\pi_{\theta}(y_w|x)}{\pi_{ref}(y_w|x)}) = log(\pi_{\theta}(y_w|x)) - log(\pi_{ref}(y_w|x)) $ となり、log(0) = 1 なので
ただしアンダーフローを起こしたり、出力をマスクすると0になることがある。対処が必要な場合は $\pi$ に $\epsilon$ を足すか、下限クリップを行う。
DPO Direct Preference Optimization
RLHF は報酬モデルを作成する必要があったが、DPO では不要。DPO は選好学習の問題を教師あり学習の目的として再構築し、ペアごとの選好データに基づいて生成モデルのポリシーを直接最適化する。
Diffusion-DPO Diffusion Model Alignment Using Direct Preference Optimization
DPO を拡散モデルに適用した論文。SDXL で検証している。SD3 もこの手法で DPO を実施している。
D3PO Direct Preference for Denoising Diffusion Policy Optimization
DPO を拡散モデルに適用するには大量の VRAM を必要とする。ノイズ除去プロセスでは、複数の大きな潜在表現にわたる勾配を保存する必要があり、これは LLM での単語埋め込みの処理よりもはるかに重いメモリ負荷になる。D3POはこの課題に対処するため、ノイズ除去プロセスの各ステップで直接パラメータを更新できるようにし、勾配の履歴全体を保存する必要性を回避した。
PPOD Proximal Preference Optimization for Diffusion Models
PPOD は PPO の「近接更新の原則(クリッピング)」を取り入れて訓練の安定性を向上。
人間のフィードバックを利用するよりも費用対効果が高い Reinforcement Learning from AI Feedback (RLAIF) のために設計されている。PPODは、ImageReward のような学習済みの報酬モデルを AI 評価器として使用し、ファインチューニングのためのペアごとの選好データを生成する。
GRPO Group Relative Policy Optimization
GRPO の日本語の解説としては、LLMチューニングのための強化学習:GRPO(Group Relative Policy Optimization) が詳しい。
Flow-GRPO: Training Flow Matching Models via Online RL はフローモデル+SDE で GRPO を実行できるようにした。
GRPO を視覚ドメインへの適用した論文に DanceGRPO: Unleashing GRPO on Visual Generation がある。DDPOのような手法で問題となる、動画生成における訓練の不安定性や報酬ハッキングに対処するための独自のメカニズムを導入している。
後続の MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE では、スライディングウィンドウメカニズムを使用し、ノイズ除去ステップの一部のみを最適化することで、訓練時間を50%近く短縮する。
Pref-GRPO: Pairwise Preference Reward-based GRPO for Stable Text-to-Image Reinforcement Learning
従来の GRPO はスコアの差が小さいと Reward Hacking が発生する。なぜならスコア差が小さい場合、スコアを正規化する際に差が実際以上にスケールされてしまうからだ。
そこでスコア差ではなく、勝率によって報酬を決定する Pairwise Preference Reward-based GRPO によって Reward Hacking を抑制し、安定した学習に成功した。
AWM Advantage Weighted Matching: Aligning RL with Pretraining in Diffusion Models
DDPO の遅い収束問題を解消、加えて学習方法も簡略化した。
DiverseGRPO: Mitigating Mode Collapse in Image Generation via Diversity-Aware GRPO
セマンティックの異なるサンプルにボーナスを追加して、多様性を確保する。
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
複数の報酬関数を使う場合に性能を上げる方法。
通常はサンプルに複数の報酬関数を適用し reward を計算、その後で正規化する。GDPO は報酬関数ごとに reward を正規化し、それらを合算したあとさらに正規化する。これによって advantage の劣化を防ぐことができる。
出典:GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization. Shih-Yang Liu et al. Figure 2
画像の品質評価モデル
そのほかの文献
TEMPFLOW-GRPO: WHEN TIMING MATTERS FOR GRPO IN FLOW MODELS
Neon: Negative Extrapolation From Self-Training Improves Image Generation
AI 生成画像は ODE ソルバーの精度の問題で必ず劣化する。その劣化した生成画像を逆方向に学習することで、学習データなしで性能を向上させる手法。
GSPO Group Sequence Policy Optimization
日本語の解説はLLMチューニングのための強化学習②:GSPO(Group Sequence Policy Optimization)を参照。
トークンレベルで評価する GRPO は MoE アーキテクチャで実行すると分散が大きくなり学習が不安定になる。MoE の LLM のためにデザインされた GSPO はトークンレベルではなくシーケンスレベルで評価する。
Qwen3 や InternVL3.5 でも使われている。
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
オンラインとオフラインの2つの強化学習で訓練する。ビジュアルトークンの解像度を自動最適化するルーターを導入して推論速度を向上させた。
RLVR Reinforcement Learning with Verifiable Rewards
RLVR は別に訓練されたモデルどころか人間の選好データすら不要。ただし客観的にルールで記述・判定できるものに限定される。
曖昧で主観的な人間の選好に依存する RLHF とは対照的に、RLVR はモデルの出力が客観的に正しいかどうかに基づいて報酬を与える訓練手法。RLVR の報酬信号は、多くの場合、単純なルールベースの関数であり、正しい場合は1、間違っている場合は0というバイナリの報酬を提供する。
RLVR の拡散モデルへの応用としては、特定の数のオブジェクト(「3匹の猫の写真」)を正確に描写したり、厳密な構図のルールに従わせたり、タグの要素をすべて含んでいるかを判定したりすることが考えられる。
RLHF と RLVR の対比は、単なる技術的な違いではなく、生成AIの2つの主要な目標を反映する概念的な区別だ。RLHF は、美学や気分といった主観的でニュアンスのある人間の価値観を捉えることに優れており、これらはコードで簡単に定量化できない。一方 RLVR は、カウントや論理的推論といった客観的で検証可能な正しさを強制することに優れている。
Self-Play Fine-Tuning of Diffusion Models for Text-to-Image Generation
データセット不要な自己対戦型ファインチューニング手法。拡散モデルが自身の以前のバージョンと競争することで反復的に自己改良する。1回目の反復から SFT を上回り、2回目で Diffusion-DPO を凌駕する。
Compute as Teacher: Turning Inference Compute Into Reference-Free Supervision
CaT も人間の選好データすら不要。CaT は、複数出力を合成し、元の出力を上回るものを作成することでそれを自己学習してくフレームワーク。
そのほかの文献
- The Delta Learning Hypothesis。品質差のあるモデルの出力を DPO を利用して学習させることで、性能が向上できる可能性がある。
- DAPO: An Open-Source LLM Reinforcement Learning System at Scale。LLM で GRPO で正則化項を外し・クリップを上げて性能向上した例
- 完全動的強化学習システム:RLAnything: Forge Environment, Policy, and Reward Model in Completely Dynamic RL System
丸暗記の仕組み
Generalization of Diffusion Models Arises with a Balanced Representation Space
モデルがデータを丸暗記した場合、モデルのウェイトに大きい標準偏差と局所的なスパイクとが見られる。丸暗記したウェイトは画風の変換などの介入操作が難しくなるので、その方向でも検出可能。
未分類
Data-Driven Loss Functions for Inference-Time Optimization in Text-to-Image Generation
追加の Classifier ネットワークを訓練することで空間位置のエラーを修正する。
- USO: Unified Style and Subject-Driven Generation via Disentangled and Reward Learning スタイル転送モデル。CLIP と DiT の間に Projector モデルを追加し、Projector モデルを訓練する
参考文献
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
CogView3: Finer and Faster Text-to-Image Generation via Relay Diffusion
Playground v3: Improving Text-to-Image Alignment with Deep-Fusion Large Language Models
SiT: Exploring Flow and Diffusion-based Generative Models with Scalable Interpolant Transformers
DualFast: Dual-Speedup Framework for Fast Sampling of Diffusion Models。離散化誤差と近似誤差という2つのサンプリング誤差を同時に考慮することで、DPMのサンプリング速度を向上。
Fast Sampling of Diffusion Models via Operator Learning
An Interpretable Framework for Drug-Target Interaction with Gated Cross Attention
Understanding Batch Normalization
Normalization はそれ自身に性能を上げる効果はない。Normalization を入れることで高い学習率でも学習が安定するようになり、その結果、速い学習と局所的最適解の回避とが実現している。
拡散モデルのミニ実装
A Gentle Introduction to Diffusion
数学
Mathematics for Machine Learning and Data Science: Optimization with Mathematica Applications
Machine Learning: a Lecture Note
特異値分解(SVD)
scipy.sparse.linalg.svds(アルゴリズムはARPACK(Augmented Implicitly Restarted Lanczos Bidiagonalization Algorithm)を使用)で疎行列の特異値分解ができる。
次元削減目的なら sklearn.decomposition.TruncatedSVD も使える。
VLM
Vision-Language-Vision Auto-Encoder: Scalable Knowledge Distillation from Diffusion Models
画像生成 AI の画像で VLM を学習させる方法。
そのほか
元OpenAIの研究者ら、AIの応答が毎回違う理由をついに解明
He らは、推論時のバッチサイズの違い等が temperature=0 の時の出力のばらつきであることを証明し、その解決方法を紹介している。
Why language models hallucinate pdf
強化学習のような正解か不正解かしか評価しない学習手法がハルシネーション発生の原因のひとつであることを数学的に証明した論文。
正解か不正解かしか評価しない場合、わからないと答えれば確実に0点だが、何らかの回答をすれば正解する可能性があるのでそれがハルシネーションを助長させている。
Exploring Multimodal Diffusion Transformers for Enhanced Prompt-based Image Editing
SD3 や FLUX.1 で余計な部分を変更せずにテキストで画像編集ができるようにする方法。
q, k, v をそれぞれ以下のように分けて考える。この例では画像トークンの後にテキストトークンを配置している。
\[ \mathbf{q}=\begin{bmatrix} \mathbf{q_i} \\ \mathbf{q_t} \end{bmatrix}, \mathbf{k}=\begin{bmatrix} \mathbf{k_i} \\ \mathbf{k_t} \end{bmatrix}, \mathbf{v}=\begin{bmatrix} \mathbf{v_i} \\ \mathbf{v_t} \end{bmatrix} \]すると qkT 行列は以下のように分類できる。
\[ \mathbf{qk^T}=\begin{bmatrix} \mathbf{q}_i \\ \mathbf{q}_t \end{bmatrix} [\mathbf{k}_i\;\mathbf{k}_i] = \begin{bmatrix} \mathbf{q}_i \mathbf{k}_i^T \; \mathbf{q}_i \mathbf{k}_t^T\\ \mathbf{q}_t \mathbf{k}_i^T\; \mathbf{q}_t \mathbf{k}_t^T \end{bmatrix} \sim \begin{bmatrix} \mathrm{I2I} \; \mathrm{T2I}\\ \mathrm{I2T} \; \mathrm{T2T} \end{bmatrix} \]CharaConsist: Fine-Grained Consistent Character Generation
FLUX.1 で Point-tracking Attention と token mergeing を利用してキャラや背景の一貫性を維持する技術。
Runge-Kutta Approximation and Decoupled Attention for Rectified Flow Inversion and Semantic Editing
DDIM Inversion を使った画像編集。
PositionIC: Unified Position and Identity Consistency for Image Customization
画像合成のためのデータセットの作成方法と、アテンションマスクの作成方法。
出典:PositionIC: Unified Position and Identity Consistency for Image Customization. Junjie Hu et al. Figure 3. https://www.alphaxiv.org/abs/2507.13861
LLM推論に関する技術メモ
LLM を利用するサービスを提供する場合の技術的注意点について網羅的に解説されている。
マスクテンソルの作成
block_count は1辺のブロック個数。
import torch
def create_mask(image_size:int, patch_size:int, hide_rate:float, batch_size:int, image_channel:int=3):
"""
Args:
image_size (int): 解像度
patch_size (int): パッチ解像度。F。
hide_rate (float): 数値が増えるとより多くマスクされる。範囲は [0, 1]
"""
assert image_size % patch_size == 0
block_count = image_size//patch_size # 1辺のブロック個数
scale_factor = int(image_size/block_count)
mini_mask = (torch.rand(block_count*block_count) >= hide_rate).float().view(-1,1,block_count,block_count)
mask = torch.nn.functional.interpolate(mini_mask, size=None, scale_factor=scale_factor, mode='nearest-exact')
return mask.expand(batch_size, image_channel, image_size, image_size)
モデルのパラメータ数を計数
print(f'{sum(p.numel() for p in model.parameters() if p.requires_grad):,}')