Stable Diffusion のファインチューンの Tips
LoRA はLoRA の学習方法へ移動した。
LoRA 以外の情報(Hypernetwork や Textual Inversion、Dreambooth)はStable Diffusion の古い情報へ移動した。
目次
U-Net の学習
わかりやすい解説として「U-Net は画像のデノイズを行う」という説明がされるが、これは正確には間違いだ。U-Net は除去すべきノイズを出力する。
学習のプロセスは以下のようになる。
- ランダムにタイムステップ t ∈ [0, 1000]を選ぶ
- 教師画像にタイムステップ t に対応するノイズを付与する
- U-Net にノイズを付与した教師画像とタイムステップ t とコンテクスト(embedding 化したキャプション)を入力
- U-Net が除去すべきノイズを出力する
- 付与したノイズと U-Net が出力したノイズとの差分から平均二乗誤差(MSE)を計算する
- 差分を逆伝播して学習する
タイムステップはノイズの量をきめる。0 が教師画像そのもので、1000 が純粋なノイズ画像だ。
概要
2023 年8月現在 LoRA 一強の状況で、Textual Inversion・Hypernetwork・Dreambooth(正則化画像) はほとんど使われていない。
間違いやすいポイント
学習画像に2人以上人がいる
画風を学習させる場合には問題にならないが、キャラを学習させる場合には絶対にやってはいけない。
Danbooru タグの検査
キャプション方式
マルゼン式
マルゼン式はキャラに固有のタグを削除し、キャプションにトリガーワードを追加する。例えば white long hair や star hair ornament などのタグを削除する。つまりトリガーワードに削除したタグの内容を覚えさせる方式。
マルゼン式のキャプションは以下の特徴がある。
メリット
- 生成時のプロンプトを節約できる
- 削除したタグの内容を保護できる
デメリット
- プロンプトによる指示が難しくなる(特に服のタグを削除した場合は脱がしにくくなる)
- 手作業なので時間がかかる
キャラ固有のタグを削除しない方法
画風学習のときに使われる、キャラ固有のタグを削除しない方法は以下の特徴がある。
メリット
- タグの検査が楽
- プロンプトによる指示が効きやすい(脱がしやすい)
デメリット
- キャラの再現に長いプロンプトが必要になる
- タグの内容が上書きされる
- プロンプトが 75 トークンを超えると制御するのが難しくなる
無関係なタグや、重複しているタグの削除
たとえば、hair ornament, star hair ornament, star \(symbol\) を star hair ornament でまとめるなど。
lollipop, ..., holding のような曖昧なタグは holding lollipop のように分かりやすくする。これは間のカンマがなくなることで holding と lollipop の結びつきが強くなる。
looking at viewer, looking at another, looking at away のような視線を指定するタグはよく間違うので手動で修正する。
blurry background があると、画像がぼける事があるので削除した方がいいかもしれない。
画風の定義
全身画像だけで画風を学習させようとすると細部がつぶれる。大抵は顔と髪で画風を判断しているので、顔のアップ画像やバストアップの画像があった方がいい。
服も学習させる場合は、頭をクロップした画像を用意して、head out of frame タグを付ける方法もある。
複数のアスペクト比で学習させる
1:1のアスペクト比で全身画像を学習させようとすると、背景の方を学習してしまう。なぜなら背景の方が面積が広いからだ。これは白背景にしても解決できない。
なので全身画像も学習させたい場合は、アスペクト比ごとに学習を分ける必要がある。
CLIP Skip は任意
固定した CLIP Skip しか使わないならその固定値で学習するのは問題ない。ただしほかの値で上手く動かない可能性が高い。
VAE は外しても外さなくてもいい
vae は学習に影響を与える。VAE を外す場合は ckpt と同じディレクトリにある .vae.pt をリネームするか、別のディレクトリに移動する。ただし常に VAE を有効にした状態で使うなら VAE を外す必要はない。
プレビューの固定
train タブの train で Read parameters (prompt, etc...) from txt2img tab when making previews にチェックを入れると、任意のプロンプトやパラメータでプレビューできる。特にシードの固定は絶対にしておきたい。
良くない兆候
プレビュー画像に以下の兆候が現れたら、学習率を下げるか学習を終了させた方がいいかもしれない。
- プレビュー画像にノイズが乗る
- プレビュー画像の背景がシンプルになっていく
- プレビュー画像がモノクロになる
崩壊した後に持ち直すのを繰り返す
崩壊した後に持ち直すのは局所的最適解から抜け出して、最適解に近づいている証拠だ。崩壊した後にいつまでも持ち直さない場合は失敗している。
学習率と局所的最適解
ステップ数が増えるごとに学習率を下げる方法(たとえば 5e-6:5000, 5e-7)は、局所的最適解から抜け出せない。早いうちに発散してしまった場合は、学習率を下げて学習を再開させる。
局所的最適解を抜け出す方法として焼きなまし法がある。ただし運が悪いと悪化する。
MonkeyPath の Cosine Annealing は焼きなまし法に対応したスケジューラーが使える。
ステップ数より epoch(エポック)が重要
画像1枚を学習したら1ステップで、用意した学習画像を1周したとき1 epoch。
Loss の監視は無意味
Loss の大小は学習時に加えるノイズ量で決まるため見ても意味がない。学習の成否は実際にランダムシードで画像を生成してみないとわからない。
Investigating the training loss #4043
Loss はデノイザよって予測されたノイズの二乗誤差の期待値だ。問題はそれが推定値にすぎないこととサンプル空間が巨大なこととだ。サンプル空間の乱数は、潜在空間のノイズ画像とノイズレベルとの影響が大きい。サンプル空間が巨大なので乱数で Loss が上下してしまう。
previous_mean_loss
hypernetwork の csv に出力される Loss は previous_mean_loss の値だ。これは各学習画像の最新の Loss の平均だ。たとえば学習画像2枚で 100 ステップごとにログを書き込む場合、計算に使う Loss は2つだけだ。100 ステップの Loss の平均ではない。
hypernetwork の学習時に WebUI 上に表示される Loss もこの previous_mean_loss の値だ。
Textual inversion の場合は直近 32 ステップの Loss の平均だ。
Loss-タイムステップグラフ
以下の図の縦軸は Loss、横軸はタイムステップ。横軸はステップ数ではない。タイムステップは付与するノイズ量をきめる。つまりタイムステップが大きいと、画像に加えるノイズが最初から少ない。
以下の図を見ればわかるように、Loss は学習が進むごとに小さくなるのではなく、引いたタイムステップで決まる。
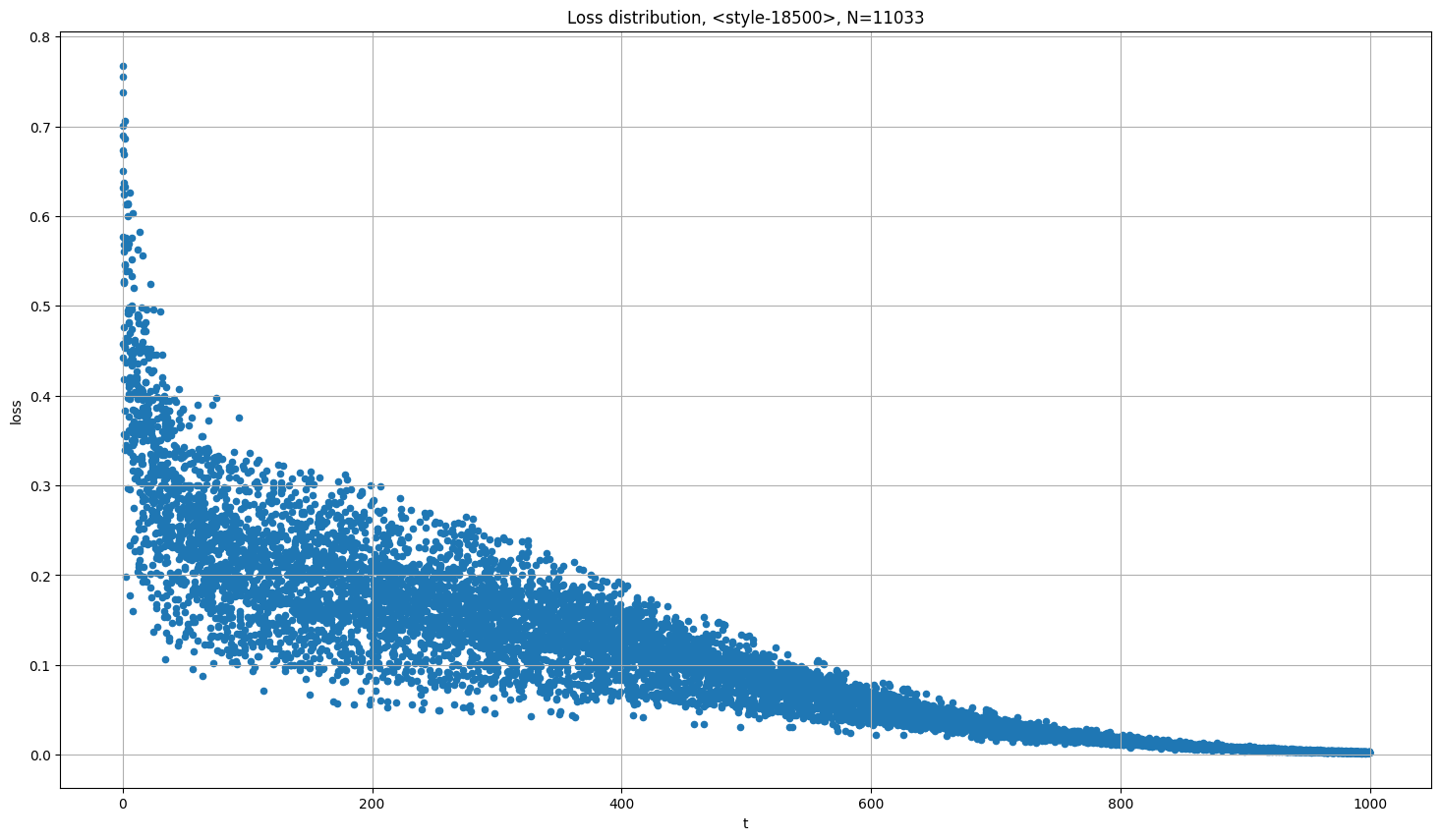
付与するノイズ量が多いほど Loss も大きい
出典:https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/4043
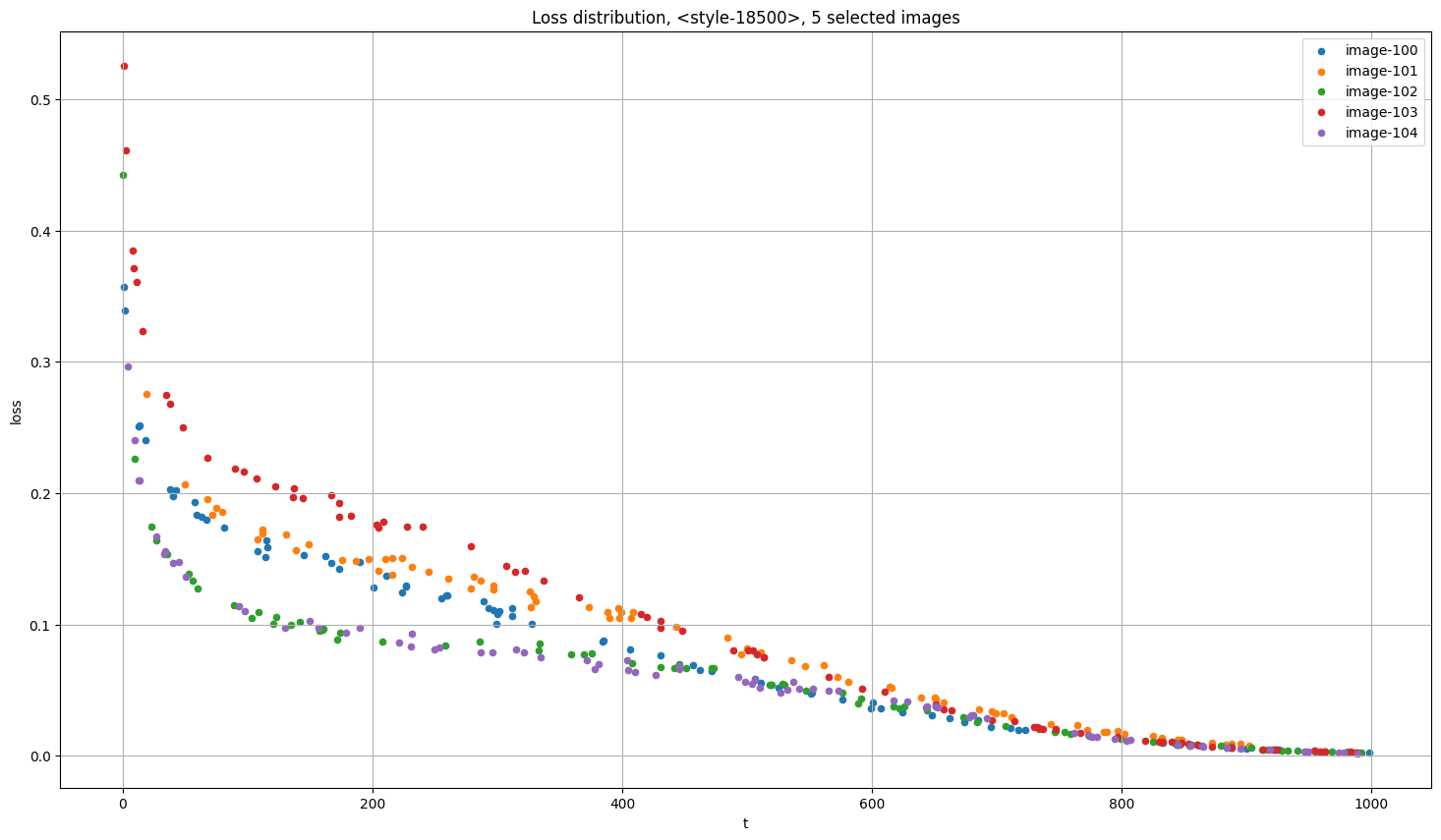
学習画像ごとの Loss のプロット
出典:https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/4043
Loss が大きくなる2大原因は、付与するノイズ量が多いか、間違ったキャプションがついているかだ。Loss の大きい画像の内容が多く学習されるので、Loss の大きい画像には特別な注意を払う価値がある。背景付きの画像は Loss が大きくなる。背景面積の広い画像は背景を学習しているのと変わらない。
学習画像ごとに Loss を出力する
以下のようにソースコードを修正する。
dataset.py
self.filename = [entry.filename for entry in data]
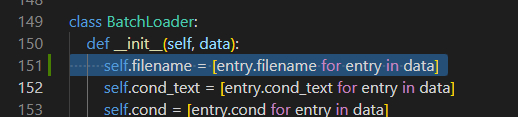
dataset.py
hypernetwork.py
with open(log_directory + '/loss.csv', 'a', newline="") as f: csv.writer(f).writerow([batch.filename[0], loss.item()])
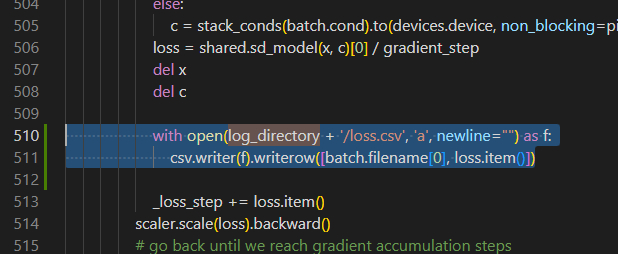
hypernetwork.py
学習の失敗
発散
発散はプレビューがノイズ画像になるか、溶けるかするので分かりやすい。
過学習
プレビューではうまくいっているが実際に生成してみると上手くいかない、つまり汎用性がない状態。過学習かどうかを判断するには、一度学習を止めて(もしくは別のマシンで)ランダムシードで何枚か生成してみるしかない。
プレビューをランダムシードにしても過学習かどうかはわからない。なぜならランダムシードでプレビューするとシードが悪いのか学習が悪いのかの切り分けができないからだ。
過学習であっても Hypernetwork strength を下げれば普通に使える場合もある。
キャプションファイルに名前を入れる
画風の場合
モデルがそのアーティスト名を認識していなくてもキャプションファイルにアーティスト名を入れるのは意味がある。学習後に Hypernetwork を適用して画像を作成する際に、プロンプトにそのアーティスト名を入れると画風がより固定される。
キャラ・オブジェクトの場合
キャラ・オブジェクトの場合でも、キャプションファイルにキャラ・オブジェクト名を入れる。学習後に Hypernetwork を適用して画像を作成する際に、プロンプトにその名前を入れると学習させたキャラ・オブジェクトを呼び出しやすくなる。
シェルで追記
キャプションファイルのあるフォルダに移動して以下のコマンドでファイルの末尾に任意の文字を追記できる。
# Powershell 末尾追記
ls *.txt|%{Write-Output ", ここに追記したいタグを入れる" | Add-Content -NoNewLine "$_"}# Bash 末尾追記 for i in *.txt; do echo -n ", ここに追記したいタグを入れる" >> "$i"; done
ファイル先頭の場合は以下のようになる。
# Powershell 先頭追記
ls *.txt|%{echo "ここに追記したいタグを入れる, $(Get-Content -Path $_ -Raw -Encoding Default)" | Out-File -FilePath $_ -NoNewLine -Encoding Default}# Bash 先頭追記 for i in *.txt; do echo -n "ここに追記したいタグを入れる, $(cat $i)" > "$i"; done
Preprocess(前処理)
Train タブの Preprocess image は画像を加工して、別のディレクトリに書き出す機能。
- Source directory:画像の入ったディレクトリ
- Destination directory:結果を出力するディレクトリ
- Flip:左右反転した画像を出力する(私[dskjal]の見解では、左右非対称な特徴[髪型や服]を持つキャラを学習させたい場合は左右反転は使うべきではない)
- Split into two:縦長や横長の画像の短辺を望ましい解像度に合うようにリサイズし、可能な限り交差する画像を2つ切り出す
- Auto focal point crop:顔・輪郭・複雑さなどをもとにクロップする場所を自動で決める
- Add caption:学習画像名にキャプションを含めるために BLIP モデルを使う
- Use deepbooru for caption:学習画像と同じ名前のテキストファイルに Deepdanbooru を使ってタグを出力する
- settings タブの Training で Shuffleing tags by ',' when create texts. にチェックを入れるとタグをシャッフルしてくれる
Auto focal point crop
- Focal point face weight:影響率 58%:顔のある方向にクロップ位置を移動させる
- Focal point entropy weight:影響率 10%:複雑な場所にクロップ位置を移動させる
- Focal point edges weight:影響率 32%:輪郭抽出できる場所(コントラストが高かったり、フォーカスの当たっている場所)にクロップ位置を移動させる
タグ編集 Extension
CLIP+MLP Aesthetic Score Predictor
「いいね」されやすさをスコアとして出力してくれる。
画像加工ツール
Train タブの Preprocess images
画像サイズの調整や、Split oversized images into two で簡単な切り出しができる。Hypernetwork で画風を学習させるだけなら Use deepbooru for caption の出力が無加工で使える。
切り出し
WAIFU SQUARELIZERは顔を認識して切り出してくれる。
XnConvert は画像を 512x512 にするときに便利。
アンシャープ
アップスケーラー
- PixSr4x - イラスト向け4倍超解像Windowsアプリケーション
- AUTOMATIC1111 の Extra タブの Batch Process タブ
背景の除去
iOS16 以降で背景を切り抜ける。
Windows ならペイント3Dのマジック選択が使える。
anime-segmentation
イラストの背景除去が得意。DEMO 版。
rembg
ImageMagick
ImageMagick を使うと透過を白背景に変換できる。
Windows ではコマンドプロンプトから winget を使ってインストールできる。
winget install ImageMagick
Powershell からは使えないので cmd.exe から使う。
magick convert a.png -background white -flatten a.jpg
不要物の除去(Lama Cleaner)
画像に含まれる不要物を違和感なく完全削除できる無料ツール「Lama Cleaner」のインストール手順&使い方まとめ
物体検出
YOLOモデルを作る で ADetailer 等で使う物体検出モデルの訓練方法が解説されている。
学習テクニック
失敗するまで学習させる方法
Hypernetwork を学習するときに、学習率 0.000005(5e-6)からはじめて、失敗したら一度学習をストップさせる。次に学習させたものの中から上手くいっているものを選択して、より低い学習率(たとえば 0.0000005(5e-7))で学習を継続する方法がある。
Learning rate scheduling
Learning rate に以下のように入力すると、2,000 ステップまでは 5e-6、10,000 ステップまでは 5e-7、終了まで 5e-8 の学習率で学習する。
5e-6:2000, 5e-7:10000, 5e-8
焼きなまし法(annealing)
以下のように学習率を上げたり下げたりする。こうすることで局所的最適解から抜け出せる可能性がある。
5e-5:100, 5e-6:1500, 5e-7:2000, 5e-5:2100, 5e-7:3000, 5e-5:3100, 5e-7:4000, 5e-5:4100, 5e-7:5000, 5e-5:5100, 5e-7:6000, 5e-5:6100, 5e-7:7000, 5e-5:7100, 5e-7:8000, 5e-5:8100, 5e-7:9000, 5e-5:9100, 5e-7:10000, 5e-6:10100, 5e-8:11000, 5e-6:11100, 5e-8:12000, 5e-6:12100, 5e-8:13000, 5e-6:13100, 5e-8:14000, 5e-6:14100, 5e-8:15000, 5e-6:15100, 5e-8:16000, 5e-6:16100, 5e-8:17000, 5e-6:17100, 5e-8:18000, 5e-6:18100, 5e-8:19000, 5e-6:19100, 5e-8:20000
学習データ(Textual Inversion)
Train タブの Preprocess images の Use deepbooru for caption を使えば、キャプションをテキストファイルに書き出してくれる。画風を学習させる場合、この出力フォルダを Train の Dataset directory に指定するだけで準備は完了する。
Textual Inversion でキャラを学習させる場合のキャプション
学習させたい特徴は embedding 作成時の Initialization Text に入れる。学習してほしくない特徴(white background や close-up など)は画像のキャプションファイルに書く。
Textual Inversion の学習は雑に説明すると以下のようなステップになる。
- 指定されたプロンプト(styles.txt などで指定)で画像を生成する。
- 生成した画像と学習用画像とを比較して差異を計測
- 計測した差異を元に語のウェイトを調整。Hypernetwork の場合はプロンプト全体を調整
ここで重要なポイントは学習させたい特徴はキャプションに含めてはいけないということだ。言い換えるとキャプションに含めるのは学習してほしくない特徴。
たとえば白髪赤目センター分けショートヘアーの c1 というキャラの顔を学習させるとしよう。学習させたいキャプションは red eyes, white hair, parted bangs, short hair 。なのでこれを Initialization Text に入れる。すると c1 の初期特徴ベクトルは red eyes, white hair, parted bangs, short hair を合成したものになる。
そして画像のキャプションファイルに red eyes, white hair, parted bangs, short hair を含めてはいけない。なぜならそれらの特徴を c1 という語に関連付けさせたいからだ。
キャラを学習させる場合のタグ決定アルゴリズム
- 覚えさせたい特徴のタグをメモ帳などに列挙する
- Use deepbooru for caption で画像にキャプションをつける
- 2. の中で画像と無関係なタグを削除する
- 2. で付けたタグから 1. で列挙したタグを削除する
画風を学習させる場合のキャプション(Textual Inversion・Hypernet)
Use deepbooru for caption でキャプションをつけた後、画像と無関係なタグを除去するだけだ。
ディープラーニングチューニングプレイブック日本語版
その他の情報
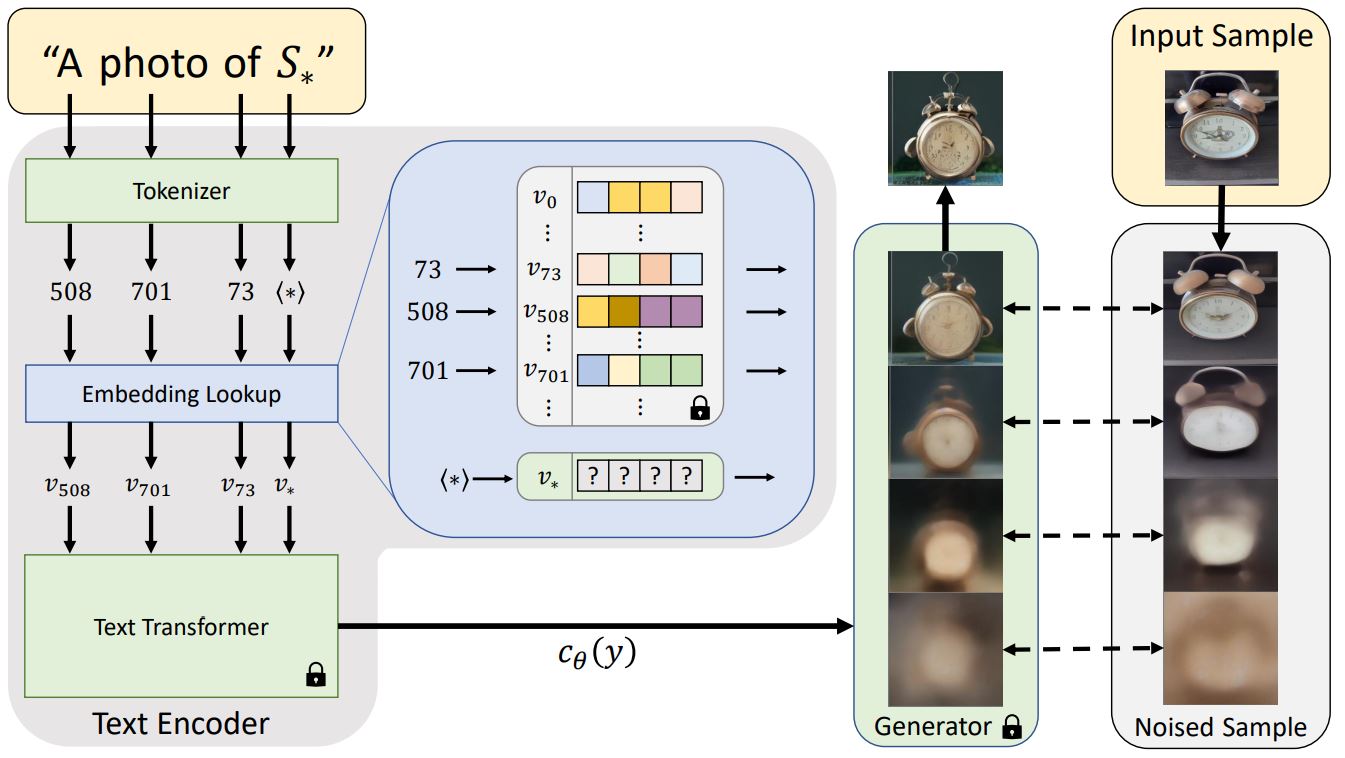
出典:An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion(https://textual-inversion.github.io/)
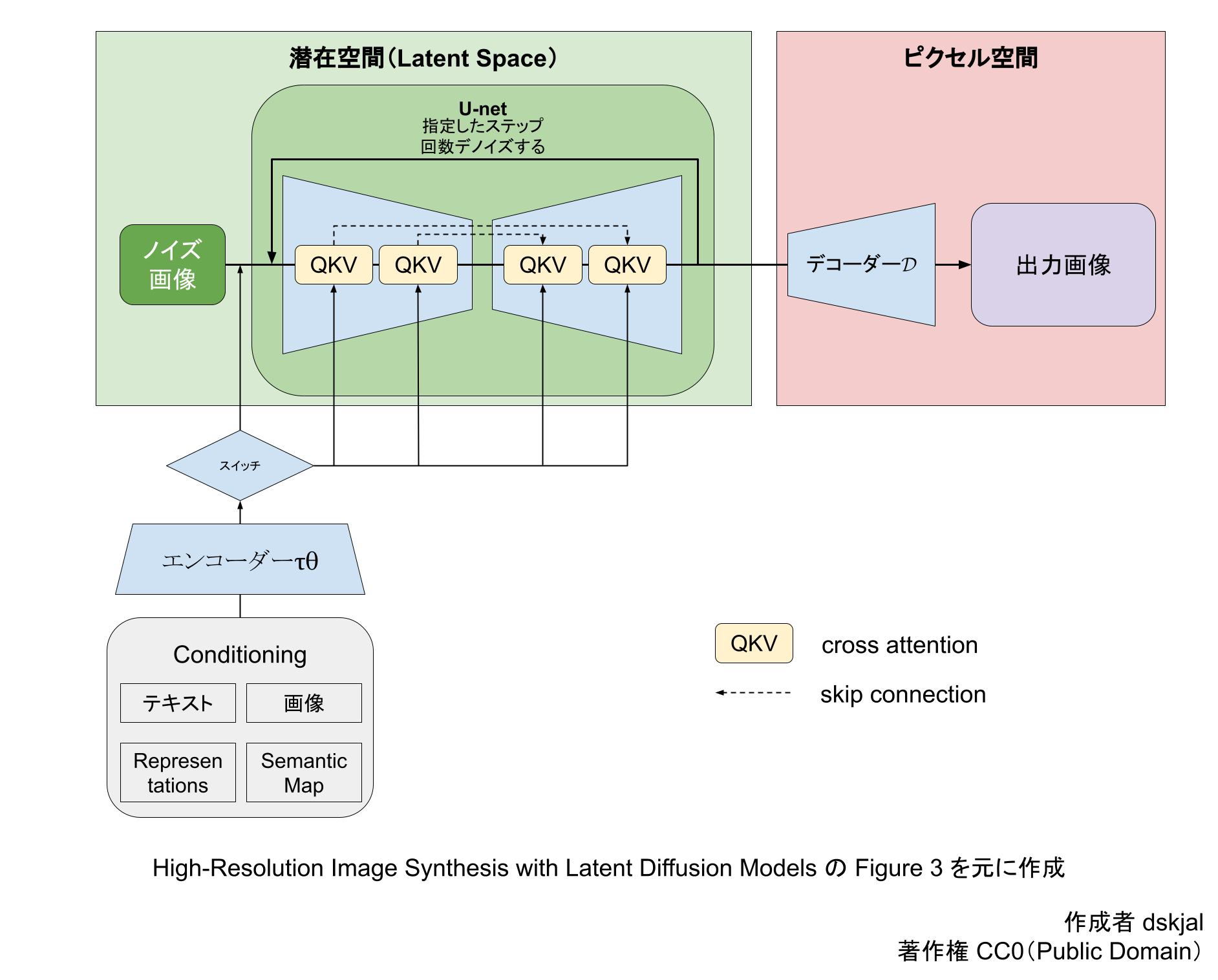
より詳細な図
#stablediffusion のモデル構成完全理解した!
— tomo-makes (@tomo_makes) September 25, 2022
という程ではないものの、曖昧な理解で気持ち悪かった「プロンプトがどのU-Netの層に生成の条件付けとして働くか」が、各層の構成と共に分かった。
PyTorchまだ慣れないので、Keras/TF実装のこれを読みました。https://t.co/heiIfkrP9n pic.twitter.com/BFPIhEHGot