Qwen Image Edit 2511 を ComfyUI で実行する+プロンプトリスト
目次
- 特徴
- 概要
- ComfyUI のアップデート
- モデル
- ワークフロー
- 動作速度
- 解像度リスト
- keypoint pose 編集
- 日本語のレンダリング
- プロンプト
- 入力画像認識
- 知っておくべき2種類のプロンプトパターン
- プロンプトガイド
- Qwen-Image-Edit-2509 公式プロンプト例
- Qwen-Image-Edit-2511 公式プロンプト例
- カメラアングル変更 LoRa
- Mask Editor
- 作例
特徴
単純な画像生成では Z Image Trubo(パラメータ数 6B)が軽量高品質で強い。
軽量で複数画像の入力なら FLUX.2 klein がある。Qwen Image Edit は品質の高さとプロンプトの追従性で FLUX.2 klein より優れている。
Qwen Image Edit 2511 は Lighting Enhancement LoRa Realistic lighting control のような有名な LoRa を複数マージしている。
欠点
- パラメータ数 20B・テキストエンコーダー 7B でありながら、ひらがな・カタカナのレンダリングが弱い
- モデルが巨大で推論が遅い
概要
8 bit 量子化(Q8_0 や fp8)モデル(21GB)+テキストエンコーダー(9GB)+VAE(0.25GB) で 30 GB なので RAM 32 GB の場合はスワップが発生する。RAM 32GB でスワップを避けたい場合は Q4_K_M などを使う。
最新の ComfyUI は VRAM の量は重要ではなくなっている。なぜなら RAM にモデルをロードして、必要な分を VRAM に転送して処理するようなアルゴリズムになったからだ。画像生成 AI は演算ボトルネックなので、RAM からモデルを転送しつつ推論しても生成速度はほとんど低下しない。
| 量子化 | モデルサイズ | テキストエンコーダー サイズ | 合計 |
|---|---|---|---|
| Q8_0 | 21 | 9.4 | 30 |
| Q6_K | 17 | 9.4 | 26 |
| Q4_K_M (両方) | 13 | 6.0 | 19 |
ComfyUI のアップデート
ComfyUI をアップデートすると TextEncodeQwenImadeEditPlus が使えるようになる。このノードはテキストエンコーダーに画像を3枚まで入力できる。
Qwen-Image-Edit-2509 以降はこのノードを使う。
4枚以上の画像を入力したい場合は、ReferenceLatent ノードを連結する。ただし4枚以上の画像入力が正しく動作する保証はない。
モデル
| 配置場所 | モデル |
|---|---|
| models/unet | qwen-image-edit-2511-Q8_0.gguf |
| models/text_encoders | qwen_2.5_vl_7b_fp8_scaled.safetensors |
| models/vae | qwen_image_vae.safetensors |
| models/lora | lightx2v/Qwen-Image-Edit-2511-Lightning |
高速化 LoRa の Qwen-Image-Lightning は動作させるだけなら不要だが、モデルを常用するなら必須。Lightning でプロンプトを作成し、本番で Lightning を外して生成する。
Qwen Image Edit のオールインワンパッケージ(unet, te, vae, 高速化 LoRa)なら Phr00t/Qwen-Image-Edit-Rapid-AIO がある。
Qwen Image 2512
Qwen Image(Edit ではない)は 2512 でフォトリアルなテクスチャのディティールが向上している。スムースすぎるテクスチャが改善されディティールの豊富な画像が生成されるようになっている。しかし AI で生成したような不自然さは残る。
中国語のフォントレンダリングの性能が上がっている。
- fp8/fp16 Comfy-Org/Qwen-Image_ComfyUI
- GGUF unsloth/Qwen-Image-2512-GGUF
- Lightning LoRa lightx2v/Qwen-Image-2512-Lightning
- 2step LoRa Wuli-art/Qwen-Image-2512-Turbo-LoRA-2-Steps
そのほかのモデル
| パーツ | モデル |
|---|---|
| unet・VAE・テキストエンコーダー | 公式(bf16)Qwen/Qwen-Image-Edit-2511 |
| unet | nunchaku |
| unet(fp8) | qwen_image_edit_2509_fp8_e4m3fn_scaled.safetensors |
| unet(nvfp4) | Bedovyy/Qwen-Image-Edit-2511-NVFP4 |
| テキストエンコーダー | unsloth/Qwen2.5-VL-7B-Instruct-GGUF |
量子化比較
- Nano Banana vs QWEN Image Edit 2509 bf16/fp8/lightning
- city96/Qwen-Image-gguf の例では、Q6_K 以上はほぼ BF16 と同じ
- Comparison of Qwen-Image-Edit GGUF models
8bit 量子化
RTX 4000 番台以降では (scaled) fp8 をハードウェアで高速に実行できる。RTX 4000 番台以降なら、scaled_fp8 は速度と品質とでベストな選択。
- 品質:Q8_0 > scaled_fp8 >> fp8
- 速度:scaled_fp8 = fp8 >> Q8_0
ワークフロー
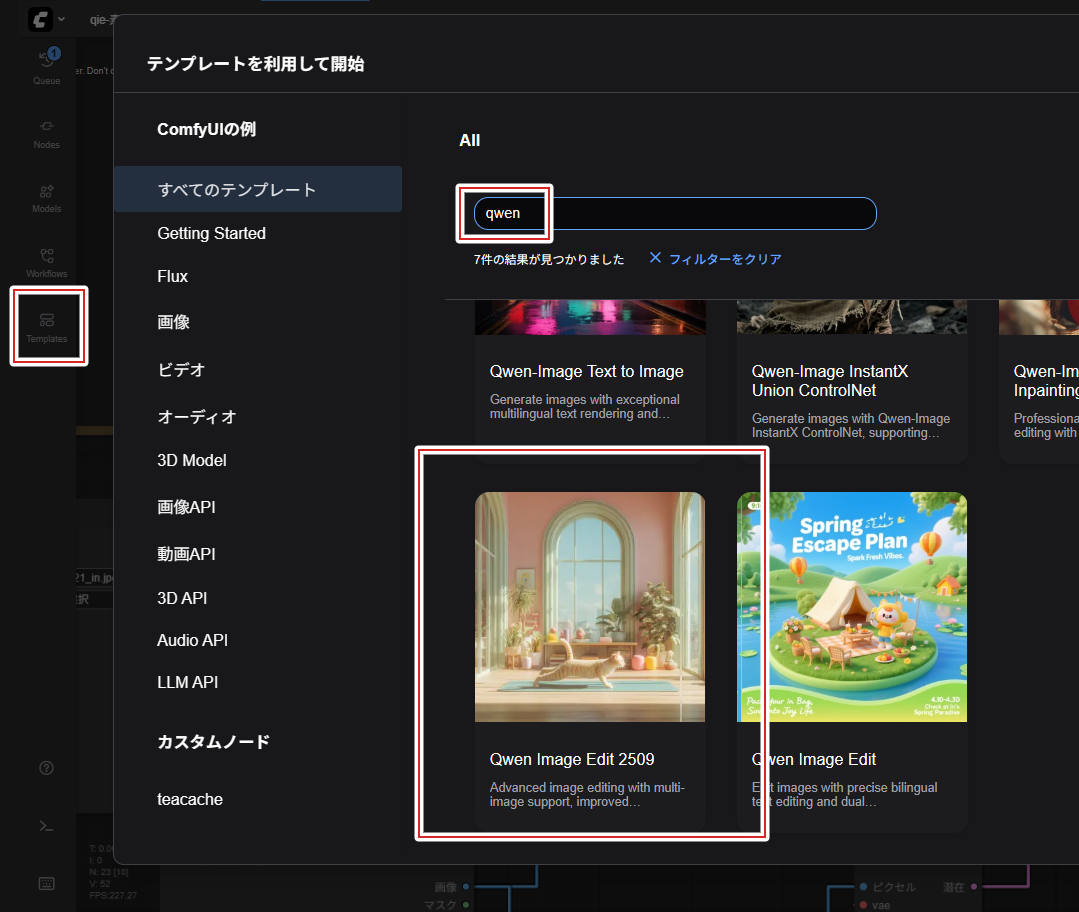
公式ワークフローの場所
ワークフローは git pull でアップデートされない。requirements.txt でバージョン管理されているので pip を実行する必要がある。
git pull ./venv/Scripts/activate pip install -r requirements.txt
動作速度
高速化 LoRa を使わない場合、CFG ありの 20 step あたりが品質の許容範囲。CFG なしだったり steps が 20 未満だと画像がソフトになりやすい。
環境
- OS:Win11 24H2
- RAM:DDR4 32GB
- GPU:RTX3050
- VRAM:8 GB
- torch 2.9.1+cu128
FlashAttention
- 入力画像二枚(408x1,024, 406x724)
- 出力解像度 1,024 x 1,024
| Attention | 速度 (s/it) |
|---|---|
| FlashAttention | 26.5 |
| Pytorch Attention (デフォルト) | 26.2 |
SageAttention
SageAttention v2.2.0-windows.post4 なら Qwen Image (Edit) でも正常に生成できる場合がある。それでもだめなら v2.2.0.post4 + TorchCompileModel ノードを試してみる。
環境
- Python 3.12.9
- torch 2.9.1+cu128
- triton_windows-3.5.1.post23
- SageAttention v2.2.0-windows.post4
- TorchCompileModel ノード未使用
- 入力画像二枚(408x1,024, 406x724)
- 出力解像度 1,024 x 1,024
| Attention | 速度 (s/it) |
|---|---|
| SageAttention | 23.4 |
| Pytorch Attention (デフォルト) | 26.2 |
外部リンク
- Qwen-Image doesn't seem to play nice with Sage Attention
- Torch/python/cuda の問題と互換性の問題(特に triton/sageattn との)が本当に嫌い、マジで地獄だよ
- using sageattention 2 qwen-image in comfyui shows black images due to buggy upstream sageattention triton implementation, includes fix #9773
解像度リスト
Qwen Image のネイティブ解像度は 1,328 x 1,328。
| アスペクト比 | ピクセル数 |
|---|---|
| 1:1 | 1328 x 1328 |
| 16:9 | 1664 x 928 |
| 9:16 | 928 x 1664 |
| 4:3 | 1472 x 1104 |
| 3:4 | 1104 x 1472 |
| 3:2 | 1584 x 1056 |
| 2:3 | 1056 x 1584 |
拡張解像度
ここまでの解像度なら分裂せずに、アップスケールなしで生成できる可能性が高い。16:9 は分裂した。
| アスペクト比 | ピクセル数 |
|---|---|
| 1:1 | 1792 x 1792 |
| 2:3 | 1472 x 2176 |
| 3:4 | 1584 x 2048 |
keypoint pose 編集
Qwen Image Edit 2509 以降は keypoint pose の入力にも対応している。
画像から keypoint pose 画像を抽出するには comfyui_controlnet_aux ノードでできる。ポーズコピーは DWPose Estimator なしでもできるが、画像の余計な情報がノイズにならないのが利点。
blender
操作方法は Blender+ControlNetを用いたアニメーションの作り方 を参照。
Openpose Full VRM avatar for Free無料 (stablediffusion)
日本語のレンダリング
Edit モデルにレンダリング済みテキスト画像を渡すテクニックは nano-bananaで技術同人誌の表紙デザインを作りたい!やQwen-Imageに日本語を書かせるがある。
dskjal/comfyui-text-renderer:縦書きに対応させたバージョン
プロンプト
There is a piece of paper on a table. That paper with "あいうえおアイウエオ かきくけこカキクケコ さしすせそサシスセソ たちつてとタチツテト なにぬねのナニヌネノ はひふへほハヒフヘホ まみむめもマミムメモ やゆよヤユヨ らりるれろラリルレロ わをんワヲン 日本語と漢字の検証" written on it.

Qwen Image Edit 2511

Qwen Image Edit 2511 text-renderer あり
高速化 LoRa ありで8ステップ
縦書きの画像を用意できれば縦書きも可能。
The illustration of a chibi girl sitting in a chair eating a piece of pizza. She is saying "日本語の フキダシを ちゃんと縦に 書けるかな?" in a speech bubble in vertical writing. There is a table and a window in the indoor room.

テキスト画像の解像度が大きすぎた場合

吹き出しの中に自動的に収めてくれたりはしない
プロンプト
Qwen Image(Edit)は生成される画像に多様性がない。なのでシードガチャは無意味で、適切なプロンプトの編集能力が重要になる。
ガチャがやりたい場合は「fdahoiuhroewa」のようなランダムな文字列をプロンプトに入れる方法がある。
入力画像認識
Qwen Image Edit は入力画像(image1, image2)を識別できる。
例えば、画像を2枚入力して以下のプロンプトで画像を生成する。入力画像を認識できない場合、キャラの配置は左右ランダムになる。しかし 10 枚ランダムシードで実験したところ、9枚が指示通りに配置された(二項検定で p 値 ≒ 0.0215)。
A girl in image1 is sitting on the right side of the sofa in the living room. A girl in image2 is sitting on the left side of the sofa in the living room. Anime style.
知っておくべき2種類のプロンプトパターン
差分指定
「Change A to B.」の形式。単純なタスクならこの形式でも可能だが、タスクが複数かつ複雑になると高確率で失敗する。
入力画像の特定1箇所を変更する場合に使える。
内容指定
完成後の画像のプロンプトを入力する。入力画像を使ってほしい場合は image 1 (figure 1) 等の語で指定する。
There is a bag in image1 on a display table in the luxuary show room. A woman in image2 is standing on the right side of the bag.
プロンプトガイド
nano banana
- Claude × Nano Banana Pro で料理漫画を自動生成するパイプラインを作った
- Nano Banana Pro プロンプト検索
- Banana X プロンプトパターン集(インフォグラフィック作例集)
- Awesome-Nano-Banana-images
- 7 tips to get the most out of Nano Banana Pro
- 文字も図解も思いのまま!Nano Banana Pro の凄さと、今すぐ使える活用術
- グーグルの画像生成AI「Nano Banana」は異次元レベル AIコンテンツの作り方を根本から変えた
- Googleの画像生成AI「Nano-banana」をめちゃくちゃ活用できるプロンプトとサンプル画像実例まとめ
- Gemini を使った画像生成(別名 Nano Banana)
- How to prompt Gemini 2.5 Flash Image Generation for the best results
- Geminiの「Nano Banana」で不動産写真の家具を消してみた話
- nano-bananaでモバイルアプリUIモックアップを作る
- nano banana漫画背景生成
- 【Midjourney | Nano Banana】商品撮影のプロが撮影をやめた。誰も教えない、ブランドやECの現場レベルで使える画像生成AIと動画生成AIの神業プロンプトまとめ。
- 画像生成AI「Nano Banana Pro」で判明した“ストーリーボード革命”
- How to Design Magazine Layouts and Covers Using Nano Banana Pro
- Is Nano Banana Pro a Low-Level Vision All-Rounder? A Comprehensive Evaluation on 14 Tasks and 40 Datasets
- Nano Banana can be prompt engineered for extremely nuanced AI image generation
- Nano Banana Pro is the best AI image generator, with caveats
- もう失敗しない。AIで筆文字を書く方法
ChatGPT Image 1.5
Qwen Image
- Qwen-Image-Edit Prompt Guide: The Complete Playbook
- Qwen-Image: Prompt & Parameter Guide
- Simple multiple images input in Qwen-Image-Edit
- Tips for getting the best image generation and editing in the Gemini app
Qwen-Image-Edit-2509
画像の出典はすべて https://huggingface.co/Qwen/Qwen-Image-Edit-2509。
多图結婚照(複数人のウェディングフォト・Multiple wedding photos)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 2枚の画像を入力。 | input two images. | 输入2张图片。 |
| 図1の女性と図2の男性に基づいて、以下の説明を含む結婚写真を生成してください。新郎は赤い中国風の上着を着ており、新婦は精巧な秀禾服と金色の鳳凰冠をかぶっています。二人は古代の朱色の宮殿の壁の前で並んで立っており、背景には彫刻が施された木製の窓があります。照明は明るく柔らかく、構図は対称的で、祝祭的で厳粛な雰囲気が漂っています。 | Based on the woman in image1 and the man in image2, a wedding photo was generated with the following description: the groom wears a red Chinese-style jacket, and the bride wears an exquisite Xiuhe dress and a golden phoenix crown. They stand side by side before an ancient vermilion palace wall, with a carved wooden window in the background. The lighting is bright and soft, the composition is symmetrical, and the atmosphere is festive and solemn. | 根据这图1中女性和图2中男性,生成一組结婚照,并遵循以下描述:新郎穿着红色的中式马褂,新娘穿着精致的秀禾服,头戴金色凤冠。他们并肩站立在古老的朱红色宮墙前,背景是雕花的木窗。光线明亮柔和,构图对称,氛围喜庆而庄重 |
| 図1の女性と図2の男性に基づいて、以下の説明を含む結婚写真を生成してください。温かみのある韓国風の室内での結婚式の写真です。二人はシンプルながらもエレガントなガウンを身にまとっています。真っ白な壁と流れるような白い紗のカーテンを背景に、明るい窓辺に座っています。二人は寄り添い合い、優しく自然な笑顔を浮かべています。照明は非常に柔らかく、温かみのあるオフホワイトの色合いです。画像は清潔感があり、純粋で、優雅です。 | Generate a set of wedding photos based on the woman in image1 and the man in image2, with the following description: A warm, Korean-style indoor wedding photo. They are wearing simple yet elegant gowns. They sit by a bright window, against a backdrop of pure white walls and flowing white gauze curtains. They cuddle with each other, their smiles sweet and natural. The lighting is very soft, with a warm off-white hue. The image is clean, pure, and elegant. | 根据这图 1 中女性和图 2 中的男性,生成一组结婚照,并遵循以下描述:一张温馨的韩式室内婚纱照,他们穿着简约而优雅的礼服。两人坐在一个明亮的窗边,背景是纯白色的墙壁和飘动的白纱帘,互相依偎,笑容甜美自然。光线非常柔和,色调是温暖的米白色,画面干净、纯粹、高级。 |
多图人物放置(複数人の人物配置・Multiple image character placement)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 生成された画像 | a generated image | 生成 1 张图像 |
| 図 2 の少女は、図 1 のラウンジチェアで日光浴をしています。 | The woman in image2 is sunbathing on the lounge chair in image1. | 图2中的女生在图1躺椅上晒太阳 |
| 図2の女の子は図1のソファでコーヒーを飲んでいます。 | The woman in image2 is drinking coffee on the sofa in image1. | 图2中的女生在图1的沙发上喝咖啡 |
多图模特商品展示(モデルと商品の合成・Multi-image model product display)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 写真2の女の子は写真1のバッグを肩にかけています。 | The woman in picture 2 is wearing the bag in picture 1 on her shoulder. | 图2中的女生肩膀上挂着图1中的包 |
| 図 1 の女の子は、図 2 の車の隣に立っています。 | The woman in image1 is standing next to the car in image2. | 图1中的女生站在图2的车旁边 |
多图关键点姿势(キーポイントポーズでポーズ指定・Multi-image keypoint pose)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 図2の女の子の姿勢を図1の姿勢に変えてください。 | The woman in image2 changes to the posture in image1. | 图 2 中的女生改变为图 1 中的姿势。 |
| 図2の少女の姿勢を図1のポーズに変え、背景を昔の宮殿に変え、手に帽子を持たせてください。 | The woman in image2 changes to the pose in image1, with the background changed to the old palace, and holds the hat in her hand. | 图 2 中的女生改变为图 1 的姿势,并且背景换为故宮,并且把帽子拿在手上 |
多图人物放置(複数人の人物配置・Multiple image character placement)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 3枚の画像を入力。 | input three images. | 输入3张图片。 |
| 図 1 の女の子と図 2 の女の子が図 3 のソファでコーヒーを飲んでいます。 | The woman in image1 and the woman in image2 drinking coffee on the sofa in image3. | 图 1 中的女孩和 图 2 中的女孩在 |
多图关键点穿衣姿势(姿勢と服の変更・Multiple key points of dressing posture)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 図 1 の女の子は、図 2 の黒いスカートを着用し、図 3 に示す姿勢で座っています。 | The woman in image1 is wearing the black skirt in image2 and sitting in the position shown in image3. | 图 3 的姿势坐下 |
多图模特商品展示(モデルと商品の合成・Multi-image model product display)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 図 3 の少女は、図 2 のバッグと図 1 のネックレスを付けています。 | The woman in image3 is wearing the bag in image2 and the necklace in image1. | 图 3 中的女孩带着图 2 中的包包 和图 1 的项链 |
形象照片生成(イメージ写真生成・Image photo generation)

证件照(証明写真・ID photo)
| 日本語 | 英語 | 中国語 |
|---|---|---|
| 白いシャツ、黒いスーツ、ストライプのネクタイを着用した、青い背景の身分証明書用写真に変更してください。 | Modified to a blue background ID photo, with the person wearing a white shirt, black suit, and striped tie. | 修改为蓝底证件照,人物穿上白色衬衫,黑色西装,打着条纹领带 |
形象照(イメージ写真・Image photo)
| 日本語 | 英語 | 中国語 |
|---|---|---|
| 男性は白いシャツ、グレーのスーツ、ストライプのネクタイを着用し、片手でネクタイに触れている。背景は明るい。 | The man is wearing a white shirt, a gray suit, and a striped tie, with one hand touching the tie. Light background. | 人物穿上白色衬衫,灰色西装,打着条纹领带,一只手摸着领带。浅色背景。 |
生活照(生活写真・Life photo)
| 日本語 | 英語 | 中国語 |
|---|---|---|
| 人物は太い筆致で「千问图像」と書かれた黒いスウェットシャツを着ている。ガードレールに寄りかかり、髪に陽光が照りつけ、背後には橋と海が広がっている。 | The figure is wearing a black sweatshirt with the words "千问图像" emblazoned on it in thick brushstrokes. He leans against a guardrail, sunlight shining on his hair, with a bridge and the sea behind him. | 人物穿着粗笔刷字体的“千问图像"的黑色卫衣,依靠在护栏边,阳光照在发丝上,身后是大桥和海。 |
千问图像=Qwen Image
姿势编辑(ポーズ変更・Pose Editing)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 彼女は両手をあげ、手のひらをカメラに向けて指を広げ、遊び心のある仕草をした。 | She raised her hands, palms facing the camera, fingers spread, in a playful gesture. | 她双手举起,手掌朝向镜头,手指张开,做出一个俏皮的姿势 |
| 彼女は手でハートの形を作りました。 | She made a heart shape with her hands. | 她两只手摆出一个爱心的形状 |
| 彼女は「欢迎来到云栖大会」と書かれた黒板を掲げた。 | She held up a blackboard with the words "欢迎来到云栖大会" written on it. | 她两只手拿起一个黑板,上面写着“欢迎来到云栖大会" |
欢迎来到云栖大会=Welcome to the Yunqi Conference・云栖大会(Yunqi Conference)へようこそ
云栖大会(Yunqi Conference)は、阿里巴巴集団(Alibaba Group)が主催する、中国を代表するクラウドコンピューティングと人工知能(AI)を中心としたテクノロジーの年間イベント。
表情包生成(ミーム生成・Emoticon generation)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| プロンプトテンプレート:指を1本前に突き出した、幸せそうな表情に変身。その下に「我支持通义千问」というアートテキストが書かれている。 | Prompt template: Change to a happy expression with one finger pointing forward. Below it is the artistic text "我支持通义千问" | Prompt模板:改成开心的表情,一只手指向前方。下方写着艺术字"我支持通义千问" |
通义千问=LLM の Qwen。
我支持通义千问=Qwen を応援
虚拟场景生成(仮想シーンの生成・Virtual scene generation)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 男はカメラの前に、縦に3/4ほどの黒いマーカーを持っている。背後のガラス板には、次のように書かれている。「I. Qwen-lmageの技術ロードマップ:基本的な画像生成モデルの限界を探り、統合的な理解と生成の未来を創造する。II. Qwen-lmageのモデル機能:1. 複雑なテキストレンダリング:中国語と英語のレンダリング、自動レイアウトをサポート。2. 精密な画像編集:テキスト編集、オブジェクトの追加と削除、スタイル変換をサポート。III. Qwen-lmageの将来ビジョン:プロフェッショナルなコンテンツ作成を支援し、生成AIの発展を促進する。」 | The man holds a black marker, three-quarter-length in front of the camera. Written on the glass panel behind him are the following: "I. Qwen-lmage's Technical Roadmap: Exploring the Limits of Basic Visual Generation Models, Creating a Future of Integrated Understanding and Generation. II. Qwen-lmage's Model Features: 1. Complex Text Rendering: Supports Chinese and English rendering, and automatic layout; 2. Precise Image Editing: Supports text editing, object addition and subtraction, and style transformation. III. Qwen-lmage's Future Vision: Empowering Professional Content Creation and Boosting the Development of Generative AI." | 这个男人拿着黑色的马克笔四分之三面相镜头。他身后的玻璃板上写着"一、 Qwen-lmage 的技术路线:探索视觉生成基础模型的极限,开创理解与生成一体化的未来。二、 Qwen-lmage 的模型特色:1 、复杂文字渲染。支持中英渲染、自动布局; 2 、精准图像编辑。支持文字编辑、物体增减、风格变换。三、 Qwen-lmage 的未来愿景:赋能专业内容创作、助力生成式 AI 发展。" |
照片上色(彩色・Coloring)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| コンテンツに基づいたインテリジェントなカラーリングにより、画像をより鮮やかに表現してください。 | Intelligent coloring based on content to make images more vivid. | 根据内容智能上色,使图像更生动 |
照片修复(写真修復・Photo Restoration)
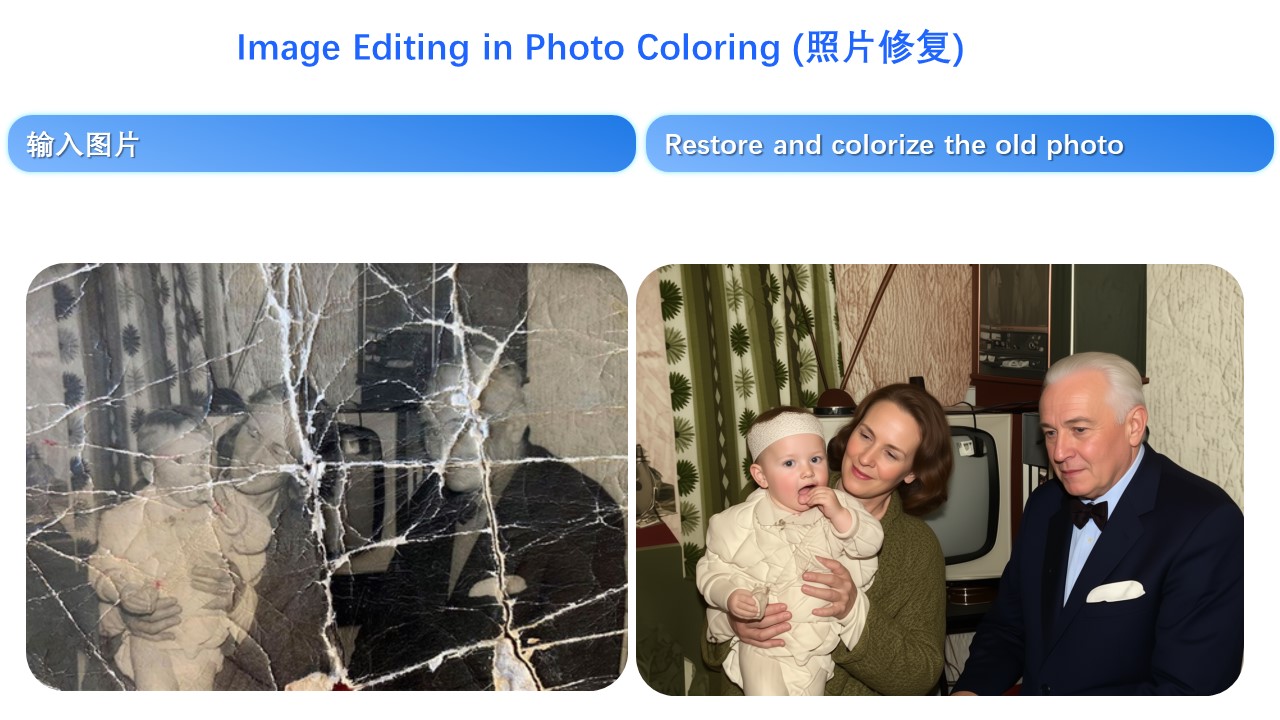
何故かプロンプトが英語。
| 日本語 | 英語 | 中国語 |
|---|---|---|
| 古い写真の修復し、カラー化してください。 | Restore and colorize the old photo. | 修复并为老照片上色。 |
文创生成(クリエイティブ生成・Cultural and Creative Generation)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| このマスコットは月(白い背景に薄い灰色の三日月の輪郭で表されている)の下に座ってギターを抱えており、その周りに小さな星や「Be Kind(親切に)」などの詩の吹き出しが浮かんでいる姿で描かれている。 | The mascot is depicted sitting under the moon (represented by a light grey crescent moon outline on a white background) holding a guitar, with little stars and poetry bubbles floating around him, such as "Be Kind". | 让这只吉祥物,坐在月亮下(用白色背景上的浅灰弯月轮廓表示),抱着吉他,周围漂浮着小星星和诗句气泡,如 "Be Kind ”。 |
| 市販品としてデザインされた、リアルな1/7スケールのキャラクターモデルが、白いキーボードが置かれたiMacのデスクに置かれています。モデルは、ラベルや文字のない、すっきりとした円形の透明アクリル台座の上に立っています。プロ仕様のスタジオ照明が、彫刻されたディテールを際立たせています。背景のiMacの画面には、同じモデルのZBrushモデリングプロセスが表示されています。モデルの隣には、前面に透明な窓があり、中の透明なプラスチックシェルだけが見える梱包箱が置かれています。箱はモデルよりわずかに高く、モデルが収まるサイズになっています。 | A realistic 1/7 scale character model, designed as a commercial product, sits on an iMac computer desk with a white keyboard. The model stands on a clean, round, clear acrylic base, devoid of labels or text. Professional studio lighting accentuates the sculpted details. On the iMac screen in the background, the ZBrush modeling process for the same model is displayed. Next to the model sits a packaging box with a clear window in the front, revealing only the transparent plastic shell within. It stands slightly taller than the model and is sized appropriately to accommodate it. | 一个起逼真的 1 / 7 比例角色楼型,设计为商业产品成品,放置在一台带有白色键盘的iMac 电脑桌上。模型站在一个干净、圓形的透明亚克力底座上,没有标签或文宇。专业的摄影棚灯光突显了雕刻细节。在背景的 iMac 屏幕上,展示同一模型的 ZBrush建模过程。在模型旁边,放置一个包装盒,前面带有透明窗户,仅显示内部透明塑料壳,其高度略高于模型,尺寸合理以容纳摸型。 |
| このデザインをTシャツとトートバッグにプリントしてください。女性モデルがこれらのアイテムを身につけています。また、女性は「Be kind」と書かれた野球帽をかぶっています。 | Print this design on a T-shirt and a tote bag. A female model displays these items. The woman also wears a baseball cap with the words "Be kind" written on it. | 将这个图案印在一件 T 恤和一个手提紙袋上。一个女模特正在展示这些物品。这个女生还着一顶鸭舌帽,帽子上写着“Be kind"。 |
商品宣传图编辑(宣材画像編集・Product promotional images editing)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| このエアコンをリビングルームのソファの隣に置いてください。 | Put this air conditioner in the living room, next to the sofa. | 把这个空调放在客厅,沙发旁边 |
| エアコンの吹き出し口からソファーまでミストを吹きかけ、緑の葉を添えます。 | Add mist to the air-conditioning outlet, all the way to the sofa, and add green leaves. | 在空调出风口增加雾气,一直到沙发上,并且增加绿叶。 |
| 上部に白い手書きの「自然の新鮮な空気をお楽しみください」を追加します。 | Add white handwriting "Enjoy the natural fresh air" at the top. | 在上方增加白色的手写体"自然新风畅享呼吸" |
材质编辑(質感編集・Texture Edit)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 青い部分をダークサファイア素材、白い部分をライトサファイア素材に質感を変換してください。 | Converted to sapphire, the blue part is dark sapphire material, and the white part is light sapphire material. | 转换为蓝宝石,蓝色部分是深蓝宝石材质,白色部分是浅蓝宝石材质。 |
| 紫色の花をあしらった繊細な刺繍に変換。 | Transformed into delicate embroidery featuring purple flowers. | 转换为精致的刺绣,刺有紫色的花朵 |
| 繊細なエナメル素材で、青い部分は濃い青に、白い部分は金色に変えてください。 | Delicate enamel material, the blue area turns dark blue and the white area turns gold | 精致的珐琅材质,蓝色区域变成深蓝,白色区域变成金色 |
| 繊細なネックレスを作ります。光沢があり、キラキラと輝きます。明るい背景です。 | Makes a delicate necklace. Lustrous and sparkling. Light background. | 制作一个精致的项链。光泽闪耀。浅色背景。 |
| 柔らかなオフホワイトの色合いに、ほのかなパール仕上げを施した上質な牛革バッグ。フロント中央にこのモチーフが刺繍されています。明るい背景です。 | Fine cowhide bag in a soft off-white hue with a subtle pearlescent finish, featuring this motif embroidered in the center of the front. Light background. | 梢致牛皮包,呈现柔和米白色调,表面带有细腻珠光涂层,正面中央绣着这个图案。浅色背景。 |
| 未来のテクノロジー製品のための非常に豪華なパッケージボックス。マット仕上げのディープブラックカーボンファイバーとブラシ仕上げのシャンパンゴールドの金属フレームで作られており、中央にこのアイコンがエンボス加工されています。 | An extremely luxurious packaging box for futuristic technology products, made of matte deep black carbon fiber and brushed champagne gold metal frame, with this icon embossed in the center. | 一个极致奢华的未来科技产品包装盒,采用哑光深黑碳纤维材质与拉丝香槟金金属边框,中央立体浮雕着这个图标。 |
字体类型编辑(フォントタイプ編集・Font Type Edit)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| フォントタイプ編集プロンプトテンプレート: 「Qwen-Image」を黒フォントXXXフォントに変更してください。 | Font type editing prompt template: Change "Qwen-Image" to black font XXX font. | 字体类型编辑prompt模板:把 "Qwen-Image" 换成黑色的字体 XXX 字体 |
| 入力画像 | input image | 輸入图片 |
| 滴墨字体 | droplet font | 滴墨字体 |
| 手書きフォント | Handwritten fonts | 手写字体 |
| ゴシック体 | Gothic font | 哥特字体 |
| ピクセルフォント | Pixel font | 像素字体 |
| 中空漫画フォント | Hollow cartoon font | 镂空卡通字体 |
| 太い筆 | Thick brush | 粗笔刷 |
| 3次元フォント | Three-dimensional fonts | 立体字体 |
| クリエイティブフォント | Creative Font | 创意字体 |
字体颜色编辑(フォント色編集・Font Color Edit)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| フォントカラー編集プロンプトテンプレート: 「Qwen-Image」をXXX色に変更してください。 | Font color editing prompt template: Change "Qwen-Image" to XXX color. | 字体颜色编辑prompt模板:把 "Qwen-Image" 换成 XXX 色 |
| 赤 | red | 红色 |
| 青 | blue | 蓝色 |
| グラデーション | gradation | 渐変色 |
| 青紫グラデ | blue purple gradataion | 蓝紫渐変色 |
| 青ピンクグラデ | blue pink gradation | 蓝粉渐変色 |
| 光紫 | Fluorescent purple | 荧光紫色 |
| 虹色 | Rainbow colors | 彩虹色 |
| キャンディーカラー | candy colors | 糖果色 |
字体材质编辑(フォントテクスチャ編集・Font Texture Edit)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| フォントの質感編集プロンプトテンプレート:「Qwen-Image」の質感をXXXに変更してください。 | Font material editing prompt template: Change the "Qwen-Image" material to XXX. | 字体材质编辑prompt模板:将 "Qwen-Image" 材质换成 XXX |
| 金属 | metal | 金属 |
| 液体金属 | Liquid metal | 液态金属 |
| 雲 | clouds | 云朵 |
| 木材 | wood | 木材 |
| 風船 | balloon | 气球 |
| 翡翠 | jade | 玉石 |
| ガラス | glass | 玻璃 |
| 手織り紙 | Hand-woven paper | 手丝纸 |
书法文字编辑(手書き文字編集・Calligraphy editing)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| t2i 生成した文書 | Generated by Text-to-image generation | 文生图效果 |
| タイプミスボックスはユーザーが手動で追加する必要がある。 | Typo box manually added by the user. | 用户手动增加的错字框 |
| 赤枠の文字を「稽」、青枠の文字を「契」に変更します。 | Change the red-framed characters to "稽" and the blue-framed characters to "契". | 把红框的字改成“稽",蓝色框的字改成“契" |
场景文字编辑(背景文字編集・Scene Text Editing)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 修正箇所はユーザーが手動で追加する必要がある。 | Areas manually painted by the user. | 用户手动涂抹的区域 |
| 試験管の赤いマスク部分を、既存の手書きラベルのスタイルに合わせて、試験管の中央に青いインクで「血样A」というテキストに置き換えてください。 | Replace the red mask on the test tube with the text "血样A," positioned centrally on the tube, in blue ink, matching the style of the existing handwritten labels. | 将试管上的红色标签替换为蓝色墨水书写的“血样A”字样,该标签需居中放置于试管上,且字体风格需与现有手写标签保持一致。 |
| ガラス試験管に青いインクで「血液サンプル A」というテキストを追加します。テキストは上部近くに水平に揃え、既存のラベルのスタイルに一致する明瞭で読みやすいフォントで書かれています。 | Add the text "Blood Sample A" on the glass test tube in blue ink, positioned near the top, aligned horizontally, and written in a clear, legible font matching the style of existing labels. | 在玻璃试管上用蓝色墨水添加文字“血样A”,位置靠近顶部,水平居中,字体清晰易辨且与现有标签风格一致。 |
海报编辑(ポスター編集・Poster Editing)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 「2025 云栖大会」を漫画フォントに変更してください。 | Changed "2025 云栖大会" to a cartoon font. | 把“ 2025 云栖大会" 改成卡通字体 |
| 透明な立方体を漫画風に変えて擬人化した表現を加えます。 | Change the transparent cube into a cartoon style and add anthropomorphic expressions. | 把透明的立方体改成卡通风格,增加拟人化表情。 |
| 芝生の上に擬人化された立方体を持った小さな男の子と女の子を追加してください。 | Add a little boy and girl holding an anthropomorphic cube on the lawn | 在草坪上增加一个小男孩和小女孩,共同拿着拟人化的立方体 |
深度图控制(深度マップ制御・Depth Map Control)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 図 1 に示されている深度マップと一致し、次の説明に従う画像を生成してください。道路の隣の路地に青い自転車が駐車されており、背景の石からいくつかの植物が生えています。 | Generate an image that matches the depth map outlined in image1 and follows the following description: a blue bicycle is parked in an alleyway next to a street, and there are several plants growing out of the stone in the background. | 生成一张图像,符合图 1 所勾勒出的深度图,并遵循以下描述:在一条街边的小巷中停放着一辆蓝色的自行车,背景中有几株从石中长出来的 |
| 図 1 に示されている深度マップと一致し、背景の深い森のぬかるんだ道に赤い使い古しの自転車が停まっているという説明に従う画像を生成してください。 | Generate an image that matches the depth map outlined in image1 and follows the following description: a red, worn-out bicycle parked on a muddy path with a dense forest in the background. | 生成一张图像,符合图 1 所勾勒出的深度图,井遵循以下描述:一辆红色的破旧的自行车停在一条泥泞的小路上,背景是茂密的原林 |
关键点控制(キーポイント制御・Key Point Control)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 図 1 に示されている人間の姿勢と一致し、以下の説明に従う画像を生成してください。蘇州古典園林を背景に、雨の中で油紙の傘を持った漢服を着た美しい中国人女性。 | Generate an image that matches the human posture outlined in image1 and follows the following description: a beautiful Chinese woman wearing Hanfu, holding an oil-paper umbrella in the rain, with Suzhou gardens in the background. | 生成一张图像,符合图 1 所勾勒出的人体姿态,并遵循以下描述:一位身穿着汉服的中国美女,在雨中撑着油纸伞,背景是苏州园林。 |
| 図1に示されている人物のポーズに一致し、以下の説明に従う画像を生成してください。男性が地下鉄のプラットフォームに立っています。彼は野球帽、Tシャツ、ジーンズを着用しています。背景には電車が通過しています。 | Generate an image that matches the human pose outlined in image1 and follows the following description: A man is standing on a subway platform. He is wearing a baseball cap, a T-shirt, and jeans. A train is passing by in the background. | 生成一张图像,符合图 1 所勾勒出的人体姿态,并遵循以下描述:一位男生,站在地铁站台上,他头上戴着一顶棒球帽,穿着 T 恤和牛仔裤。背后是飞驰而过的列车。 |
草图控制(スケッチ制御・Sketch Control)

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 図1に示されている繊細な形状にフィットし、以下の説明に従う画像を作成してください。晴れた日に、若い女性が微笑んでいます。彼女はヒョウ柄のフレームが付いた茶色の丸いサングラスをかけています。髪はきちんとまとめられており、耳には真珠のイヤリングをしています。首には白い星がついた濃紺のスカーフを巻き、黒いレザージャケットを着ています。 | Generate an image that fits the delicate shape outlined in image1 and follows the following description: A young woman is smiling on a sunny day. She is wearing a pair of brown, round sunglasses with leopard print frames. Her hair is neatly tied up, and she has pearl earrings in her ears. She has a dark blue scarf with white stars around her neck and a black leather jacket. | 生成一张图像,符合图 1 所勾勒出的精致形状,并遵循以下描述:一位年轻的女子在阳光明媚的日子里微笑着,她戴着一副棕色的圆形太阳镜,镜框上有豹纹图案。她的头发被整齐地盘起,耳朵上佩戴着珍珠耳环,脖子上围着一条带有白色星星图案的深蓝色围巾,穿着一件黑色皮夹克。 |
| 図1に示す繊細な形状に適合し、以下の説明に従う画像を生成してください。高齢の男性がカメラに向かって微笑んでいます。顔にはしわが寄っており、髪は風になびき乱れ、丸縁の老眼鏡をかけています。首には星柄の使い古した赤いスカーフを巻き、綿のコートを着ています。 | Generate an image that fits the delicate shape outlined in image1 and follows the following description: An elderly man smiles at the camera. His face is wrinkled, his hair is messy in the wind, and he wears round-framed reading glasses. Around his neck, he wears a worn red scarf with a star pattern on it and a cotton coat. | 生成一张图像,符合图 1 所勾勒出的精致形状,并遵循以下描述:一位年老的老人朝着镜头微笑,他的脸上布满皱纹,头发在风中凌乱,戴着一幅圆框的老花镜。脖子上戴着一条破旧的红色围巾,上面有星星图案。穿着一件棉衣。 |
Qwen-Image-Edit-2511
画像の出典はすべて https://huggingface.co/Qwen/Qwen-Image-Edit-2511。

| 日本語 | 英語 | 中国語 |
|---|---|---|
| クリスマスをテーマにした、清純で魅惑的な魅力を持つ美しい若い女性のイメージが生成されました。彼女の顔はそのままです。ゆるい二重の三つ編みは低く結ばれ(カラフルな布のポンポンで飾られています)、若々しい魅力と無邪気な目を醸し出しています。彼女はクリスマスツリーの形をしたヘアアクセサリーを着けており、頭には小さな円錐形のクリスマスツリーがきちんと固定され、その上に金色の五芒星が飾られています。木の幹には色とりどりのライト、金色の鈴、リボン、赤、青、金色の小さなポンポンが飾られ、繊細でボリュームのあるアレンジメントになっています。彼女の白い肌は翡翠のように滑らかで繊細です。清純で魅惑的な霞フィルターを適用し、赤褐色のアイシャドウを自然にブレンドしています。彼女はサンタクロースの人形を両手に持ち、クリスマスの精神を放っています。彼女の目と表情は祝祭の雰囲気を伝え、少し首を傾げています。遊び心のある愛嬌のあるポーズ、可愛らしさとセクシーさが完璧に融合し、印象的なコントラストを生み出しています。少し乱れた髪は、頭上のクリスマスツリーと自然に溶け合い、ふわふわの赤いトップスを着ています。温かみのある白を背景に、スタジオの柔らかな照明、低コントラスト、低彩度、繊細なフィルムグレイン、わずかな色収差、柔らかなフィルムの輝き、温かく癒しの雰囲気、独特な視点、型破りな構図、70mmフィルムポートレート風の緑色のグラフィティで描かれた人物の輪郭、その周囲には様々な可愛いクリスマスグラフィティが散りばめられ、子供らしい楽しさと手描きのコラージュ感覚に満ちています。人物の輪郭は蛍光レッド、グリーン、ゴールドの点線で囲まれ、可愛らしい「MERRY CHRISTMAS」の文字で覆われています。ミディアムショットです。 | A Christmas-themed image of a beautiful young woman with a pure and alluring charm is generated, with her face remaining unchanged. Her loose double braids are tied low (adorned with colorful fabric pom-poms), exuding a youthful charm and innocent eyes. She wears a Christmas tree-shaped hair accessory, with a small cone-shaped Christmas tree neatly fixed on her head, topped with a golden five-pointed star. The tree trunk is decorated with colorful lights, golden bells, bows, and small red, blue, and gold pom-poms—a delicate and full arrangement. Her fair skin is smooth and delicate, like jade. A pure and alluring hazy filter is applied, and reddish-brown eyeshadow is naturally blended. She holds a Santa Claus doll in both hands, radiating Christmas spirit. Her eyes and expression convey a festive feeling, and she tilts her head slightly. Playful and charming poses, a perfect blend of cuteness and sexiness, creating a striking contrast; slightly tousled hair blends naturally with the Christmas tree atop her head; she wears a soft, fluffy red top; the warm white background, studio soft lighting, low contrast, low saturation, delicate film grain, slight chromatic aberration, soft film glow, warm and healing atmosphere, unique perspective, unconventional composition, 70mm film portrait style green graffiti outline of the figure, with various cute Christmas graffiti elements around the outline, full of childlike fun and a hand-drawn collage feel. The figure's outline is surrounded by fluorescent red, green, and gold dotted lines, covered with the cute "MERRY CHRISTMAS" lettering, in a medium shot. | 生成圣诞节主题,一位纯欲气质的美少女,图中人脸不变。松散的双麻花辫松散低扎(麻花辫上有布艺彩球装饰),少女气质,无辜眼神,头戴圣诞树造型发饰,小型锥形圣诞树整齐地固定在头顶,顶部是金色五角星,树身装饰着彩色灯串、金色铃铛、蝴蝶结、红蓝金小球,布置精致饱满;冷白皮,白嫩嫩的皮肤如琼玉般嫩滑,纯欲朦胧滤镜,红棕系眼影自然晕染,双手拿着圣诞老人玩偶,圣诞氛围拉满,庆祝感眼神和表情,轻轻歪头,俏皮又好看的动作,可爱与性感并存,反差;蓬松微乱发丝与头顶圣诞树自然融合,穿毛绒红色上衣,质感柔软蓬松;暖白背景、棚拍柔光、低对比度、低饱和度、细腻胶片颗粒、轻微色散光晕、胶片柔光感、温暖治愈氛围、独特视角,非常规构图,70mm胶片人像风格绿色涂鸦描边人物轮廓,描边周围空白处还有各种圣诞节元素的可爱涂鸦,充满童趣和圣诞氛围的手绘拼贴感。人物轮廓荧光红绿金色虚线波点包裹,写满了“MERRY CHRISTMAS”可爱字体,中景 |

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 4コマ画像を作成します。要件:キャラクター:参考画像を4つのコマに分割し、それぞれ異なる動作と表情を表現します。左上:両手を頭上に上げて「V」サインを作り、目を大きく見開き、口を開け、遊び心があり、少し驚いたような表情をしています。右上:両手を頬に当て、目を少し閉じ、唇を突き出し、頬を紅潮させ、可愛らしく愛嬌のある表情を表現しています。左下:頭を少し傾け、片目をウィンクし、舌を突き出し、片手で「V」サインを作り、遊び心があり、いたずらっぽい表情を表現しています。右下:腕を胸の前で組み、眉を少しひそめ、唇を突き出し、少し傲慢な表情を表現しています。服装:参考画像と同じままにしてください。背景とスタイル:ズートピアなどの可愛い漫画の要素を散りばめたカラフルな背景で、全体的にアニメ/マンガ風に仕上げています。画像は鮮やかで、甘く、心を落ち着かせるもので、それぞれの小さな画像は繊細な漫画の縁取りで飾られ、子供らしい楽しさに満ちています。 | Generate a four-panel image. Requirements: Characters: The reference image should be divided into four frames, each showing a different action and expression. Top Left: Hands raised above head making a double "V" sign, eyes wide open, mouth open, revealing a playful and slightly startled expression. Top Right: Hands cupping cheeks, eyes slightly closed, lips pouting, cheeks flushed, conveying a cute and charming look. Bottom Left: Head slightly tilted, one eye winking, tongue sticking out, one hand making a "V" sign, playful and mischievous. Bottom Right: Arms crossed in front of chest, brows slightly furrowed, lips pouting, conveying a slightly arrogant expression. Clothing: Remain unchanged from the reference image. Background and Style: A colorful background filled with cute cartoon elements such as Zootopia, with an overall anime/manga style. The images are vibrant, sweet, and soothing, with each small image decorated with delicate cartoon borders, full of childlike fun. | 生成一张四宫格图片。以下要求:人物:参考图人物分四个画面呈现不同动作表情。左上:双手举过头顶比双“V”,眼睛大睁、嘴巴张开,露出惊牙活泼的神态。右上:双手托住脸颊,双眼微闭、嘴巴嘟起,脸颊带红晕,呈现可爱娇憨感。左下:头微侧,一只眼睛wink,舌头吐出,单手比“V”,俏皮搞怪。右下:双臂交叉在胸前,眉头微皱、嘴巴嘟起,呈现小傲娇神态。服饰:根据参考图不变。背景与风格:充满疯狂动物城等可爱卡通元素的彩色背景,整体为二次元动漫风格,画面色彩鲜艳、风格甜美治愈,每幅小图都有精致的卡通边框装饰,充满童趣感。 |

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 実在の人物が、それに対応する漫画壁画とポーズをとっている縦長の3:4アスペクト比のシーン画像を生成します。アップロードした実写写真を、元の服装、髪型、メイクを維持したまま、画像の左側/前面に配置します。実在の人物の後ろの壁に、厚みのある質感のある仕上げと、大きな目と柔らかな顔立ちのアニメ風デザインを使用して、1:1スケールの漫画壁画を描きます。髪型、服装、イヤリングやネックレスなどのアクセサリーのディテールを、高い彩度とグラフィティ風の筆致で完全に再現します。壁にはカラフルなグラフィティハート、スマイリーフェイス、幾何学模様を、床には飛び散ったペンキなどの装飾的なディテールを追加します。壁画エリアには、「2026 Prosperity」などの漢字を、グラフィティの美学に合わせたフォントスタイルで組み込みます。実際の人物と壁画の比率と角度が自然に溶け合い、照明の方向が一貫していてシーンのロジックに従っており、全体的な配色が一貫していることを確認して、鮮明で一貫性があり、視覚的に調和のとれた効果を表現します。 | Generate a vertical 3:4 aspect ratio scene image of a real person posing with their corresponding cartoon mural: Place the uploaded real-life photo, preserving the original clothing, hairstyle, and makeup, on the left/front of the image. Paint a 1:1 scale cartoon mural on the wall behind the real person, using a thick, textured finish and an anime-style design with large eyes and soft facial features. Completely replicate the hairstyle, clothing, and accessory details such as earrings and necklaces, with high color saturation and graffiti-like brushstrokes. Add colorful graffiti hearts, smiley faces, and geometric patterns to the wall, and decorative details like splattered paint on the floor. Incorporate Chinese characters such as "2026 Prosperity" into the mural area, with a font style that matches graffiti aesthetics. Ensure the proportions and angles of the real person and the mural blend naturally, the lighting direction is consistent and follows scene logic, and the overall color scheme remains consistent, presenting a vivid, coherent, and visually harmonious effect. | 生成竖版3:4画面比例的“真人与其对应卡通壁画合影”场景图像:将上传的真实人物照片以原样保留服装、发型、妆容置于画面左侧/前方。在真人背后墙面绘制1:1对应卡通壁画,厚涂质感且采用动漫风格大眼、柔和轮廓五官,完整复刻发型、服装及配饰细节如耳环、项链等,色彩饱和度高并带有涂鸦式笔触效果。墙面添加彩色涂鸦爱心、笑脸、几何图案元素,地面点缀飞溅颜料装饰细节,壁画区域融入如“2026发财”的中文字元素,字体风格契合涂鸦美学。确保真人与壁画比例、角度自然衔接,光照方向统一符合场景逻辑,保持整体色彩风格一致,呈现生动、连贯且视觉和谐效果 |

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 不規則な形状で平らな、ピクセル化されたパーラービーズを押さえた手の写真を生成します。パーラービーズは、参照画像をピクセル化した漫画風の画像です。ビーズは平らで突起がなく、参照画像の主要な特徴を維持しています。背景は作業台の表面です。 | Generate a photo of a hand holding a pressed, irregularly shaped, flat pixelated Perler bead. The Perler bead is a pixelated, cartoonish image of the reference image. The bead is flat with no protrusions, maintaining the main features of the reference image. The background is a workbench surface. | 生成一个手拿着压制好的边缘不规则的平面像素拼豆成品照片,拼豆的内容是参考图中的像素Q版形象,拼豆扁平没有凸起,保持参考图主体特征不变,背景是工作台台面 |

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 二人は一緒に「シーッ」というジェスチャーをします。 | The two people make a "shh" gesture together. | 两个人,一起做一个“嘘”的手势。 |

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 女性が子猫を抱いています。 | The girl is holding the kitten. | 女生抱着这只小猫。 |
マージ済み LoRa


| 日本語 | 英語 | 中国語 |
|---|---|---|
| ソフトライト。ソフトライトを使用して画像を再照明します。 | Soft light, using soft light to relight the image. | 柔光,使用柔和光线对图片进行重新照明 |

| 日本語 | 英語 | 中国語 |
|---|---|---|
| カメラをパンしてテーブルトップのクローズアップを撮影します。 | Pan the camera to a close-up of the tabletop. | 将镜头平移至桌面特写 |

| 日本語 | 英語 | 中国語 |
|---|---|---|
| カメラを左に30度回転させます。 | Rotate the camera 30 degrees to the left. | 将镜头向左旋转30度 |
Industry Design

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 写真の車を灰色に変更します。 | Change the car in the picture to gray. | 把图中的汽车变为灰色 |

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 写真の5kgの重りからハンドルを取り外します。 | Remove the handle from the 5kg weight in the picture. | 把图片中5kg砝码的拉提手部分去掉 |

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 図 1 のテーブルと椅子のパネルを、図 2 の明るい色の木材に置き換えます。 | Replace the table and chair panels in image1 with the light-colored wood material in image2. | 把图1中的桌椅面板替换成图2的浅色木材质 |

| 日本語 | 英語 | 中国語 |
|---|---|---|
| 図 1 の椅子の素材を図 2 の布地に置き換えます。 | Replace the chair material in image1 with the fabric in image2. | 把图1中的椅子材料替换成图2的布料 |
Geometric Reasoning
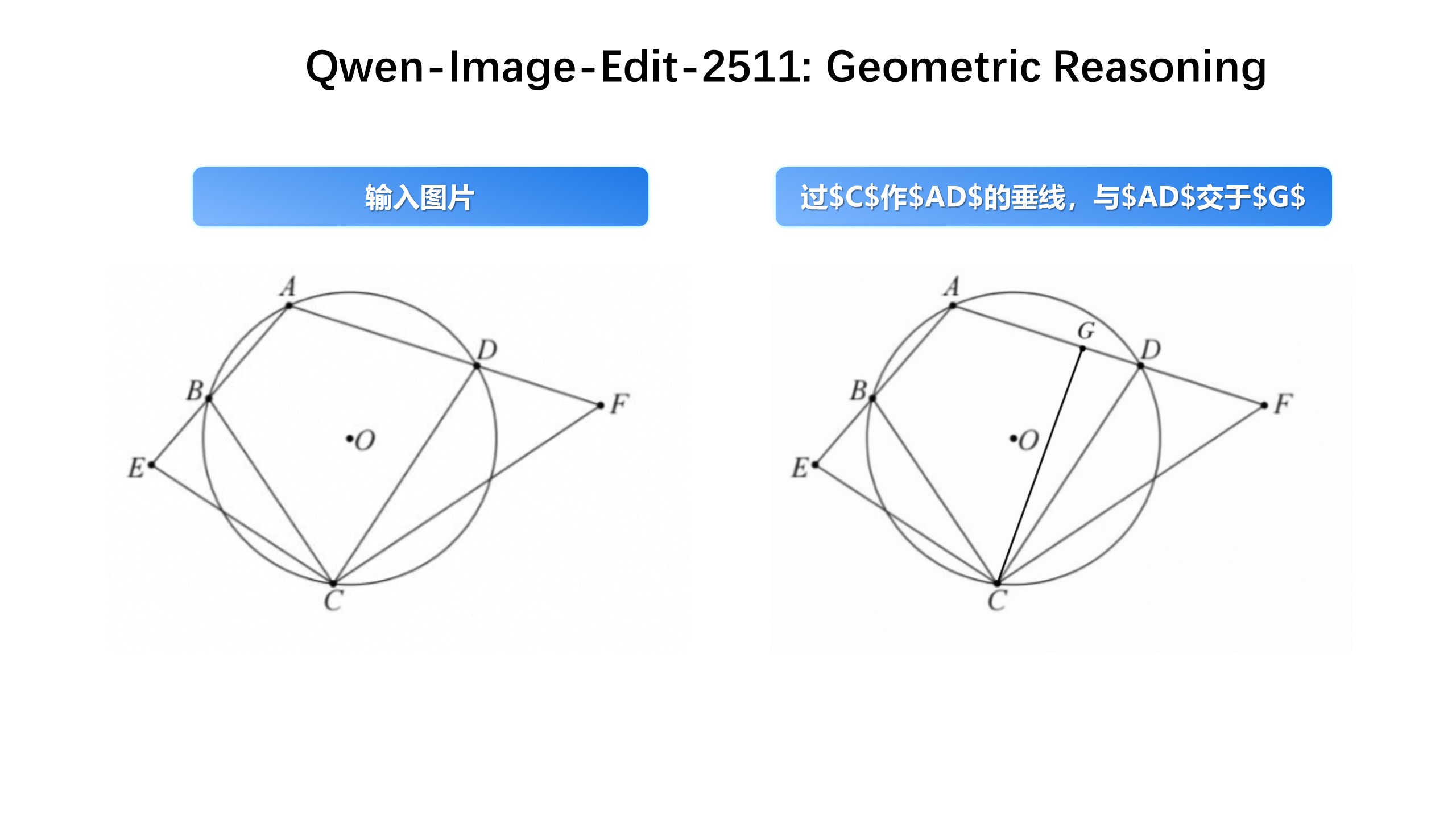
| 日本語 | 英語 | 中国語 |
|---|---|---|
| 点 $C$ から $AD$ へ垂線を引き、点 $G$ で $AD$ と交差します。 | Draw a perpendicular line from point $C$ to $AD$, intersecting $AD$ at point $G$. | 過 $C$ 作 $AD$的垂線,與 $AD$ 交於 $G$ |
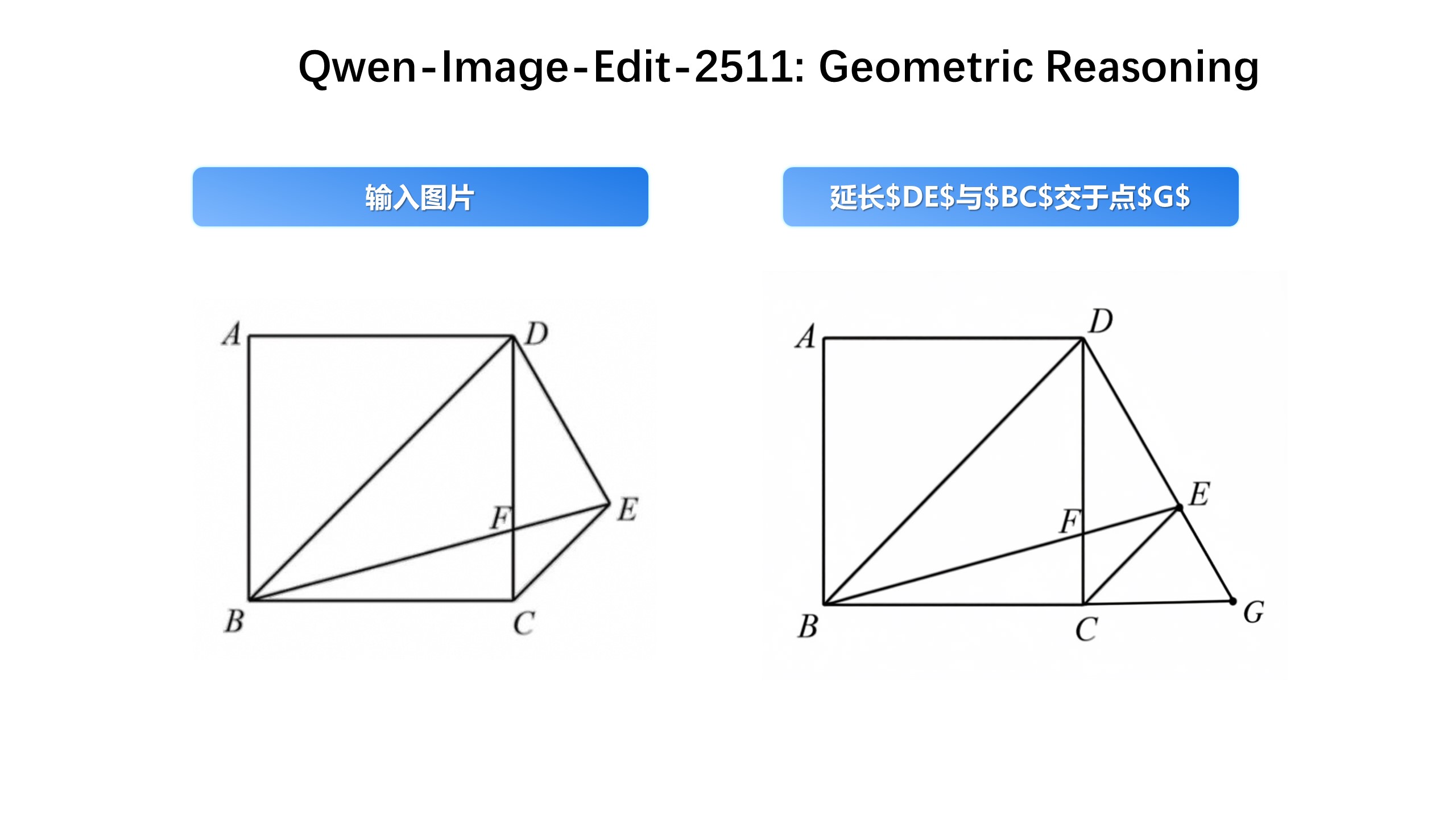
| 日本語 | 英語 | 中国語 |
|---|---|---|
| $DE$を延長して点$G$で$BC$と交差させます。 | Extend $DE$ to intersect $BC$ at point $G$. | 延长 $DE$ 与 $BC$ 交于点 $G$ |
Dynamic Prompt
ComfyUI はデフォルトで Dynamic Prompt が使える。プロンプトに {A|B|C} と入力すると、実行するごとに A, B, C がランダムに選択される。
年齢
child, girl, woman, mature woman の4段階制御。years old 指定だと若干変化がつけられる。

年齢の変化
画風
- in realistic photography style, high detail
- cinematic high-fashion lighting
- in sketch drawing style
- black and white outline
- oil painting
- watercolor
- charcoal drawing
- cartoon/anime style
- pixel art
- vector illustration
- Renaissance painting
- Art Deco style
- Japanese ukiyo-e
- Studio Ghibli art style
- Kyoto Animation art style
カメラアングル変更 LoRa
Qwen Image Edit 2511 はこの LoRa がマージ済みなので、LoRa を使用する必要はない。
dx8152/Qwen-Edit-2509-Multiple-angles
fal/Qwen-Image-Edit-2511-Multiple-Angles-LoRa
この LoRa なしでもカメラアングル変更は可能だが、この LoRa を使うと精度が向上する。45 度だけでなく任意の角度で回転可能。
プロンプト
| 日本語 | 英語 | 中国語 |
|---|---|---|
| カメラを前に移動 | Move the camera forward. | 将镜头向前移动 |
| カメラを左に移動 | Move the camera left. | 将镜头向左移动 |
| カメラを下に移動 | Move the camera down. | 将镜头向下移动 |
| カメラを前に移動しテーブルの下に移動 | Move the camera forward to under the table. | 将镜头向前移动至桌子下 |
| カメラを 45 度左に回転 | Rotate the camera 45 degrees to the left. | 将镜头向左旋转45度 |
| カメラを 45 度右に回転 | Rotate the camera 45 degrees to the right. | 将镜头向右旋转45度 |
| 俯瞰視点に変更 | Turn the camera to a top-down view. | 将镜头转为俯视 |
| 広角に変更 | Turn the camera to a wide-angle lens. | 将镜头转为广角镜头 |
| クローズアップ | Turn the camera to a close-up. | 将镜头转为特写镜头 |
視点の変更をプロンプト化するノード
jtydhr88/ComfyUI-qwenmultiangle
SamLiu1000/ComfyUI_Rabbit-Camera-Perspective
Mask Editor
画像を読み込むノードの画像を右クリックして「Open in MaskEditor」で簡易ペイント機能が使える。以下の機能がある。編集レイヤーの切り替えは左のタブから行う。右下のレイヤーをクリックしても編集レイヤーは変更できない。
- 画像の左右反転
- マスク編集
- ペイントレイヤー編集(1枚のみ)
作例
設定は 4 step 高速化 LoRa・CFG 1
T2I・Qwen Image Q3_K_M

Qwen Image
The illustration of a blonde girl wearing a blue kimono. She stands indoors in a Japanese house.
I2I・Qwen Image Edit Q4_K_M

Qwen Image Edit
Change the color of her kimono to red and change her hair color to brown and change her eye color to green. Change her mouth to open and smile. Change her pose to make a heart with her hands in front of her chest.

# person There are three girls in a room. - left: short red hair and blue eyes. She is sitting on a stool holding a card with the word "左" written on it. - middle: long silver hair and red eyes. She is standing and holding a card with the word "中" written on it in both hands. - right: medium brown hair and green eyes. She is sitting on a stool and holding a card with the word "右" written on it. # background potted plants and a kitchen. # style Anime style.
markdown で構造化されたプロンプトも理解できる。

Z Image Turbo
Qwen Image Edit 2509
There is a piece of paper with "あいうえおアイウエオ かきくけこカキクケコ さしすせそサシスセソ たちつてとタチツテト なにぬねのナニヌネノ はひふへほハヒフヘホ まみむめもマミムメモ やゆよヤユヨ らりるれろラリルレロ わをんワヲン" written on it.
ひらがな片仮名は壊滅的。Z Image Turbo はひらがなや片仮名も少々描ける。

A girl holding a M4 assault rifle in her right hand, is stainding in the apocalypse city. She is looking at side. She is wearing a hooded jacket, a skirt and boots with a backpack. # background The background is a dark, gradient snowing gray. Draw following objects: - disfigured road - disfigured buildings - many broken cars, tanks - debris and rubble - an traffic light is black out # style This is a digital painting in an anime but semi-realistic style. Dramatic cinematic lighting and mysterious, contemplative mood. Draw the M4 assault rifle in detail.

The illustration of a chibi girl sitting in a chair eating a piece of pizza. She is saying "This is fine!" in a speech bubble. There is a table and a window in the indoor room.

Two girls are embracing each other while taking a selfie in the noon park.The left girl has blonde hair with a hair clip and blue eyes and closed mouth. The right girl has black long hair and red eyes and open mouth. They are wearing school uniforms and looking at smartphone. Kyoto Animation art style.

The illustration of the full length portrait of a standing girl with her arms at sides on a pure white background. She has large breasts. She is wearing a navy blazer, white collared shirt, a red string ribbon, white socks, dark brown loafers and a gingham pleated mini skirt. Pure white background.

Qwen Image Edit 2511 Q6_K 8 step LoRa
Create her reference sheet on a pure white background. Draw following four different angles: - front view on the far left - left view that facing to the left with her entire body on the middle left - right view that facing to the right with her entire body on the middle right - back view on the far right

Qwen Image Edit
元画像をテキストエンコーダーと K サンプラーの両方に入力
Kサンプラーのノイズ除去 0.8
プロンプト:Remove the hair red and black ornament on her upper head.
Remove the waist red and black ornament on her left and right waist.
Do not change any irrelevant parts.

Qwen Image Edit
ノイズ除去:0.8
プロンプト:Remove all text from the image, e.g., "SAMPLE" or "無断転載禁止."
Do not change any irrelevant parts.

Qwen Image Edit 2509
ノイズ除去:1
プロンプト:The woman in Figure 1 is lying in the position shown in Figure 2.

Qwen Image Edit 2509
プロンプト:Upscale the image 1 and increase the sharpness. Add details. Keep the original style.
テキストエンコーダーにもベースにも bicubic で拡大した画像を入力し、kSampler の denoise は 0.9
アニメの場合は Sharp anime style. を入れるのもよい。
手の編集
手がうまく描けない最大の理由は解像度の不足だ。解像度が不足している場合、Qwen Image Edit や Nano Banana でも直せない。
このような修正は Detailer を使ったワークフローが有効だ。
- 手の部分を検出
- 手の部分を切り出し
- アップスケール
- i2i
- 縮小して張り付け
解像度が足りている場合のプロンプト
腕の位置ごと変更させたり、手のポーズを変更する方法がある。
雑に指定する場合
右手と向かって右側の手をよく間違えるので、画面位置で手を指定すると間違いが少ない。
- 画面右の人の手を開く
- 左の人物の手を握る
- ピースする
手全体を描きなおさせる場合
Fill the red area in image1 and draw a hand. Don't change the other area.
指1本のみ描き直させる場合
Fill the red area in image1 and draw only a finger. Don't change the other area.