固定幅入力・逆順生成の動画生成 AI FramePack の論文の解説
Github 論文(Packing Input Frame Context in Next-Frame Prediction Models for Video Generation)
概要
forgetting と drifting とを解決する新しい手法を提案した。
forgetting は過去に生成した動画の内容を忘れることで、drifting はフレームを生成するごとにエラーが蓄積して、画質や内容が徐々に劣化すること。
forgetting と drifting との間にはトレードオフの関係がある。forgetting を解決しようとしてメモリ使用量を増やすと、drifting のエラー蓄積量が増加する。drifting を改善しようとして、生成した動画をマスクしたり、生成した動画にノイズを付与したりすると forgetting が強化される。
Transformer の Attention 機構は入力の長さの2乗のオーダーで計算量が増えるので、メモリ使用量を増やすのも限界がある。それに、動画は時間方向の情報の冗長性が大きく、単純にメモリ使用量を増やすのは効率が悪い。
drifting の発生原因は個々のフレームの初期エラーだ。メモリ使用量を増やすと初期エラーの発生確率を下げるが、発生してしまった初期エラーを修正することが難しくなる。
FramePack ではメモリ構造を工夫することで forgetting に対処し、サンプリングを工夫することで drifting に対処する。重要度の低いフレームを圧縮することで、生成する動画の長さに関係なく入力コンテクストの長さを固定できるようにした。最終フレーム(未来のフレーム)を1枚だけ生成しておいて、それを常に参照できるようにすることで drifting に対処する。
方法
データを潜在空間に圧縮して拡散トランスフォーマーでフレームを生成する。
データの圧縮
F0 を最も最近に生成したフレーム、FT-1 をもっとも古い(一番最初に生成した)フレームとする。
重要度の低いフレームを圧縮する方法にはいくつか方法がある。
- (a) 単純に古い順に圧縮率を上げていく。
- (b) 段階的に圧縮率を上げていく
- (c) 段階的に圧縮率を上げていくその2
- (d) 単純に古い順に圧縮率を上げていくが、最初のフレームは圧縮しない
- (e) 時間的に対称
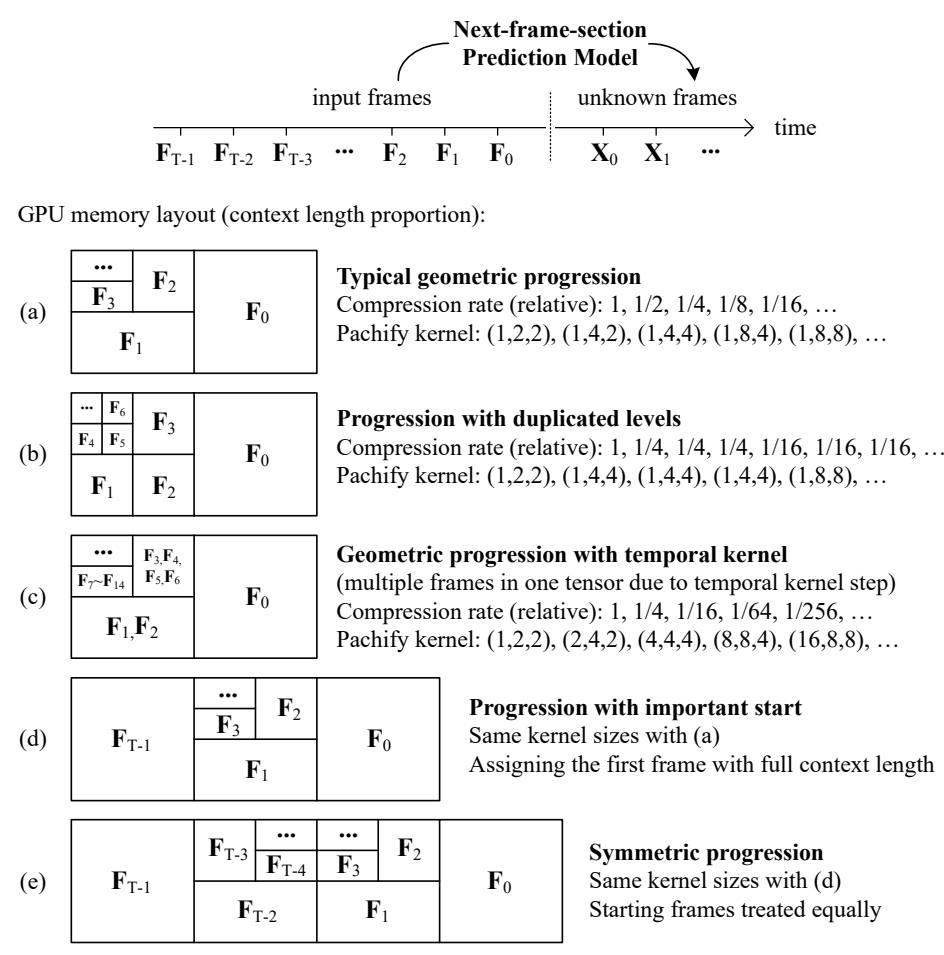
出典:Packing Input Frame Context in Next-Frame Prediction Models for Video Generation Lvmin Zhang et al. Figure 1
d や e は画像から動画を生成する i2v のパターンで有効。
Anti-drifting サンプリング
drifting は過去のフレームだけから未来のフレームを生成する場合にのみ発生し、画像1枚でも未来のフレームを入力すると drifting が発生しないことを発見した。
未来のフレームを入力しつつフレームを生成する方法は2種類ある。
- 最終フレームを最初に生成し、頭から(過去から未来へ向かう方向へ)フレームを生成する方法
- 最終フレームと最初のフレームとを最初に生成し、最終フレームから最初のフレームに向かって、未来から過去へ向かう方向へフレームを生成する方法
画像から動画を生成する i2v では 2. の逆順生成が品質が高い。なぜならユーザーが入力した高品質な画像をリファレンスとして常に活用できるので。
実装
Wan2.1 と HunyanVideo をベースに実装。GitHub のプロジェクトは Hunyan ベース。
FramePack はメモリを 60 GB 使う。VRAM が 60 GB 未満の場合は以下のプロセスで実行する。
- RAM に全てのモデルをロードする。ここで RAM が 60 GB 未満の場合は仮想メモリ(SSD・HDD)が使われる。
- 工程ごとに VRAM にモデルをロードし実行する。
FramePack では以下のモデルを使用している。
| モデル | モデル名(作成者) |
|---|---|
| テキストエンコーダー | Llama |
| テキストエンコーダー2 | CLIP |
| トークナイザー | Llama |
| トークナイザー2 | CLIP |
| VAE | Hunyan |
| 動画生成 | Hunyan |
| 特徴抽出(feature_extractor) | FramePack のオリジナル |
| イメージエンコーダー | FramePack のオリジナル |
WebUI
TeaCache
計算を高速化するオプション。生成内容が変化するためプロンプト確認用。
問題点
カメラが大きく移動したり、フレームを出入りする物体があったりすると破綻しやすい。被写体ではなくカメラを回転させると背景が破綻する。